浅谈pandas.cut与pandas.qcut的使用方法及区别
pandas.cut:
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False)
参数:
1. x,类array对象,且必须为一维,待切割的原形式
2. bins, 整数、序列尺度、或间隔索引。如果bins是一个整数,它定义了x宽度范围内的等宽面元数量,但是在这种情况下,x的范围在每个边上被延长1%,以保证包括x的最小值或最大值。如果bin是序列,它定义了允许非均匀bin宽度的bin边缘。在这种情况下没有x的范围的扩展。
3. right,布尔值。是否是左开右闭区间
4. labels,用作结果箱的标签。必须与结果箱相同长度。如果FALSE,只返回整数指标面元。
5. retbins,布尔值。是否返回面元
6. precision,整数。返回面元的小数点几位
7. include_lowest,布尔值。第一个区间的左端点是否包含
返回值:
若labels为False则返回整数填充的Categorical或数组或Series
若retbins为True还返回用浮点数填充的N维数组
demo:
>>> pd.cut(np.array([.2, 1.4, 2.5, 6.2, 9.7, 2.1]), 3, retbins=True) ... ([(0.19, 3.367], (0.19, 3.367], (0.19, 3.367], (3.367, 6.533], ... Categories (3, interval[float64]): [(0.19, 3.367] < (3.367, 6.533] ... ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ >>> pd.cut(np.array([.2, 1.4, 2.5, 6.2, 9.7, 2.1]), ... 3, labels=["good", "medium", "bad"]) ... [good, good, good, medium, bad, good] Categories (3, object): [good < medium < bad] ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ >>> pd.cut(np.ones(5), 4, labels=False) array([1, 1, 1, 1, 1])
pandas.qcut
pandas.qcut(x, q, labels=None, retbins=False, precision=3, duplicates='raise')
参数:
1.x
2.q,整数或分位数组成的数组。
3.labels,
4.retbins
5.precisoon
6.duplicates
结果中超过边界的值将会变成NA
demo:
>>> pd.qcut(range(5), 4) ... [(-0.001, 1.0], (-0.001, 1.0], (1.0, 2.0], (2.0, 3.0], (3.0, 4.0]] Categories (4, interval[float64]): [(-0.001, 1.0] < (1.0, 2.0] ... ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ >>> pd.qcut(range(5), 3, labels=["good", "medium", "bad"]) ... [good, good, medium, bad, bad] Categories (3, object): [good < medium < bad] ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ pd.qcut(range(5), 4, labels=False) array([0, 0, 1, 2, 3])
补充拓展:解决 Python 中 qcut() 运行报错: Bin edges must be unique和drop duplicate edges by setting 'duplicates' kwarg
本次纠错背景,来源于互金领域信用风控建模中的变量分箱处理。(附在文末)
解决 Python 中 qcut() 函数运行报错:
Bin edges must be unique和 You can drop duplicate edges by setting the ‘duplicates' kwarg
首先,报错如下:
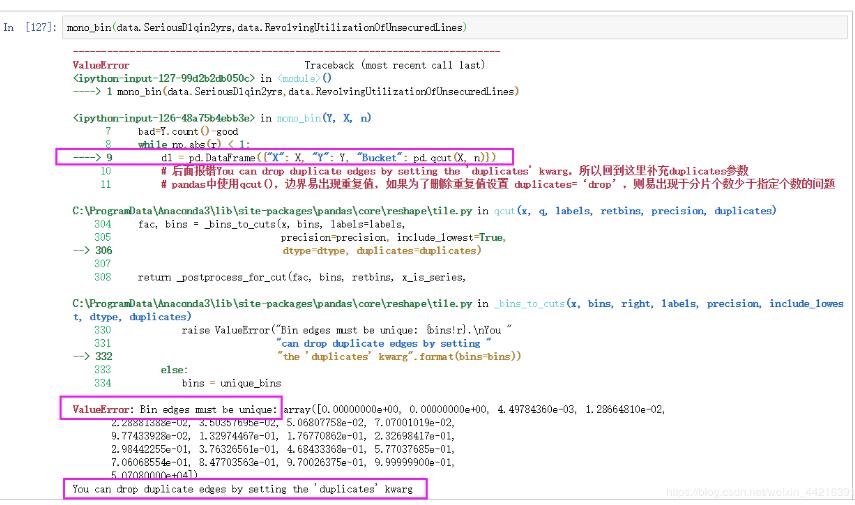
然后,在qcut() 函数中设置duplicates参数为“drop”(不能设置为“raise”),解决(如下)。
本次纠错背景,来源于互金领域信用风控建模中的变量分箱处理。如下:
