Python实现从文件中加载数据的方法详解
前几篇都是手动录入或随机函数产生的数据。实际有许多类型的文件,以及许多方法,用它们从文件中提取数据来图形化。
比如之前python基础(12)介绍打开文件的方式,可直接读取文件中的数据,扩大了我们的数据来源。下面,将展示几种方法。
我们将使用内置的 csv 模块加载CSV文件
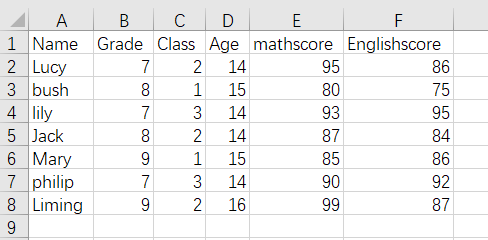
CSV文件是一种特殊的文本文件,文件中的数据以逗号作为分隔符,很适合进行数据的解析。先用excle建立如下表格和数据,另存为csv格式文件,放到代码目录下。
包含在Python标准库中自带CSV 模块,我们只需要import进来就能使用。比如我们需要将上面的CSV文件都打印出来,代码 如下:
import csv #import csv 用来导入csv模块
filename = 'E:\WorkSpace\python\coding\score.csv' #文件保存的绝对路径
with open(filename) as file_csv: #是不是忘记了如何打开文件?打开文件,并将结果文件对象存储在file_csv中
reader = csv.reader(file_csv) #直接调读取 用csv.read()读取文件内容
for row in reader: # 用for循环打印每一行
print(row)
运行结果如下:
['Name', 'Grade', 'Class', 'Age', 'mathscore', 'Englishscore']
['Lucy', '7', '2', '14', '95', '86']
['bush', '8', '1', '15', '80', '75']
['lily', '7', '3', '14', '93', '95']
['Jack', '8', '2', '14', '87', '84']
['Mary', '9', '1', '15', '85', '86']
['philip', '7', '3', '14', '90', '92']
['Liming', '9', '2', '16', '99', '87']
打印文件头及其位置
读入文件,是为了获取其中的数据,需要将相关信息进行分离,先看看如何读出头即文件的第一行, next()返回文件中的下一行。
import csv #import csv 用来导入csv模块
filename = 'E:\WorkSpace\python\coding\score.csv' #文件保存的绝对路径
with open(filename) as file_csv: #是不是忘记了如何打开文件?打开文件,并将结果文件对象存储在file_csv中
reader = csv.reader(file_csv) #直接调读取 用csv.read()读取文件内容
header_row = next(reader) #模块csv包含函数 next() ,调用它并将阅读器对象传递给它时,它将返回文件中的下一行。
#调用了next()一次,因此得到的是文件的第一行,其中包含文件头
