python机器学习Sklearn实战adaboost算法示例详解
目录
- pandas批量处理体测成绩
- adaboost
- adaboost原理案例举例
- 弱分类器合并成强分类器
pandas批量处理体测成绩
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
data = pd.read_excel("/Users/zhucan/Desktop/18级高一体测成绩汇总.xls")
cond = data["班级"] != "班级" data = data[cond] data.fillna(0,inplace=True) data.isnull().any() #没有空数据了
结果:
班级 False
性别 False
姓名 False
1000米 False
50米 False
跳远 False
体前屈 False
引体 False
肺活量 False
身高 False
体重 False
dtype: bool
data.head()
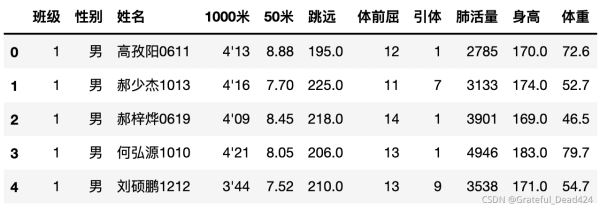
#1000米成绩有string 有int
def convert(x):
if isinstance(x,str):
minute,second = x.split("'")
int(minute)
minute = int(minute)
second = int(second)
return minute + second/100.0
else:
return x
data["1000米"] = data["1000米"].map(convert)
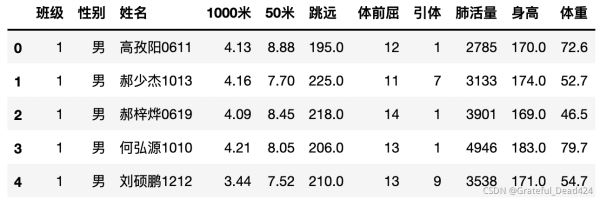
score = pd.read_excel("/Users/zhucan/Desktop/体侧成绩评分表.xls",header=[0,1])
score

def convert(item):
m,s = item.strip('"').split("'")
m,s =int(m),int(s)
return m+s/100.0
score.iloc[:,-4] = score.iloc[:,-4].map(convert)
def convert(item):
m,s = item.strip('"').split("'")
m,s =int(m),int(s)
return m+s/100.0
score.iloc[:,-2] = score.iloc[:,-2].map(convert)
score
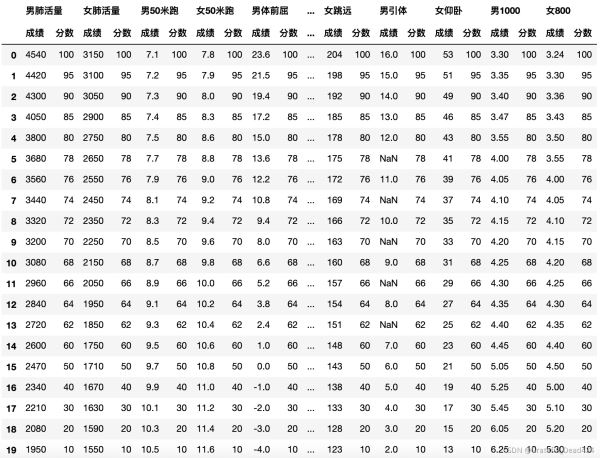
data.columns = ['班级', '性别', '姓名', '男1000', '男50米跑', '跳远', '体前屈', '引体', '肺活量', '身高', '体重']
data["男50米跑"] = data["男50米跑"].astype(np.float)
for col in ["男1000","男50米跑"]:
#获取成绩的标准
s = score[col]
def convert(x):
for i in range(len(s)):