# 五、变量选择 # 特征变量选择(排序)对于数据分析、机器学习从业者来说非常重要。 # 好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点、底层结构,这对进一步改善模型、算法都有着重要作用。 # 至于Python的变量选择代码实现可以参考结合Scikit-learn介绍几种常用的特征选择方法。 # 在本文中,我们采用信用评分模型的变量选择方法,通过WOE分析方法,即是通过比较指标分箱和对应分箱的违约概率来确定指标是否符合经济意义。 # 首先我们对变量进行离散化(分箱)处理。
# 5.1 分箱处理 # 变量分箱(binning)是对连续变量离散化(discretization)的一种称呼。 # 信用评分卡开发中一般有常用的等距分段、等深分段、最优分段。 # 其中等距分段(Equval length intervals)是指分段的区间是一致的,比如年龄以十年作为一个分段; # 等深分段(Equal frequency intervals)是先确定分段数量,然后令每个分段中数据数量大致相等; # 最优分段(Optimal Binning)又叫监督离散化(supervised discretizaion),使用递归划分(Recursive Partitioning)将连续变量分为分段,背后是一种基于条件推断查找较佳分组的算法。
# 我们首先选择对连续变量进行最优分段,在连续变量的分布不满足最优分段的要求时,再考虑对连续变量进行等距分段。最优分箱的代码如下:
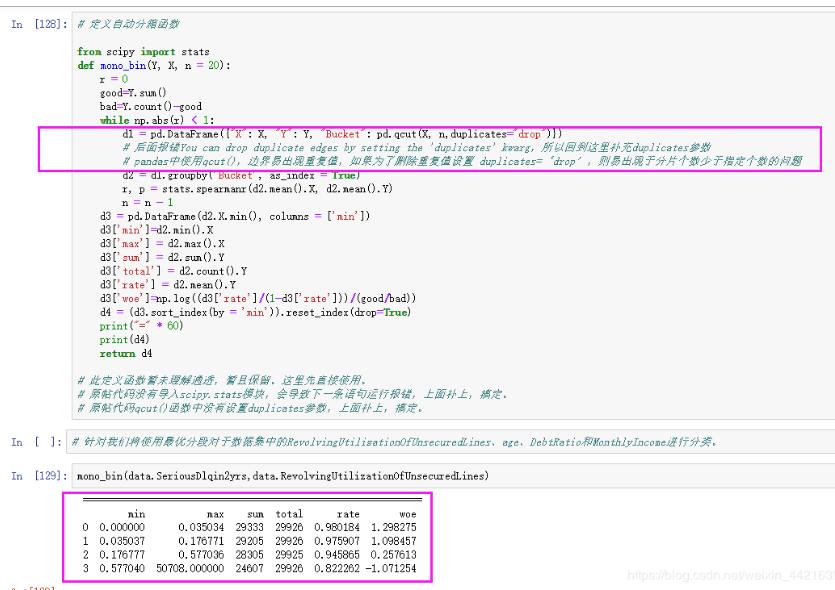
# 定义自动分箱函数
from scipy import stats
def mono_bin(Y, X, n = 20):
r = 0
good=Y.sum()
bad=Y.count()-good
while np.abs(r) < 1:
d1 = pd.DataFrame({"X": X, "Y": Y, "Bucket": pd.qcut(X, n,duplicates="drop")})
# 后面报错You can drop duplicate edges by setting the 'duplicates' kwarg,所以回到这里补充duplicates参数
# pandas中使用qcut(),边界易出现重复值,如果为了删除重复值设置 duplicates=‘drop',则易出现于分片个数少于指定个数的问题
d2 = d1.groupby('Bucket', as_index = True)
r, p = stats.spearmanr(d2.mean().X, d2.mean().Y)
n = n - 1
d3 = pd.DataFrame(d2.X.min(), columns = ['min'])
d3['min']=d2.min().X
d3['max'] = d2.max().X
d3['sum'] = d2.sum().Y
d3['total'] = d2.count().Y
d3['rate'] = d2.mean().Y
d3['woe']=np.log((d3['rate']/(1-d3['rate']))/(good/bad))
d4 = (d3.sort_index(by = 'min')).reset_index(drop=True)
print("=" * 60)
print(d4)
return d4
# 此定义函数暂未理解通透,暂且保留。这里先直接使用。
# 原帖代码没有导入scipy.stats模块,会导致下一条语句运行报错,上面补上,搞定。
# 原帖代码qcut()函数中没有设置duplicates参数,上面补上,搞定。
# 自定义函数分箱RevolvingUtilizationOfUnsecuredLines时报错You can drop duplicate edges by setting the 'duplicates' kwarg # 所以先回来删除重复值。删除后发现没有解决问题,真正解决问题是在qcut()函数中没有设置duplicates参数为“drop”(不能设置为“raise”) data=data.drop_duplicates(subset=None,keep='first',inplace=False) data.shape
(119703, 11)
# 针对我们将使用最优分段对于数据集中的RevolvingUtilizationOfUnsecuredLines、age、DebtRatio和MonthlyIncome进行分类。
mono_bin(data.SeriousDlqin2yrs,data.RevolvingUtilizationOfUnsecuredLines)