#for row in reader: # 用for循环打印每一行 # print(row)
for index, column_header in enumerate(header_row): #对列表调用了enumerate()来获取每个元素的索引及其值
print(index, column_header)
运行后的结果如下所示:
0 Name
1 Grade
2 Class
3 Age
4 mathscore
5 Englishscore
提取其中索引,即name的索引为0,Grade的索引为1,知道了索引便可以读取其中的任何数据,比如我们要打印出mathscore,索引为4,于是代码如下:
scores =[] 定义一个空的list
for row in reader:
scores.append(int(row[4])) #读取的文件,默认为字符串,用int()转换为数字。
print(scores)
运行结果:
[95, 80, 93, 87, 85, 90, 99]
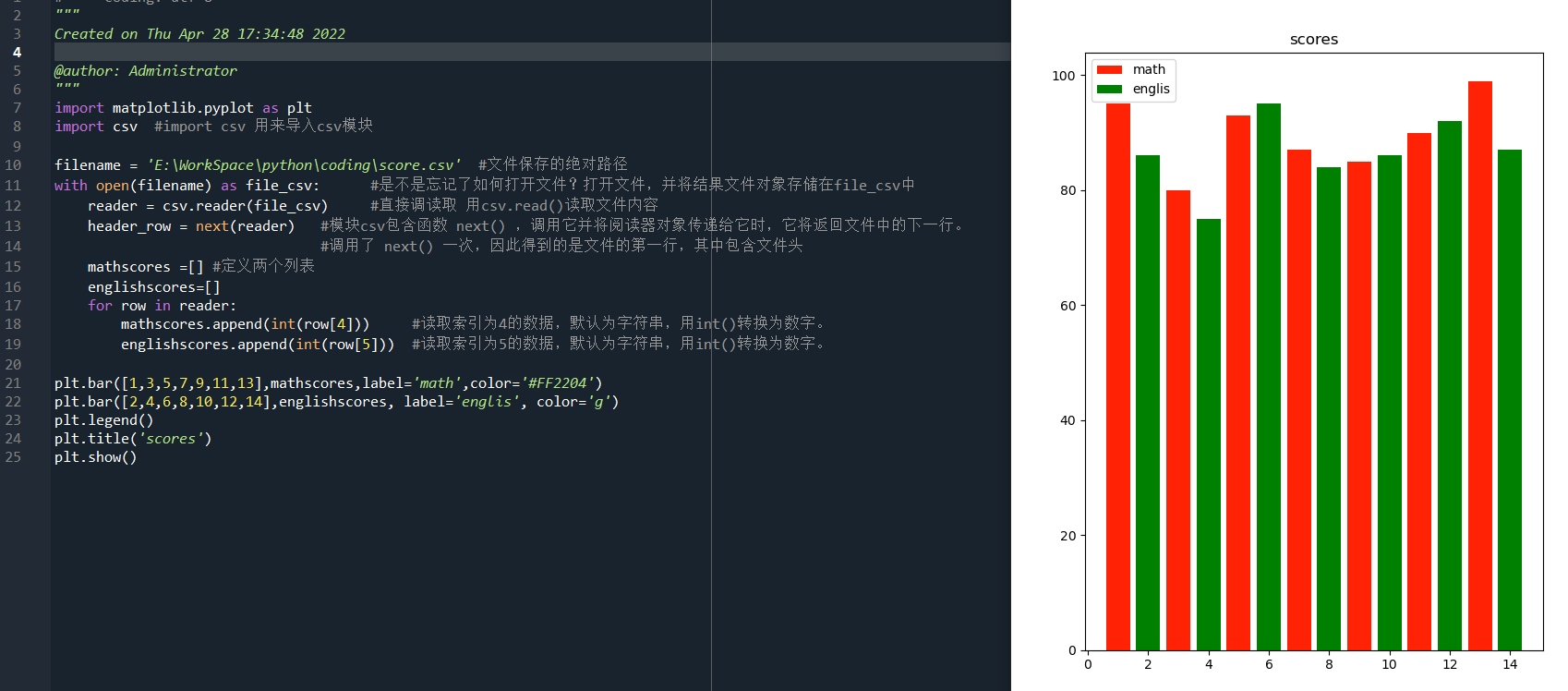
接下来,制作图表展示一下,先把mathscore和englishscore分数做个柱状对比。代码如下:
import matplotlib.pyplot as plt
import csv #import csv 用来导入csv模块
filename = 'E:\WorkSpace\python\coding\score.csv' #文件保存的绝对路径
with open(filename) as file_csv: #是不是忘记了如何打开文件?打开文件,并将结果文件对象存储在file_csv中
reader = csv.reader(file_csv) #直接调读取 用csv.read()读取文件内容
header_row = next(reader) #模块csv包含函数 next() ,调用它并将阅读器对象传递给它时,它将返回文件中的下一行。
#调用了 next() 一次,因此得到的是文件的第一行,其中包含文件头
mathscores =[] #定义两个列表
englishscores=[]
for row in reader:
mathscores.append(int(row[4])) #读取索引为4的数据,默认为字符串,用int()转换为数字。
englishscores.append(int(row[5])) #读取索引为5的数据,用int()转换为数字。
plt.bar([1,3,5,7,9,11,13],mathscores,label='math',color='#FF2204')
plt.bar([2,4,6,8,10,12,14],englishscores, label='englis', color='g')
plt.legend()
plt.title('scores')
plt.show()
已将那些打印相关代码删除。看运行结果:
接下来,我们读取文件 ,并根据文件中的时间来绘制图表