if x<=s["成绩"].iloc[0]:
if x == 0:
return 0 #没有参加这个项目
return 100
elif x>s["成绩"].iloc[-1]:
return 0 #跑的太慢
elif (x>s["成绩"].iloc[i-1]) and (x<=s["成绩"].iloc[i]):
return s["分数"].iloc[i]
data[col + "成绩"] = data[col].map(convert)
for col in ['跳远', '体前屈', '引体', '肺活量']:
s = score["男"+col]
def convert(x):
for i in range(len(s)):
if x>s["成绩"].iloc[i]:
return s["分数"].iloc[i]
return 0
data[col+"成绩"] = data[col].map(convert)
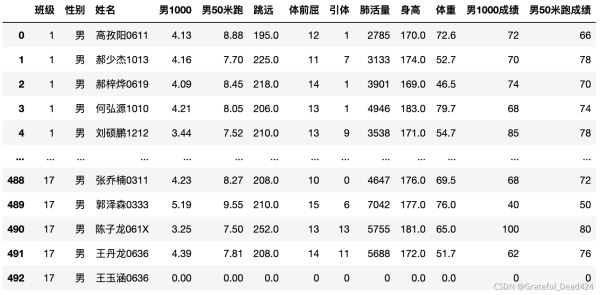
data.columns
结果:
Index(['班级', '性别', '姓名', '男1000', '男50米跑', '跳远', '体前屈', '引体', '肺活量', '身高',
'体重', '男1000成绩', '男50米跑成绩', '跳远成绩', '体前屈成绩', '引体成绩', '肺活量成绩'],
dtype='object')
#根据索引的顺序,去data取值 cols = ['班级', '性别', '姓名', '男1000','男1000成绩','男50米跑','男50米跑成绩','跳远','跳远成绩','体前屈','体前屈成绩','引体','引体成绩', '肺活量','肺活量成绩','身高','体重'] data[cols]
#计算BMI
data["BMI"] = data["体重"]/data["身高"]
def convert(x):
if x>100:
return x/100
else:
return x
data["身高"] = data["身高"].map(convert)
data["BMI"] = data["体重"]/(data["身高"])**2
def convert_bmi(x):
if x >= 26.4:
return 60
elif (x <= 16.4) or (x > 23.3 and x <= 26.3):
return 80
elif x >= 16.5 and x <= 23.2:
return 100
else:
return 0
data["BMI_score"] = data["BMI"].map(convert_bmi)
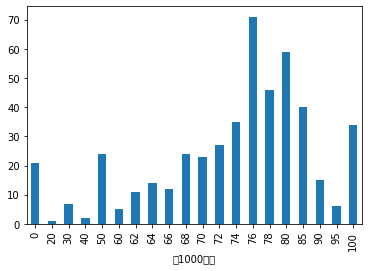
#统计分析 data["BMI_score"].value_counts().plot(kind = "pie",autopct = "%0.2f%%") #统计分析 data["BMI_score"].value_counts().plot(kind = "bar")
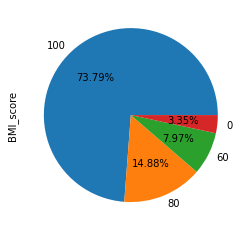
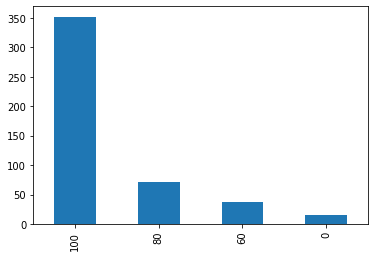
