Java 获取网站图片的示例代码
目录
- 前提
- 一、新建Maven项目,导入Jsoup环境依赖
- 二、代码编写
- 心得:
前提
最近我的的朋友浏览一些网站,看到好看的图片,问我有没有办法不用手动一张一张保存图片!
我说用Jsoup丫!

打开开发者模式(F12),找到对应图片的链接,在互联网中,每一张图片就是一个链接!
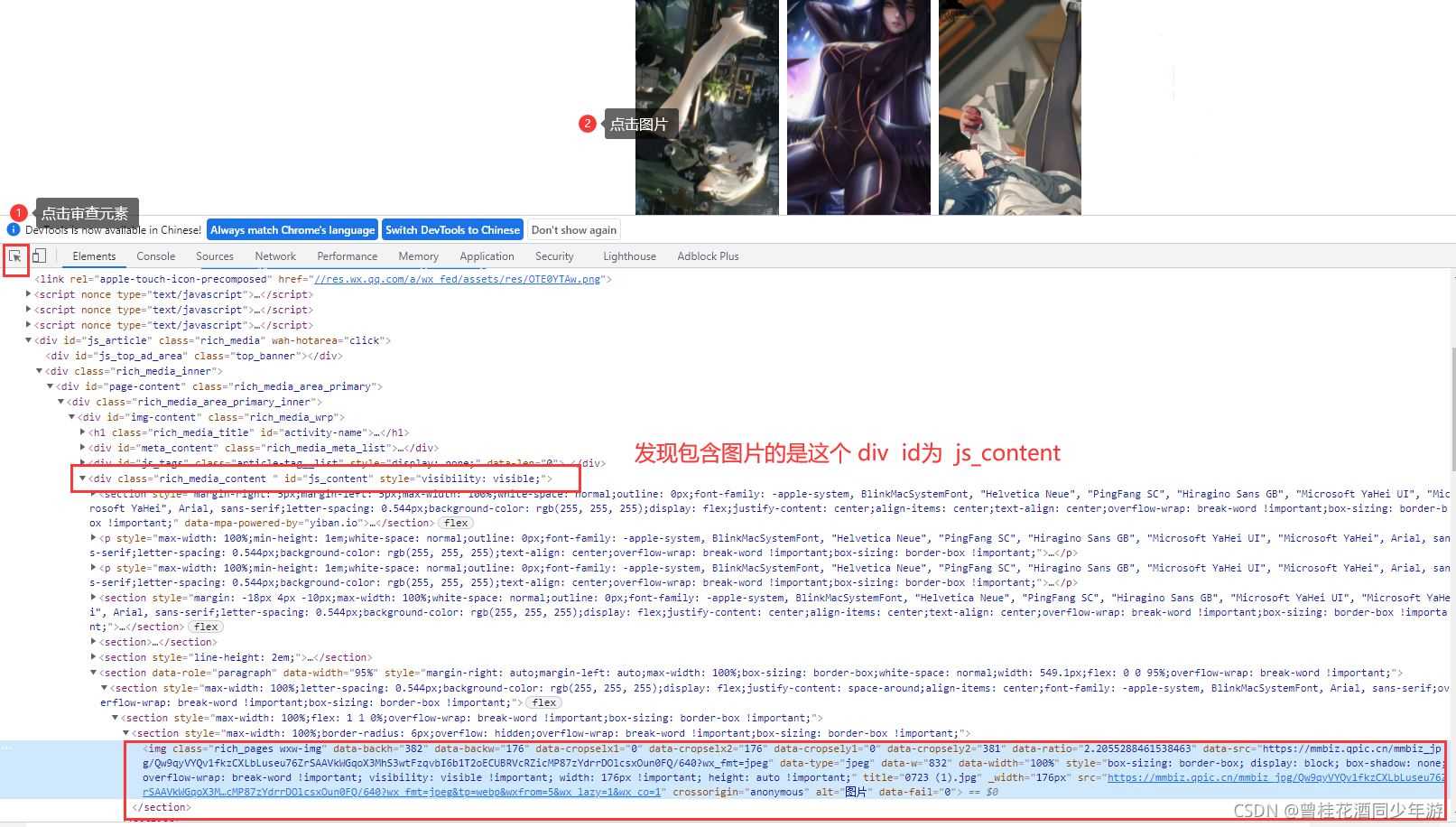
一、新建Maven项目,导入Jsoup环境依赖
<groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.11.2</version> </dependency>
二、代码编写
public class JsoupTest {
public static void main(String[] args) throws IOException {
// 爬虫的网站
String url="https://mp.weixin.qq.com/s/caU6d6ebpsLVJaf-7gMjtg";
// 获得网页的document对象
Document document = Jsoup.parse(new URL(url), 10000);
// 爬取含图片的代码部分
Element content = document.getElementById("js_content");
// 获取img标签代码 这是个集合
Elements imgs = content.getElementsByTag("img");
// 命名图片的id
int id=0;
for (Element img : imgs) {
// 获取具体的图片
String pic = img.attr("data-src");
URL target = new URL(pic);
// 获取连接对象
URLConnection urlConnection = target.openConnection();
// 获取输入流,用来读取图片信息
InputStream inputStream = urlConnection.getInputStream();
// 获取输出流 输出地址+文件名
id++;
FileOutputStream fileOutputStream = new FileOutputStream("E:\\JsoupPic\\" + id + ".png");
int len=0;
// 设置一个缓存区
byte[] buffer = new byte[1024 * 1024];
// 写出图片到E:\JsoupPic中, 输入流读数据到缓冲区中,并赋给len
while ((len=inputStream.read(buffer))>0){