新建一个年份的数据(真的是胡编乱造的数据),第一列是年份,第二列每年毕业的人数,第三列是每年申请人数,如图所示:
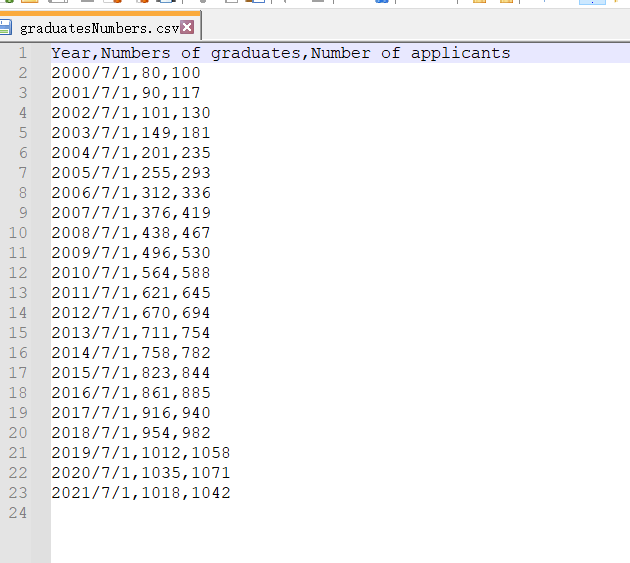
要求:
1,按年份分别显示出每年两者的人数,并用不同的颜色表示;
2、两者间也用其他颜色进行填充。
完成代码如下:
import matplotlib.pyplot as plt
import csv #import csv 用来导入csv模块
from datetime import datetime #引入时间相关模块
filename = 'E:\WorkSpace\python\coding\graduatesNumbers.csv' #文件保存的绝对路径
with open(filename) as file_csv: #是不是忘记了如何打开文件?打开文件,并将结果文件对象存储在file_csv中
reader = csv.reader(file_csv) #直接调读取 用csv.read()读取文件内容
header_row = next(reader)
dates=[]
numbers=[]
application_numbers=[]
for row in reader:
current_date = datetime.strptime(row[0], "%Y/%m/%d") #年份,strptime()日期格式转化为字符串格式的函数
dates.append(current_date)
numbers.append(int(row[1])) #读取索引为1的数据,默认为字符串,用int()转换为数字,即Numbers of graduates 。
application_numbers.append(int(row[2])) #读取索引为2的数据,即Number of applicants
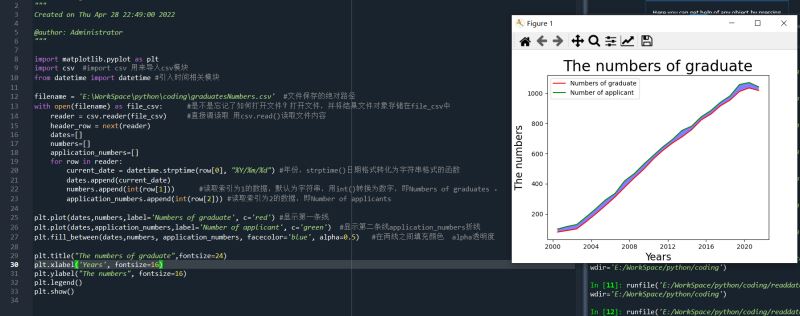
plt.plot(dates,numbers,label='Numbers of graduate', c='red') #显示第一条线
plt.plot(dates,application_numbers,label='Number of applicant', c='green') #显示第二条线application_numbers折线
plt.fill_between(dates,numbers, application_numbers, facecolor='blue', alpha=0.5) #在两线之间填充颜色 alpha透明度
plt.title("The numbers of graduate",fontsize=24)
plt.xlabel('Years', fontsize=16)
plt.ylabel("The numbers", fontsize=16)
plt.legend()
plt.show()
实际运行结果如下:
以上就是Python实现从文件中加载数据的方法详解的详细内容,更多关于Python 加载数据的资料请关注我们其它相关文章!