data.groupby(["男1000成绩"])["BMI_score"].count().plot(kind = "bar")
adaboost
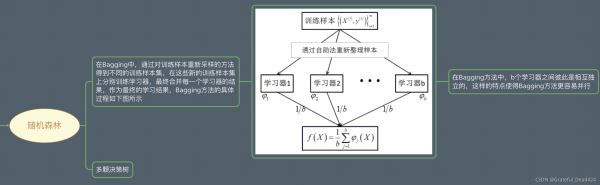
 值
值
越大,特征越明显,越被容易分开;越后面的学习器,权重越大
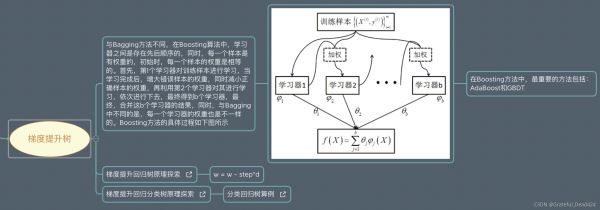
梯度提升树没有修改原来的数据,使用的是残差,最终结果就是最后一棵树
上面的图不是GBDT
Boosting与Bagging模型相比,Boosting可以同时降低偏差和方差,Bagging只能降低模型的方差。在实际应用中,Boosting算法也还是存在明显的高方差问题,也就是过拟合。


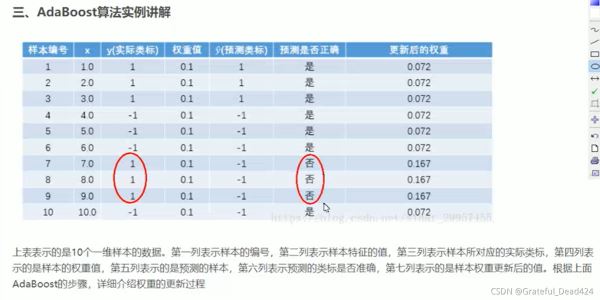
import numpy as np y = np.array([0,1]*5) y_ = np.array([0,0,0,0,0,0,0,1,0,1]) w = 0.1*(y != y_).sum() round(w,1)
结果:
0.3
0.5*np.log((1-0.3)/0.3) round((0.5*np.log((1-0.3)/0.3)),2)
结果:
0.42
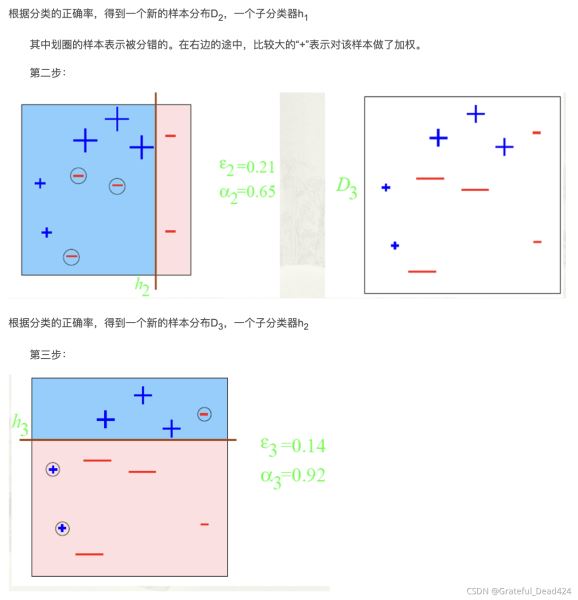




adaboost原理案例举例
from sklearn.ensemble import AdaBoostClassifier from sklearn import tree import matplotlib.pyplot as plt X = np.arange(10).reshape(-1,1) y = np.array([1,1,1,-1,-1,-1,1,1,1,-1]) ada = AdaBoostClassifier(n_estimators=3) ada.fit(X,y)
plt.figure(figsize = (9,6)) _ = tree.plot_tree(ada[0])

y_ = ada[0].predict(X),4 y_
结果:
array([ 1, 1, 1, -1, -1, -1, -1, -1, -1, -1])
#误差率 e1 = np.round(0.1*(y != y_).sum(),4) e1
结果:
0.3
#计算第一棵树权重 #随机森林中每棵树的权重是一样的 #adaboost提升树中每棵树的权重不同 a1 = np.round(1/2*np.log((1-e1)/e1),4) a1
结果:
0.4236
#样本预测准确:更新的权重 w2 = 0.1*np.e**(-a1*y*y_) w2 = w2/w2.sum() np.round(w2,4)
结果:
array([0.0714, 0.0714, 0.0714, 0.0714, 0.0714, 0.0714, 0.1667, 0.1667,
0.1667, 0.0714])
#样本预测准确:更新的权重 w2 = 0.1*np.e**(-a1*y*y_) w2 = w2/w2.sum() np.round(w2,4)
结果:
