详解Python实现URL监测与即时推送
目录
- 原理
- 环境
- 代码
- crontab计划任务配置
- 预警消息效果
- 总结
原理
采用Python requests发起请求监测的URL,检测Http响应状态及是否超时,如果Http状态异常或响应超时,则通过聚合云推的消息推送API将预警消息发送至邮箱、钉钉机器人、企业微信机器人、微信公众号等,服务端通过crontab定时(每分钟)执行代码,实现动态监测功能。
环境
操作系统: CentOS 7.x
Python版本: 3.6
消息推送服务: tui.juhe.cn
代码
#!/usr/bin/python3
import requests
import time
import json
# 监测URL是否正常响应
def url_check(url):
# 当前时间
check_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print("开始监测:%s -- %s" % (url, check_time))
try:
# 请求URL, 设置3s超时
r = requests.get(url, timeout=3)
if r.status_code != 200:
# 请求响应状态异常
msg = "监控的URL:%s%sHttp状态异常:%s%s监测时间:%s" % (url, "\n\n", r.status_code, "\n\n", check_time)
print("监测结果:异常(Http状态异常:%s) -- %s" % (r.status_code, check_time))
# 通过云推推送消息
yuntui_push(msg)
else:
# 请求响应正常
print("监测结果:正常 -- %s" % check_time)
except requests.exceptions.ConnectTimeout:
# 请求响应超时
msg = "监控的URL:%s%s请求异常:%s%s监测时间:%s" % (url, "\n\n", "请求超时", "\n\n", check_time)
print("监测结果:超时 -- %s" % check_time)
# 通过云推推送消息
yuntui_push(msg)
# 将预警消息通过云推推送
def yuntui_push(content):
# 当前时间
push_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# 云推接口的信息配置,可以通过 https://tui.juhe.cn 自行注册创建
# (可以配置邮件、钉钉机器人、微信公众号等接收方式)
token = "*****************"
service_id = "******"
title = "URL可用性监控预警"
doc_type = "markdown"
body = {"token": token, "service_id": service_id, "title": title, "content": content, "doc_type": doc_type}
try:
r = requests.post("https://tui.juhe.cn/api/plus/pushApi", data=body, timeout=15)
push_res = json.loads(r.content)
code = push_res['code']
if code == 200:
print("推送结果:成功 -- %s" % push_time)
else:
print("推送结果:失败(%s) -- %s" % (push_res['reason'], push_time))
except requests.exceptions.ConnectTimeout:
print("推送结果:超时 -- %s" % push_time)
# 执行URL可用性监测
if __name__ == '__main__':
# 监控URL可用性
# url_check("https://www.test.com")
url_check("https://www.baidu.com/")
如果requests未安装可以执行以下命令安装
pip3 install requests
crontab计划任务配置
命令行输入crontab -e进入计划任务配置
# 每分钟执行一次 */1 * * * * /usr/bin/python3 /data/check_url/main.py >> /data/log.txt
查看日志
cat /data/log.txt