相关推荐
-
python 使用matplotlib 实现从文件中读取x,y坐标的可视化方法
1. test.txt文件,数据以逗号分割,第一个数据为x坐标,第二个为y坐标,数据如下:1.1,2 2.1,2 3.1,3 4.1,5 40,38 42,41 43,42 2. python部分代码 #!/usr/bin/python # coding: utf-8 import matplotlib.pyplot as plt import numpy as np import matplotlib as mpl mpl.rcParams['font.family'] = 'sans-ser
-
利用python进行数据加载
前言 最近参加了datawhale的组队学习活动,在组队学习动员下,开始通过强迫自己输出来实现更好的输入与处理,6-15开始自己的第一次文章发布,我会把自己这个真的很小白遇到的问题写出来,希望能给屏幕前小白的你带来帮助. 工作中大量繁琐的自动化,把以前在学校摸过的python重新捡起来,不成体系的.拼图一样把需要的工作搭建起来,工作暂时是可用上了,每天节省了至少3个小时的数据处理工作,手里拿着python这个锤子,看什么都像钉子. 首先,你要先学会安装软件,anaconda软件,安装成功后,你点
-
Python加载数据的5种不同方式(收藏)
数据是数据科学家的基础,因此了解许多加载数据进行分析的方法至关重要.在这里,我们将介绍五种Python数据输入技术,并提供代码示例供您参考. 作为初学者,您可能只知道一种使用p andas.read_csv函数读取数据的方式(通常以CSV格式).它是最成熟,功能最强大的功能之一,但其他方法很有帮助,有时肯定会派上用场. 我要讨论的方法是: Manual 函数 loadtxt 函数 genfromtxtf 函数 read_csv 函数 Pickle 我们将用于加载数据的数据集可以在此处找到 .它被
-

Python实现实时增量数据加载工具的解决方案
目录 创建增量ID记录表 数据库连接类 增量数据服务客户端 结果测试 本次主要分享结合单例模式实际应用案例:实现实时增量数据加载工具的解决方案.最关键的是实现一个可进行添加.修改.删除等操作的增量ID记录表. 单例模式:提供全局访问点,确保类有且只有一个特定类型的对象.通常用于以下场景:日志记录或数据库操作等,避免对用一资源请求冲突. 创建增量ID记录表 import sqlite3 import datetime import pymssql import pandas as pd impor
-
Python Pytorch深度学习之数据加载和处理
目录 一.下载安装包 二.下载数据集 三.读取数据集 四.编写一个函数看看图像和landmark 五.数据集类 六.数据可视化 七.数据变换 1.Function_Rescale 2.Function_RandomCrop 3.Function_ToTensor 八.组合转换 九.迭代数据集 总结 一.下载安装包 packages: scikit-image:用于图像测IO和变换 pandas:方便进行csv解析 二.下载数据集 数据集说明:该数据集(我在这)是imagenet数据集标注为fac
-
Python实现从文件中加载数据的方法详解
前几篇都是手动录入或随机函数产生的数据.实际有许多类型的文件,以及许多方法,用它们从文件中提取数据来图形化. 比如之前python基础(12)介绍打开文件的方式,可直接读取文件中的数据,扩大了我们的数据来源.下面,将展示几种方法. 我们将使用内置的 csv 模块加载CSV文件 CSV文件是一种特殊的文本文件,文件中的数据以逗号作为分隔符,很适合进行数据的解析.先用excle建立如下表格和数据,另存为csv格式文件,放到代码目录下. 包含在Python标准库中自带CSV 模块,我们只需要impor
-
Android开发实现ListView异步加载数据的方法详解
本文实例讲述了Android开发实现ListView异步加载数据的方法.分享给大家供大家参考,具体如下: 1.主Activity public class MainActivity extends Activity { private ListView listView; private ArrayList<Person> persons; private ListAdapter adapter; private Handler handler=null; //xml文件的网络地址 final
-
Python快速从视频中提取视频帧的方法详解