array([0.0714, 0.0714, 0.0714, 0.0714, 0.0714, 0.0714, 0.1667, 0.1667,
0.1667, 0.0714])
从上述第一轮的整个迭代过程可以看出:被误分类样本的权值之和影响误差率,误差率影响基本分类器在最终分类器中所占的权重
分类函数 f1(x)= a1*G1(x)= 0.4236G1(x)

plt.figure(figsize = (9,6)) _ = tree.plot_tree(ada[1])

e2 = 0.0714*3 e2
结果:
0.2142
a2 = np.round(1/2*np.log((1-e2)/e2),4) a2
结果:
0.6499
y_ = ada[1].predict(X) #样本预测准确:更新的权重 w3 = w2*np.e**(-a2*y*y_) w3 = w3/w3.sum() np.round(w3,4)
结果:
array([0.0454, 0.0454, 0.0454, 0.1667, 0.1667, 0.1667, 0.106 , 0.106 ,
0.106 , 0.0454])
plt.figure(figsize = (9,6)) _ = tree.plot_tree(ada[2])


树划分按照gini系数;结果和按照误差率是一致的~
y_ = ada[2].predict(X) e3 = (w3*(y_ != y)).sum() a3 = 1/2*np.log((1-e3)/e3) a3 #样本预测准确:更新的权重 w4 = w3*np.e**(-a3*y*y_) w4 = w4/w4.sum() np.round(w4,4)
结果:
array([0.125 , 0.125 , 0.125 , 0.1019, 0.1019, 0.1019, 0.0648, 0.0648,
0.0648, 0.125 ])
display(a1,a2,a3)
结果:
0.4236
0.6498960745553556
0.7521752700597043
弱分类器合并成强分类器
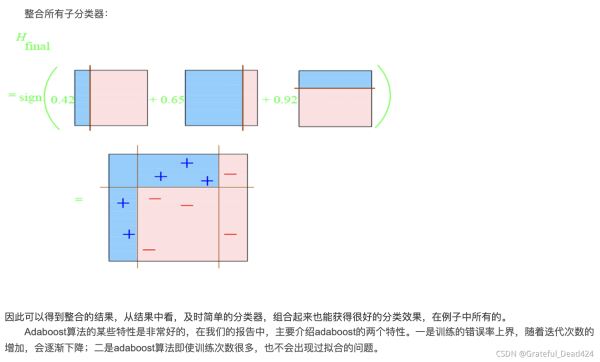
综上,将上面计算得到的a1、a2、a3各值代入G(x)中
G(x) = sign[f3(x)] = sign[ a1 * G1(x) + a2 * G2(x) + a3 * G3(x) ]
得到最终的分类器为:
G(x) = sign[f3(x)] = sign[ 0.4236G1(x) + 0.6496G2(x)+0.7514G3(x) ]
ada.predict(X)
结果:
array([ 1, 1, 1, -1, -1, -1, 1, 1, 1, -1])
y_predict = a1*ada[0].predict(X) + a2*ada[1].predict(X) +a3*ada[2].predict(X) y_predict np.sign(y_predict).astype(np.int)
array([ 1, 1, 1, -1, -1, -1, 1, 1, 1, -1])
以上就是python机器学习Sklearn实战adaboost算法示例详解的详细内容,更多关于机器学习Sklearn实战adaboost算法的资料请关注我们其它相关文章!
