python神经网络slim常用函数训练保存模型
目录
- 学习前言
- slim是什么
- slim常用函数
- 1、slim = tf.contrib.slim
- 2、slim.create_global_step
- 3、slim.dataset.Dataset
- 4、slim.dataset_data_provider.DatasetDataProvider
- 5、slim.conv2d
- 6、slim.max_pool2d
- 7、slim.fully_connected
- 8、slim.learning.train
- 本次博文实现的目标
- 整体框架构建思路
- 1、整体框架
- 2、网络构建Net.py
- 3、进行模型训练CNN.py
- 4、训练结果
学习前言
在SSD的框架中,除去tfrecord处理是非常重要的一环之外,slim框架的使用也是非常重要的一环,于是我开始学习slim啦
slim是什么
slim的英文本意是苗条的意思,其实在tensorflow中,它相当于就是tensorflow简洁版的意思,直接使用tensorflow构建代码可能会比较复杂,使用slim可以将一些tensorflow代码合并在一起,其具体作用与keras类似。
但是相比Keras,slim更加贴近tensorflow原生,其更加轻量级。
TF-Slim是tensorflow中定义、训练和评估复杂模型的轻量级库。tf-slim中的组件可以轻易地和原生tensorflow框架以及例如tf.contrib.learn这样的框架进行整合。
slim常用函数
1、slim = tf.contrib.slim
slim = tf.contrib.slim用于在python中声明slim框架的对象,只有完成该声明后才可以利用slim框架构建tensorflow神经网络。
2、slim.create_global_step
该函数用于生成全局步数,全局步数可以用于学习率的自适应衰减。
3、slim.dataset.Dataset
该函数用于从tfrecords类型的文件中获取数据,实际上是利用该数据生成了一个数据库,在slim之后训练时可以从中获取数据用于训练。常见的Dataset使用方式如下:
slim.dataset.Dataset(
data_sources=record_path,
reader=reader,
decoder=decoder,
num_samples=num_samples,
num_classes=num_classes,
items_to_descriptions=items_to_descriptions,
labels_to_names=labels_to_names)
其中:
- file_pattern指向tfrecords文件的位置;
- reader默认是tf.TFRecordReader,也就是tensorflow支持的tfrecord读取器;
- decoder指的是如何将tfrecord文件里的内容解码成自己需要的内容;
- num_samples指的是tfrecord文件里一共具有多少个样本;
- items_to_descriptions是解码后每个项目的描述;
- num_classes是值一共有多少个种类
其内部参数具体的设置方式如下,本段代码主要是对神经网络学习tfrecords文件的写入、读取及其内容解析中MNIST数据集进行slim数据库的构建,如果不知道如何构建tfrecord文件的可以看我的上一篇博文。
def get_record_dataset(record_path,
reader=None, image_shape=[784],
num_samples=55000, num_classes=10):
if not reader:
reader = tf.TFRecordReader
keys_to_features = {
'image/encoded': tf.FixedLenFeature([784], tf.float32, default_value=tf.zeros([784], dtype=tf.float32)),
'image/class/label':tf.FixedLenFeature([1], tf.int64,
default_value=tf.zeros([1], dtype=tf.int64))}
items_to_handlers = {
'image': slim.tfexample_decoder.Tensor('image/encoded', shape = [784]),
'label': slim.tfexample_decoder.Tensor('image/class/label', shape=[])}
decoder = slim.tfexample_decoder.TFExampleDecoder(
keys_to_features, items_to_handlers)
labels_to_names = None
items_to_descriptions = {
'image': 'An image with shape image_shape.',
'label': 'A single integer between 0 and 9.'}
return slim.dataset.Dataset(
data_sources=record_path,
reader=reader,
decoder=decoder,
num_samples=num_samples,
num_classes=num_classes,
items_to_descriptions=items_to_descriptions,
labels_to_names=labels_to_names)
本段代码分别对image和label进行读取。
其中:
- items_to_handlers指的是数据在tfrecords中的存储方式;
- items_to_handlers指的是数据解码后的格式;
- decoder用于将items_to_handlers与items_to_handlers结合使用;
- items_to_descriptions是解码后每个数据的描述。
4、slim.dataset_data_provider.DatasetDataProvider
上一步的函数构成的是数据库,但是如何从数据库里面读取数据我们还不知道,实际上slim已经给了一个函数作为数据库的接口,利用该函数可以生成provider,顾名思义,provider就是数据库向外界提供数据的接口。
具体使用方式如下:
# 创建provider
provider = slim.dataset_data_provider.DatasetDataProvider(
dataset,
num_readers= FLAGS.num_readers,
common_queue_capacity=20*FLAGS.batch_size,
common_queue_min=10*FLAGS.batch_size,
shuffle=True)
# 在提供商处获取image
image, label = provider.get(['image', 'label'])
其中:
- dataset就是数据库;
- num_readers指的是使用的并行读取器的数量;
- common_queue_capacity指的是公共队列的容量;
- common_queue_min指的是公共队列出队后的最小元素个数;
- shuffle指的是读取时是否打乱顺序。
在提供商处获取image后,可以利用tf.train.batch分批次获取训练集。
inputs, labels = tf.train.batch([image, label],
batch_size=FLAGS.batch_size,
allow_smaller_final_batch=True,
num_threads=FLAGS.num_readers,
capacity=FLAGS.batch_size*5)
其中:
- batch_size指的是每一个批次训练集的数量;
- allow_smaller_final_batch指的是是否允许存在batch小于batch_size的数据集;
- num_threads指的是用的线程数;
- capacity一个整数,用来设置队列中元素的最大数量。
tf.train.batch具体的使用方法可以参照我的另一篇博文神经网络之批量学习tf.train.batch