目录 1.抽取视频帧 2.多线程方法 3.整体代码 补充 Python快速提取视频帧(多线程) 今天介绍一种从视频中抽取视频帧的方法,由于单线程抽取视频帧速度较慢,因此这里我们增加了多线程的方法. 1.抽取视频帧 抽取视频帧主要使用了 Opencv 模块. 其中: camera = cv2.Videocapture( ) ,函数主要是通过调用笔记本内置摄像头读取视频帧: res, image = camera.read( ) 函数主要是按帧读取视频,返回值 “res” 是布尔型,成功读取返回 T
-
Vue首页界面加载优化实现方法详解
目录 1.路由懒加载 2.js 资源异步加载 3.图片懒加载 4.组件分包懒加载-在视口才加载 1.路由懒加载 问题: 项目在打包时会将首页与其他页面的资源打包到同一个资源文件,造成首页加载的资源文件过大. 解决方法: 路由懒加载:打包时会将每个路由页面拆分成单独的 js 资源,同时跳转到对应页面才会加载对应路由的 js 资源. { path: "/about", name: "about", component: () => import(/* webpac
-
Mongodb中MapReduce实现数据聚合方法详解
Mongodb是针对大数据量环境下诞生的用于保存大数据量的非关系型数据库,针对大量的数据,如何进行统计操作至关重要,那么如何从Mongodb中统计一些数据呢? 在Mongodb中,给我们提供了三种用于数据聚合的方式: (1)简单的用户聚合函数: (2)使用aggregate进行统计: (3)使用mapReduce进行统计: 今天我们首先来讲讲mapReduce是如何统计,在后续的文章中,将另起文章进行相关说明. MapReduce是啥呢?以我的理解,其实就是对集合中的各个满足条件的文档进行预处理
-
PHP中的自动加载操作实现方法详解
本文实例讲述了PHP中的自动加载操作实现方法.分享给大家供大家参考,具体如下: what is 自动加载? 或许你已经对自动加载有所了解.简单描述一下:自动加载就是我们在new一个class的时候,不需要手动去写require来导入这个class.php文件,程序自动帮我们加载导入进来.这是php5.1.2(好像是)版本新加入一个功能,他解放了程序员的双手,不需要手动写那么多的require,变得有那么点智能的感觉. 自动加载可以说是现代PHP框架的根基,任何牛逼的框架或者架构都会用到它,它发明
-
Element Plus的el-tree-select组件懒加载+数据回显详解
目录 一.背景说明 二.使用 1. dom 2.methods 三.回显 总结 一.背景说明 技术:Vue3 + Element Plus 需求:在选择组织机构时以树结构下拉展示. 用到组件:TreeSelect 树形选择组件(el-tree-select) 官网文档地址: https://element-plus.gitee.io/zh-CN/component/tree-select.html https://element-plus.gitee.io/zh-CN/component/tre
-
Python找出文件中使用率最高的汉字实例详解
本文实例讲述了Python找出文件中使用率最高的汉字的方法.分享给大家供大家参考.具体分析如下: 这是我初学Python时写的,为了简便,我并没在排序完后再去掉非中文字符,稍微会影响性能(大约增加了25%的时间). # -*- coding: gbk -*- import codecs from time import time from operator import itemgetter def top_words(filename, size=10, encoding='gbk'): co
-
Laravel5.4框架中视图共享数据的方法详解
本文实例讲述了Laravel5.4框架中视图共享数据的方法.分享给大家供大家参考,具体如下: 每个人都会遇到这种情况:某些数据还在每个页面进行使用,比如用户信息,或者菜单数据,最基本的做法是在每个视图空控制器中传入这些数据,但显然并不是我们想要的结果.另一种方法就是使用视图数据共享,视图数据共享的基本使用很简单,可查看视图文档了解详情,这里我们演示两个使用示例:在视图间共享数据和视图Composer 在视图中共享数据 除了在单个视图中传递指定数据之外,有时候需要在所有视图中传入同一数据,即我们需
-
Vue 实现从文件中获取文本信息的方法详解
本文实例讲述了Vue 实现从文件中获取文本信息的方法.分享给大家供大家参考,具体如下: 最近在使用vue做项目的时候,遇到一个需求,界面中需要显示大量的说明文字,为了保持界面的整洁和赶紧,决定采用单独的文件来存储显示信息,然后通过文件读取的方式显示到界面上. 刚开始我使用的是File和FileReader对象获取,但是比较气人的是这两个对象是IE浏览器特有的属性,chrome不支持,而且为了安全起见,现在浏览器是不推崇这种做法的,因为很容易造成文件被外部恶意删除或增加内容,安全性太低.无奈之下,