相关推荐
-
python实现AdaBoost算法的示例
代码 ''' 数据集:Mnist 训练集数量:60000(实际使用:10000) 测试集数量:10000(实际使用:1000) 层数:40 ------------------------------ 运行结果: 正确率:97% 运行时长:65m ''' import time import numpy as np def loadData(fileName): ''' 加载文件 :param fileName:要加载的文件路径 :return: 数据集和标签集 ''' # 存放数据及标记 da
-
人工智能机器学习常用算法总结及各个常用算法精确率对比
本文讲解了机器学习常用算法总结和各个常用分类算法精确率对比.收集了现在比较热门的TensorFlow.Sklearn,借鉴了Github和一些国内外的文章. 机器学习的知识树,这个图片是Github上的,有兴趣的可以自己去看一下: 地址:https://github.com/trekhleb/homemade-machine-learning 简单的翻译一下这个树: 英文 中文 Machine Learning 机器学习 Supervised Learning 监督学习 Unsupervised
-
机器学习10大经典算法详解
本文为大家分享了机器学习10大经典算法,供大家参考,具体内容如下 1.C4.5 C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法. C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进: 1)用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足: 2)在树构造过程中进行剪枝: 3)能够完成对连续属性的离散化处理: 4)能够对不完整数据进行处理. C4.5算法有如下优点:产生的分类规则易于理解,准确率较高.其缺点是:在构造树的过
-

Python机器学习工具scikit-learn的使用笔记
scikit-learn 是基于 Python 语言的机器学习工具 简单高效的数据挖掘和数据分析工具 可供大家在各种环境中重复使用 建立在 NumPy ,SciPy 和 matplotlib 上 开源,可商业使用 - BSD许可证 sklearn 中文文档:http://www.scikitlearn.com.cn/ 官方文档:http://scikit-learn.org/stable/ sklearn官方文档的类容和结构如下: sklearn是基于numpy和scipy的一个机器学习算法库,
-
Python机器学习入门(六)优化模型
目录 1.集成算法 1.1袋装算法 1.1.1袋装决策树 1.1.2随机森林 1.1.3极端随机树 1.2提升算法 1.2.1AdaBoost 1.2.2随机梯度提升 1.3投票算法 2.算法调参 2.1网络搜索优化参数 2.2随机搜索优化参数 总结 有时提升一个模型的准确度很困难.你会尝试所有曾学习过的策略和算法,但模型正确率并没有改善.这时你会觉得无助和困顿,这也正是90%的数据科学家开始放弃的时候.不过,这才是考验真正本领的时候!这也是普通的数据科学家和大师级数据科学家的差距所在. 1.集
-
Python机器学习之AdaBoost算法
一.算法概述 AdaBoost 是英文 Adaptive Boosting(自适应增强)的缩写,由 Yoav Freund 和Robert Schapire 在1995年提出. AdaBoost 的自适应在于前一个基本分类器分类错误的样本的权重会得到加强,加强后的全体样本再次被用来训练下一个基本分类器.同时,在每一轮训练中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数时停止训练. AdaBoost 算法是一种集成学习的算法,其核心思想就是对多个机器学习模型进行
-
python机器学习Sklearn实战adaboost算法示例详解
目录 pandas批量处理体测成绩 adaboost adaboost原理案例举例 弱分类器合并成强分类器 pandas批量处理体测成绩 import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt data = pd.read_excel("/Users/zhucan/Desktop/18级高一体测成绩汇总.xls") cond =
-
Python机器学习从ResNet到DenseNet示例详解
目录 从ResNet到DenseNet 稠密块体 过渡层 DenseNet模型 训练模型 从ResNet到DenseNet 上图中,左边是ResNet,右边是DenseNet,它们在跨层上的主要区别是:使用相加和使用连结. 最后,将这些展开式结合到多层感知机中,再次减少特征的数量.实现起来非常简单:我们不需要添加术语,而是将它们连接起来.DenseNet这个名字由变量之间的"稠密连接"而得来,最后一层与之前的所有层紧密相连.稠密连接如下图所示: 稠密网络主要由2部分构成:稠密块(den