// 参数一:图片数据 参数二:起始长度 参数三:终止长度
fileOutputStream.write(buffer, 0, len);
}
System.out.println(id+".png下载完毕");
// 关闭输入输出流 最后创建先关闭
fileOutputStream.close();
inputStream.close();
}
}
}
成果:
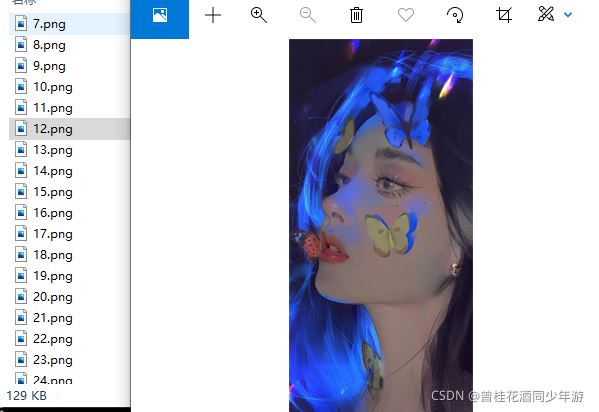
心得:
1、网络上的每一张图片都是一个链接
2、我们知道整个网页就是一个文档数,先找到包含图片的父id,再通过getElementsByTag()获取到图片的标签,通过F12,我们知道图片的链接是存在img标签里面的 data-src属性中
3、通过标签的data-src属性,就获取到具体图片的链接
4、通过输入输出流,把图片保存在本地中!
到此这篇关于Java 获取网站图片的示例代码的文章就介绍到这了,更多相关Java 获取网站图片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

通过Java 程序获取Word中指定图片的坐标位置
之前给大家介绍过Java解析word,获取文档中图片位置的方法,感兴趣的朋友点击查看下,今天给大家介绍如何通过Java 程序获取Word中指定图片的坐标位置,感兴趣的朋友一起看看吧! 程序运行环境: Word测试文档:.docx 2013 Free Spire.doc.jar 3.9.0 IntelliJ IDEA JDK 1.8.0 方法步骤: 1. 指定文件路径,本次测试代码路径为项目文件夹路径.即在IDEA项目文件下存入用于测试的Word文档,如:C:\Users\Administrato
-
Java解析word,获取文档中图片位置的方法
前言(背景介绍): Apache POI是Apache基金会下一个开源的项目,用来处理office系列的文档,能够创建和解析word.excel.ppt格式的文档. 其中对word文档的处理有两个技术,分别是HWPF(.doc)和XWPF(.docx).如果你对这两个技术熟悉的话,就应该能明白使用java解析word文档的痛楚所在. 其中两个最大的问题在于: 第一是这两个类并没有统一的父类和接口(隔壁的XSSF和HSSF投过来鄙视的眼光),所以没法进行同一格式的接口式编程: 第二是官方API中并
-
Java 根据网络URL获取该网页上面所有的img标签并下载图片
说明:根据网络URL获取该网页上面所有的img标签并下载符合要求的所有图片 所需jar包:jsoup.jar import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.