开始监测:https://www.baidu.com/ -- 2021-11-16 15:04:01 监测结果:正常 -- 2021-11-16 15:04:01 开始监测:https://www.baidu.com/ -- 2021-11-16 15:05:02 监测结果:正常 -- 2021-11-16 15:05:02 开始监测:https://www.baidu.com/ -- 2021-11-16 15:06:01 监测结果:正常 -- 2021-11-16 15:06:01 开始监测:https://www.baidu.com/ -- 2021-11-16 15:07:01 监测结果:正常 -- 2021-11-16 15:07:01 开始监测:https://www.baidu.com/ -- 2021-11-16 15:08:01 监测结果:正常 -- 2021-11-16 15:08:01 开始监测:https://www.test.com -- 2021-11-16 15:11:01 监测结果:超时 -- 2021-11-16 15:11:01 推送结果:成功 -- 2021-11-16 15:11:04 开始监测:https://www.test.com -- 2021-11-16 15:12:01 监测结果:超时 -- 2021-11-16 15:12:01 推送结果:成功 -- 2021-11-16 15:12:04
预警消息效果
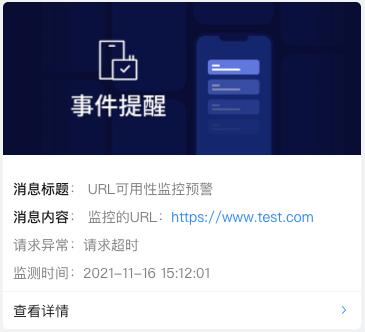
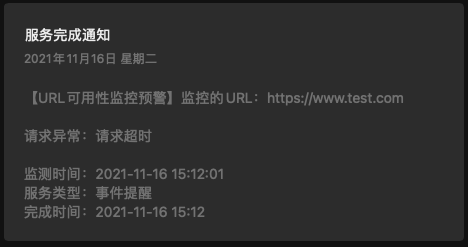
如果监测到异常结果,你在云推配置的接收终端将会收到通知,类似如下:
钉钉群机器人:
邮件:

微信公众号:
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
Python根据URL地址下载文件并保存至对应目录的实现
引言 在编程中经常会遇到图片等数据集将图片等数据以URL形式存储在txt文档中,为便于后续的分析,需要将其下载下来,并按照文件夹分类存储.本文以Github中Alexander Kim提供的图片分类数据集为例,下载其提供的图片样本并分类保存 Python 3.6.5,Anaconda, VSCode 1. 下载数据集文件 建立项目文件夹,下载上述Github项目中的raw_data文件夹,并保存至项目目录中. 2. 获取样本文件位置 编写get_doc_path.py,根据根目录位置,获取目录
-

Python Django获取URL中的数据详解
目录 Django获取URL中的数据 URL路径参数 使用path函数 使用re_path函数 URL关键字形式 总结 Django获取URL中的数据 URL中的参数一般有两种形式.如下所示: 1. https://zy010101.blog.csdn.net/article/details/120816954 2. https://so.csdn.net/so/search?q=Django&t=blog&u=zy010101 我们将第一种形式称为"URL路径参数":
-
Python之进行URL编码案例讲解
为什么要对URL进行encode 在写网络爬虫时,发现提交表单中的中文字符都变成了TextBox1=%B8%C5%C2%CA%C2%DB这种样子,观察这是中文对应的GB2312编码,实际上是进行了GB2312编码和urlencode. 那么为什么要对URL进行encode? 因为在标准的url规范中中文和很多的字符是不允许出现在url中的.为了字符编码(gbk.utf-8)和特殊字符不出现在url中,url转义是为了符合url的规范. 具体代码 urlencode编码:urllib中的quote
-
python 通过视频url获取视频的宽高方式
这里其实是通过获取视频截图的方式获得大小的 下面列举两个小demo import cv2 #引入模块 获取视频截图的 from PIL import Image #引入模块 获取图片大小 import os #引入系统命令 删除图片 video_full_path="http://qnmov.a.yximgs.com/upic/2018/06/06/12/BMjAxODA2MDYxMjQwMTZfMTkzMDUyMjRfNjU2NzMwNzI5MF8xXzM=_hd3_Bc143c8abf799
-
python爬虫模块URL管理器模块用法解析
这篇文章主要介绍了python爬虫模块URL管理器模块用法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 URL管理器模块 一般是用来维护爬取的url和未爬取的url已经新添加的url的,如果队列中已经存在了当前爬取的url了就不需要再重复爬取了,另外防止造成一个死循环.举个例子 我爬www.baidu.com 其中我抓取的列表中有music.baidu.om,然后我再继续抓取该页面的所有链接,但是其中含有www.baidu.com,可以想
-
详解Python实现URL监测与即时推送
目录 原理 环境 代码 crontab计划任务配置 预警消息效果 总结 原理 采用Python requests发起请求监测的URL,检测Http响应状态及是否超时,如果Http状态异常或响应超时,则通过聚合云推的消息推送API将预警消息发送至邮箱.钉钉机器人.企业微信机器人.微信公众号等,服务端通过crontab定时(每分钟)执行代码,实现动态监测功能. 环境 操作系统: CentOS 7.x Python版本: 3.6 消息推送服务: tui.juhe.cn 代码 #!/usr/bin/py
-
详解IOS开发之实现App消息推送(最新)