============================================================ min max sum total rate woe 0 0.000000 0.035034 29333 29926 0.980184 1.298275 1 0.035037 0.176771 29205 29926 0.975907 1.098457 2 0.176777 0.577036 28305 29925 0.945865 0.257613 3 0.577040 50708.000000 24607 29926 0.822262 -1.071254
| min | max | sum | total | rate | woe | |
|---|---|---|---|---|---|---|
| 0 | 0.000000 | 0.035034 | 29333 | 29926 | 0.980184 | 1.298275 |
| 1 | 0.035037 | 0.176771 | 29205 | 29926 | 0.975907 | 1.098457 |
| 2 | 0.176777 | 0.577036 | 28305 | 29925 | 0.945865 | 0.257613 |
| 3 | 0.577040 | 50708.000000 | 24607 | 29926 | 0.822262 | -1.071254 |
mono_bin(data.SeriousDlqin2yrs,data.age)
============================================================ min max sum total rate woe 0 21 30 7913 8885 0.890602 -0.506093 1 31 34 6640 7383 0.899363 -0.412828 2 35 38 7594 8386 0.905557 -0.342447 3 39 41 7131 7849 0.908523 -0.307262 4 42 43 4890 5362 0.911973 -0.265031 5 44 46 8163 8868 0.920501 -0.153830 6 47 48 5776 6274 0.920625 -0.152133 7 49 51 8545 9280 0.920797 -0.149768 8 52 53 5454 5901 0.924250 -0.101453 9 54 56 7922 8463 0.936075 0.080980 10 57 59 7517 7946 0.946011 0.260466 11 60 61 4942 5200 0.950385 0.349567 12 62 64 7464 7776 0.959877 0.571844 13 65 68 6968 7212 0.966167 0.748916 14 69 75 7911 8141 0.971748 0.934931 15 76 103 6620 6777 0.976833 1.138606
| min | max | sum | total | rate | woe | |
|---|---|---|---|---|---|---|
| 0 | 21 | 30 | 7913 | 8885 | 0.890602 | -0.506093 |
| 1 | 31 | 34 | 6640 | 7383 | 0.899363 | -0.412828 |
| 2 | 35 | 38 | 7594 | 8386 | 0.905557 | -0.342447 |
| 3 | 39 | 41 | 7131 | 7849 | 0.908523 | -0.307262 |
| 4 | 42 | 43 | 4890 | 5362 | 0.911973 | -0.265031 |
| 5 | 44 | 46 | 8163 | 8868 | 0.920501 | -0.153830 |
| 6 | 47 | 48 | 5776 | 6274 | 0.920625 | -0.152133 |
| 7 | 49 | 51 | 8545 | 9280 | 0.920797 | -0.149768 |
| 8 | 52 | 53 | 5454 | 5901 | 0.924250 | -0.101453 |
| 9 | 54 | 56 | 7922 | 8463 | 0.936075 | 0.080980 |
| 10 | 57 | 59 | 7517 | 7946 | 0.946011 | 0.260466 |
| 11 | 60 | 61 | 4942 | 5200 | 0.950385 | 0.349567 |
| 12 | 62 | 64 | 7464 | 7776 | 0.959877 | 0.571844 |
| 13 | 65 | 68 | 6968 | 7212 | 0.966167 | 0.748916 |
| 14 | 69 | 75 | 7911 | 8141 | 0.971748 | 0.934931 |