-
java获取网络图片上传到OSS的方法
OSS不支持通过一个网络地址来上传图片,所以若想将网络上的图片上传到OSS上需要走点弯路. 1.通过链接将图片下载到本地的一个文件夹下面 2.用OSS上传该文件夹下的文件 3.上传完成后删除本地的文件 具体代码如下: //获取当前项目的绝对路径 public static String getTomcatPath(){ String nowpath; String tempdir; nowpath=System.getProperty("user.dir"); tempdir=nowp
-
Java中使用正则表达式获取网页中所有图片的路径
/** * 从HTML源码中提取图片路径,最后以一个 String 类型的 List 返回,如果不包含任何图片,则返回一个 size=0 的List * 需要注意的是,此方法只会提取以下格式的图片:.jpg|.bmp|.eps|.gif|.mif|.miff|.png|.tif|.tiff|.svg|.wmf|.jpe|.jpeg|.dib|.ico|.tga|.cut|.pic * @param htmlCode HTML源码 * @return <img>标签 src 属性指向的图片地址的
-
Java 获取网站图片的示例代码
目录 前提 一.新建Maven项目,导入Jsoup环境依赖 二.代码编写 心得: 前提 最近我的的朋友浏览一些网站,看到好看的图片,问我有没有办法不用手动一张一张保存图片! 我说用Jsoup丫! 测试网站 打开开发者模式(F12),找到对应图片的链接,在互联网中,每一张图片就是一个链接! 一.新建Maven项目,导入Jsoup环境依赖 <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> &l
-
Node.js实现爬取网站图片的示例代码
目录 涉及知识点 cheerio简介 什么是cheerio ? 安装cheerio 准备工作 核心代码 示例截图 涉及知识点 开发一个小爬虫,涉及的知识点如下所示: https模块,主要是用户获取网络资源,如:网页源码,图片资源等. cheerio模块,主要用于解析html源码,并可访问,查找html节点内容. fs模块,主要用于文件的读写操作,如保存图片,日志等. 闭包,主要是对于异步操作,对象的隔离保护. cheerio简介 什么是cheerio ? cheerio是为服务器特别定制的,快速
-
java 生成文字图片的示例代码
本文主要介绍了java 生成文字图片的示例代码,分享给大家,具体如下: import java.awt.Color; import java.awt.Font; import java.awt.FontMetrics; import java.awt.Graphics; import java.awt.Rectangle; import java.awt.image.BufferedImage; import java.io.File; import javax.imageio.ImageIO;
-
基于Java实现修改图片分辨率示例代码
目录 前言 环境依赖 代码 验证一下 前言 本文提供可以修改图片分辨率的java工具类,实用主义的狂欢. 环境依赖 添加必要的一些maven依赖. <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.15</version> </dependency> <dependency&
-
Java 添加、替换、删除PDF中的图片的示例代码
概述 本文介绍通过java程序向PDF文档添加图片,以及替换和删除PDF中已有的图片.另外,关于图片的操作还可参考设置PDF 图片背景.设置PDF图片水印.读取PDF中的图片.将PDF保存为图片等文章. 工具:Free Spire.PDF for Java (免费版) Jar获取及导入:官网下载,并解压将lib文件夹下的jar文件导入java程序,或者通过maven仓库下载并导入. jar导入效果: Java代码示例 [示例1]添加图片到PDF import com.spire.pdf.*; i
-
java后台接收app上传的图片的示例代码
整理文档,搜刮出一个java后台接受app上传的图片的示例代码,稍微整理精简一下做下分享 package com.sujinabo.file; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.util.List; import java.util.UUID; import javax.servlet.S
-
java实现爬虫爬网站图片的实例代码
第一步,实现 LinkQueue,对url进行过滤和存储的操作 import java.util.ArrayList; import java.util.Collections; import java.util.HashSet; import java.util.List; import java.util.Set; public class LinkQueue { // 已访问的 url 集合 private static Set<String> visitedUrl = Collecti
-
Java批量写入文件和下载图片的示例代码
很久没有在WhitMe上写日记了,因为觉着在App上写私密日记的话肯定是不安全的,但是想把日记存下来.,然后看到有导出日记的功能,就把日记导出了(还好可以直接导出,不然就麻烦点).导出的是一个html文件.可以直接打开,排版都还在. 看了下源码,是把日记存在一个json数组里了,图片还是在服务器,利用url访问,文字是在本地了. 但是想把图片下载到本地,然后和文字对应,哪篇日记下的哪些图片. 大概是如下的json数组. 大概有几百条,分别是头像.内容:文字||内容:图片.时间. 简单明了的jso
-
java高质量缩放图片的示例代码
可按照比例缩放,也可以指定宽高 import com.sun.image.codec.jpeg.JPEGImageEncoder; import com.sun.image.codec.jpeg.JPEGCodec; import com.sun.image.codec.jpeg.JPEGEncodeParam; import javax.swing.*; import java.io.File; import java.io.FileOutputStream; import java.io.I
-
Java实现中国象棋的示例代码
目录 前言 主要设计 功能截图 代码实现 总结 前言 中国象棋是起源于中国的一种棋,属于二人对抗性游戏的一种,在中国有着悠久的历史.由于用具简单,趣味性强,成为流行极为广泛的棋艺活动. 中国象棋使用方形格状棋盘,圆形棋子共有32个,红黑二色各有16个棋子,摆放和活动在交叉点上.双方交替行棋,先把对方的将(帅)“将死”的一方获胜. 中国象棋是一款具有浓郁中国特色的益智游戏,新增的联网对战,趣味多多,聚会可以约小朋友一起来挑战.精彩的对弈让你感受中国象棋的博大精深. <中国象棋>游戏是用java语