-
Python+FuzzyWuzzy实现模糊匹配的示例详解
目录 1. 前言 2. FuzzyWuzzy库介绍 2.1 fuzz模块 2.2 process模块 3. 实战应用 3.1 公司名称字段模糊匹配 3.2 省份字段模糊匹配 4. 全部函数代码 在日常开发工作中,经常会遇到这样的一个问题:要对数据中的某个字段进行匹配,但这个字段有可能会有微小的差异.比如同样是招聘岗位的数据,里面省份一栏有的写“广西”,有的写“广西壮族自治区”,甚至还有写“广西省”……为此不得不增加许多代码来处理这些情况. 今天跟大家分享FuzzyWuzzy一个简单易用的模糊字符
-
python人工智能使用RepVgg实现图像分类示例详解
目录 摘要 安装包 安装timm 数据增强Cutout和Mixup EMA 项目结构 计算mean和std 生成数据集 摘要 RepVgg通过结构重参数化让VGG再次伟大. 所谓“VGG式”指的是: 没有任何分支结构.即通常所说的plain或feed-forward架构. 仅使用3x3卷积. 仅使用ReLU作为激活函数. RepVGG的更深版本达到了84.16%正确率!反超若干transformer! RepVgg是如何到的呢?简单地说就是: 首先, 训练一个多分支模型 然后,将多分支模型等价转
-
Python人工智能构建简单聊天机器人示例详解
目录 引言 什么是聊天机器人? 准备工作 创建聊天机器人 导入必要的库 定义响应集合 创建聊天机器人 运行聊天机器人 完整代码 结论 展望 引言 人工智能是计算机科学中一个非常热门的领域,近年来得到了越来越多的关注.它通过模拟人类思考过程和智能行为来实现对复杂任务的自主处理和学习,已经被广泛应用于许多领域,包括语音识别.自然语言处理.机器人技术.图像识别和推荐系统等. 本文将介绍如何使用Python构建一个简单的聊天机器人,以展示人工智能的基本原理和应用.我们将使用Python语言和自然语言处理
-
Python编程实现粒子群算法(PSO)详解
1 原理 粒子群算法是群智能一种,是基于对鸟群觅食行为的研究和模拟而来的.假设在鸟群觅食范围,只在一个地方有食物,所有鸟儿看不到食物(不知道食物的具体位置),但是能闻到食物的味道(能知道食物距离自己位置).最好的策略就是结合自己的经验在距离鸟群中距离食物最近的区域搜索. 利用粒子群算法解决实际问题本质上就是利用粒子群算法求解函数的最值.因此需要事先把实际问题抽象为一个数学函数,称之为适应度函数.在粒子群算法中,每只鸟都可以看成是问题的一个解,这里我们通常把鸟称之为粒子,每个粒子都拥有: 位置,可
-
python实现三壶谜题的示例详解
前言 有一个充满水的8品脱的水壶和两个空水壶(容积分别是5品脱和3品脱).通过将水壶完全倒满水和将水壶的水完全倒空这两种方式,在其中的一个水壶中得到4品脱的水. 一.算法思想 算法分析 采用的算法思想是将某个时刻水壶中水的数量看作一个状态,用一个长度为3的数组表示. 初始状态便为[8,0,0],再拓展他的下一结点的可能结构. 若下一结点的结构已经被拓展过了便放弃,若没有拓展过则加入拓展列表(open_list)中.然后递归上述操作. 直到拓展列表(open_list)为空或者找到目标为止. 思想
-
Python实现过迷宫小游戏示例详解
目录 前言 开发工具 环境搭建 原理简介 主要代码 前言 今天为大家带来解闷用的过迷宫小游戏分享给大家好了.让我们愉快地开始吧~ 开发工具 Python版本: 3.6.4 相关模块: pygame模块: 以及一些Python自带的模块. 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 原理简介 游戏规则: 玩家通过↑↓←→键控制主角行动,使主角从出发点(左上角)绕出迷宫,到达终点(右下角)即为游戏胜利. 逐步实现: 首先,当然是创建迷宫啦,为了方便,这里采用随机生成迷
-
Python机器学习应用之决策树分类实例详解
目录 一.数据集 二.实现过程 1 数据特征分析 2 利用决策树模型在二分类上进行训练和预测 3 利用决策树模型在多分类(三分类)上进行训练与预测 三.KEYS 1 构建过程 2 划分选择 3 重要参数 一.数据集 小企鹅数据集,提取码:1234 该数据集一共包含8个变量,其中7个特征变量,1个目标分类变量.共有150个样本,目标变量为 企鹅的类别 其都属于企鹅类的三个亚属,分别是(Adélie, Chinstrap and Gentoo).包含的三种种企鹅的七个特征,分别是所在岛屿,嘴巴长度,
-
Python机器学习应用之工业蒸汽数据分析篇详解
目录 一.数据集 二.数据分析 1 数据导入 2 数据特征探索(数据可视化) 三.特征优化 四.对特征构造后的训练集和测试集进行主成分分析 五.使用LightGBM模型进行训练和预测 一.数据集 1. 训练集 提取码:1234 2. 测试集 提取码:1234 二.数据分析 1 数据导入 #%%导入基础包 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from