| 15 | 76 | 103 | 6620 | 6777 | 0.976833 | 1.138606 |
mono_bin(data.SeriousDlqin2yrs,data.MonthlyIncome)
============================================================ min max sum total rate woe 0 0.0 3400.0 27355 30073 0.909620 -0.293996 1 3401.0 5400.0 27655 30008 0.921588 -0.138884 2 5401.0 8200.0 27925 29725 0.939445 0.138736 3 8201.0 49750.0 28515 29897 0.953775 0.423899
| min | max | sum | total | rate | woe | |
|---|---|---|---|---|---|---|
| 0 | 0.0 | 3400.0 | 27355 | 30073 | 0.909620 | -0.293996 |
| 1 | 3401.0 | 5400.0 | 27655 | 30008 | 0.921588 | -0.138884 |
| 2 | 5401.0 | 8200.0 | 27925 | 29725 | 0.939445 | 0.138736 |
| 3 | 8201.0 | 49750.0 | 28515 | 29897 | 0.953775 | 0.423899 |
以上这篇浅谈pandas.cut与pandas.qcut的使用方法及区别就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
基于python 等频分箱qcut问题的解决
在python 较新的版本中,pandas.qcut()这个函数中是有duplicates这个参数的,它能解决在等频分箱中遇到的重复值过多引起报错的问题: 在比较旧版本的python中,提供一下解决办法: import pandas as pd def pct_rank_qcut(series, n): ''' series:要分箱的列 n:箱子数 ''' edages = pd.series([i/n for i in range(n)] # 转换成百分比 func = lambda x: (
-
利用Python计算KS的实例详解
在金融领域中,我们的y值和预测得到的违约概率刚好是两个分布未知的两个分布.好的信用风控模型一般从准确性.稳定性和可解释性来评估模型. 一般来说.好人样本的分布同坏人样本的分布应该是有很大不同的,KS正好是有效性指标中的区分能力指标:KS用于模型风险区分能力进行评估,KS指标衡量的是好坏样本累计分布之间的差值. 好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强. 1.crosstab实现,计算ks的核心就是好坏人的累积概率分布,我们采用pandas.crosstab函数来计算累积概率
-
使用python 计算百分位数实现数据分箱代码
对于百分位数,相信大家都比较熟悉,以下解释源引自百度百科. 百分位数,如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数.可表示为:一组n个观测值按数值大小排列.如,处于p%位置的值称第p百分位数. 因为百分位数是采用等分的方式划分数据,因此也可用此方法进行等频分箱. import pandas as pd import numpy as np import random t=pd.DataFrame(columns=['l','s']) #
-
浅谈pandas.cut与pandas.qcut的使用方法及区别
pandas.cut: pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False) 参数: 1. x,类array对象,且必须为一维,待切割的原形式 2. bins, 整数.序列尺度.或间隔索引.如果bins是一个整数,它定义了x宽度范围内的等宽面元数量,但是在这种情况下,x的范围在每个边上被延长1%,以保证包括x的最小值或最大值.如果bin是序列,它定义了允许非均匀
-
浅谈python的dataframe与series的创建方法
如下所示: # -*- coding: utf-8 -*- import numpy as np import pandas as pd def main(): s = pd.Series([i*2 for i in range(1,11)]) print type(s) print (s) dates = pd.date_range("20170301",periods=8) df = pd.DataFrame(np.random.randn(8,5),index=dates,col