好久没有写过博客啦,今天就由本菜鸟给大家做一个简单的IOSApp消息推送教程吧!一切从0开始,包括XCode6, IOS8, 以及苹果开发者中心最新如何注册应用,申请证书以及下载配置概要文件,相信很多刚开始接触iOS的人会很想了解一下.(ps:网上看了一下虽然有很多讲述推送的好教程,我也是看着一步步学会的,但是这些教程的时间都是去年或者更早时期的,对引导新手来说不是很合适) 第一部分 首先第一步当然是介绍一下苹果的推送机制(APNS)咯(ps:其实每一篇教程都有),先来看一张苹果官方对其推送做出
-
详解Python在七牛云平台的应用(一)
七牛云七牛云是国内领先的企业级云服务商.专注于以数据为核心的云计算业务,围绕富媒体场景推出了对象存储.融合CDN.容器云.大数据.深度学习平台等产品,并提供一站式视频云解决方案,同时打造简单,可信赖的解决方案平台,帮助企业快速上云,创造更大的商业价值. 以上是官网介绍. (一)在这里介绍一下Python怎么通过官方提供的库对自己空间进行操作 首先需要注册一个七牛的账号,并创建一个Bucket,另外还需要在个人面板中的密匙中得到AK和SK.之后就能通过七牛的SDK对自己的空间进行操作了. 本文对上
-
实例详解Python装饰器与闭包
闭包是Python装饰器的基础.要理解闭包,先要了解Python中的变量作用域规则. 变量作用域规则 首先,在函数中是能访问全局变量的: >>> a = 'global var' >>> def foo(): print(a) >>> foo() global var 然后,在一个嵌套函数中,内层函数能够访问在外层函数中定义的局部变量: >>> def foo(): a = 'free var' def bar(): print(a)
-
详解Python的爬虫框架 Scrapy
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便. 一.概述 下图显示了Scrapy的大体架构,其中包含了它的主要组件及系统的数据处理流程(绿色箭头所示).下面就来一个个解释每个组件的作用及数据的处理过程(注:图片来自互联网). 二.组件 1.Scrapy Engine(Scrapy引擎) Scrapy引擎
-
详解python logging日志传输
1.生成日志并通过http传输出去(通过HTTPHandler方式): #生成并发送日志 import logging from logging.handlers import HTTPHandler import logging.config def save(): logger = logging.getLogger(__name__) # 生成一个log实例,如果括号为空则返回root logger hh = HTTPHandler(host='127.0.0.1:5000', url='
-
详解python UDP 编程
前面我们讲了 TCP 编程,我们知道 TCP 可以建立可靠连接,并且通信双方都可以以流的形式发送数据.本文我们再来介绍另一个常用的协议–UDP.相对TCP,UDP则是面向无连接的协议. UDP 协议 我们来看 UDP 的定义: UDP 协议(User Datagram Protocol),中文名是用户数据报协议,是 OSI(Open System Interconnection,开放式系统互联) 参考模型中一种无连接的传输层协议,提供面向事务的简单不可靠信息传送服务. 从这个定义中,我们可以总结
-
详解python内置模块urllib
urllib 是 python 的内置模块, 主要用于处理url相关的一些操作,例如访问url.解析url等操作. urllib 包下面的 request 模块主要用于访问url,但是用得太多,因为它的光芒全都被 requests 这个第三方库覆盖了,最常用的还是 parse 模块. 写爬虫过程中,经常要对url进行参数的拼接.编码.解码,域名.资源路径提取等操作,这时 parse 模块就可以排上用场. 一.urlparse urlparse 方法是把一个完整的URL拆分成不同的组成部分,你可以
-
详解Python中第三方库Faker
项目开发初期,为了测试方便,我们总要造不少假数据到系统中,尽量模拟真实环境. 比如要创建一批用户名,创建一段文本,电话号码,街道地址.IP地址等等. 平时我们基本是键盘一顿乱敲,随便造个什么字符串出来,当然谁也不认识谁. 现在你不要这样做了,用Faker就能满足你的一切需求. 1. 安装 pip install Faker 2. 简单使用 >>> from faker import Faker >>> fake = Faker(locale='zh_CN') >&
-
详解python爬取弹幕与数据分析
很不幸的是,由于疫情的关系,原本线下的AWD改成线上CTF了.这就很难受了,毕竟AWD还是要比CTF难一些的,与人斗现在变成了与主办方斗. 虽然无奈归无奈,但是现在还是得打起精神去面对下一场比赛.这个开始也是线下的,决赛地点在南京,后来是由于疫情的关系也成了线上. 当然,比赛内容还是一如既往的得现学,内容是关于大数据的. 由于我们学校之前并没有开设过相关培训,所以也只能自己琢磨了. 好了,废话先不多说了,正文开始. 一.比赛介绍 大数据总体来说分为三个过程. 第一个过程是搭建hadoop环境.