-

浅谈Scala的Class、Object和Apply()方法
Scala中如果一个Class和一个Object同名,则称Class是Object的伴生类.Scala没有Java的Static修饰符,Object下的成员和方法都是静态的,类似于Java里面加了Static修饰符的成员和方法.Class和Object都可以定义自己的Apply()方法,类名()调用Object下的Apply()方法,变量名()调用Class下的Apply()方法. class ApplyTest{ def apply() { println("This is a class,
-
浅谈几种常用的JS类定义方法
// 方法1 对象直接量 var obj1 = { v1 : "", get_v1 : function() { return this.v1; }, set_v1 : function(v) { this.v1 = v; } }; // 方法2 定义函数对象 var Obj = function() { var v1 = ""; this.get_v1 = function() { return this.v1; }; this.set_v1 = function
-
浅谈java 执行jar包中的main方法
浅谈java 执行jar包中的main方法 通过 OneJar 或 Maven 打包后 jar 文件,用命令: java -jar ****.jar 执行后总是运行指定的主方法,如果 jar 中有多个 main 方法,那么如何运行指定的 main 方法呢? 用下面的命令试试看: java -classpath ****.jar ****.****.className [args] "****.****"表示"包名": "className"表示&
-
浅谈静态变量、成员变量、局部变量三者的区别
静态变量和成员变量的区别: A:所属不同 静态变量:属于类,类变量 成员变量:属于对象,对象变量,实例变量 B:内存位置不同 静态变量:方法区的静态区 成员变量:堆内存 C:生命周期不同 静态变量:静态变量是随着类的加载而加载,随着类的消失而消失 成员变量:成员变量是随着对象的创建而存在,随着对象的消失而消失 D:调用不同 静态变量:可以通过对象名调用,也可以通过类名调用 成员变量:只能通过对象名调用 成员变量和局部变量的区别: A:在类中的位置不同 成员变量:在类中方法
-
浅谈Python类的__getitem__和__setitem__特殊方法
一个有点绕的例子,用PyScripter调试器步进跟踪可以看清楚对 象结构的具体细节. 对原作改变了一下,在未定义子对象属性时__getitem__中使用现成的__setitem__来定义. ## encoding:utf-8 """ 这个类继承了object, object是Python的最小单元,可以在Python的">>>"控制台用dir(objct)或者dir (__builtins__.object)命令查看它的属性,可以看到_
-
浅谈htmlentities 、htmlspecialchars、addslashes的使用方法
1.html_entity_decode():把html实体转换为字符. Eg:$str = "just atest & 'learn to use '"; echo html_entity_decode($str); echo "<br />"; echo html_entity_decode($str,ENT_QUOTES); echo "<br />"; echo html_entity_decode($st
-
浅谈C语言共用体和与结构体的区别
共用体与结构体的区别 共用体: 使用union 关键字 共用体内存长度是内部最长的数据类型的长度. 共用体的地址和内部各成员变量的地址都是同一个地址 结构体大小: 结构体内部的成员,大小等于最后一个成员的偏移量+最后一个成员大小+末尾的填充字节数. 结构体的偏移量:某一个成员的实际地址和结构体首地址之间的距离. 结构体字节对齐:每个成员相对于结构体首地址的偏移量都得是当前成员所占内存大小的整数倍,如果不是会在成员前面加填充字节.结构体的大小是内部最宽的成员的整数倍. 共用体 #include <
-
浅谈innodb_autoinc_lock_mode的表现形式和选值参考方法
前提条件,percona 5.6版本,事务隔离级别为RR mysql> show create table test_autoinc_lock\G *************************** 1. row *************************** Table: test_autoinc_lock Create Table: CREATE TABLE `test_autoinc_lock` ( `id` int(11) NOT NULL AUTO_INCREMENT, `