此时获得的inputs, labels可以在下一步传入网络了。
5、slim.conv2d
slim.conv2d用于构建卷积层,其具体的代码如下:
slim.conv2d(inputs,
num_outputs,
kernel_size,
stride=1,
padding='SAME',
data_format=None,
rate=1,
activation_fn=nn.relu,
normalizer_fn=None,
normalizer_params=None,
weights_initializer=initializers.xavier_initializer(),
weights_regularizer=None,
biases_initializer=init_ops.zeros_initializer(),
biases_regularizer=None,
reuse=None,
variables_collections=None,
outputs_collections=None,
trainable=True,
scope=None)
其中参数很多,常用的参数解析如下:
- inputs指的是需要做卷积的输入图像;
- num_outputs指的是卷积核的个数,也就输出net的channels数量;
- kernel_size指的是卷积核的维度,用一个列表或元组表示;
- stride指的是卷积时在图像每一维的步长;
- padding使用VALID或者SAME;
- data_format指的是输入的input的格式,NCHW 与 NHWC;
- rate指的是使用空洞卷积的膨胀率;
- activation_fn指的是激活函数的种类,默认的为ReLU函数;
- normalizer_fn指的是正则化函数;
- reuse指的是是否共享层或者和变量;
- trainable指的是卷积层的参数是否可被训练;
- scope指的是共享变量所指的variable_scope。
6、slim.max_pool2d
slim.max_pool2d用于最大池化,具体代码如下:
slim.fully_connected(inputs,
num_outputs,
activation_fn=nn.relu,
normalizer_fn=None,
normalizer_params=None,
weights_initializer=initializers.xavier_initializer(),
weights_regularizer=None,
biases_initializer=init_ops.zeros_initializer(),
biases_regularizer=None,
reuse=None,
variables_collections=None,
outputs_collections=None,
trainable=True,
scope=None)
其中:
- inputs指的是指需要做卷积的输入图像;
- kernel_size指的是池化核的维度,用一个列表或元组表示;
- stride指的是池化的步长;
- padding使用VALID或者SAME;
- data_format支持’ NHWC ‘(默认值)和’ NCHW ';
- scope指的是name_scope的可选作用域。
7、slim.fully_connected
slim.fully_connected用于定义全连接层。
具体代码如下:
slim.fully_connected(inputs,
num_outputs,
activation_fn=nn.relu,
normalizer_fn=None,
normalizer_params=None,
weights_initializer=initializers.xavier_initializer(),
weights_regularizer=None,
biases_initializer=init_ops.zeros_initializer(),
biases_regularizer=None,
reuse=None,
variables_collections=None,
outputs_collections=None,
trainable=True,
scope=None)
其中:
- inputs指的是指需要全连接的数据;
- num_outputs指的是输出的维度;
- activation_fn指的是激活函数;
- weights_initializer指的是权值初始化方法;
- biases_initializer指的是阈值初始化方法;
- trainable指的是是否可以训练;
- scope指的是name_scope的可选作用域。
8、slim.learning.train
该函数用于将训练托管给slim框架进行,非常好用,具体使用代码如下。
slim.learning.train(
train_op,
logdir=FLAGS.train_dir,
master='',
is_chief=True,
number_of_steps = FLAGS.max_number_of_steps,
log_every_n_steps = FLAGS.log_every_n_steps,
save_summaries_secs= FLAGS.save_summaries_secs,
saver=saver,
save_interval_secs = FLAGS.save_interval_secs,
session_config=config,
sync_optimizer=None)
其中:
- train_op为训练对象,可以利用slim.learning.create_train_op构建;
- logdir为模型训练产生日志的地址;
- master指的是tensorflow master的地址;
- is_chief指的是是否在主要副本上运行training;
- number_of_steps指的是训练时最大的梯度更新次数,当global step大于这个值时,停止训练。如果这个值为None,则训练不会停止下来;
- log_every_n_steps指的是多少步在cmd上进行显示;
- save_summaries_secs指的是多久进行一次数据的summaries;
- saver指的是保存模型的方法;
- save_interval_secs指的是多久保存一次模型;
- session_config指的是tf.ConfigProto的一个实例,用于配置Session;
- sync_optimizer指的是tf.train.SyncReplicasOptimizer的一个实例,或者这个实例的一个列表。如果这个参数被更新,则梯度更新操作将同步进行。如果为None,则梯度更新操作将异步进行。
其使用的参数较多,具体配置方式如下,并不复杂:
# 获得损失值
loss = Conv_Net.get_loss(labels=labels,logits = logits)
# 学习率多久衰减一次
decay_steps = int(dataset.num_samples / FLAGS.batch_size *
FLAGS.num_epochs_per_decay)
# 学习率指数下降
learning_rate = tf.train.exponential_decay(FLAGS.learning_rate,
global_step,
decay_steps,
FLAGS.learning_rate_decay_factor,
staircase=False,
name='exponential_decay_learning_rate')
# 优化器
optimizer = tf.train.AdamOptimizer(learning_rate)
# 构建训练对象
train_op = slim.learning.create_train_op(loss, optimizer,
summarize_gradients=False)
# gpu使用比率
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=FLAGS.gpu_memory_fraction,
allow_growth = True)
# 参数配置
config = tf.ConfigProto(allow_soft_placement=True,
log_device_placement=False,
gpu_options=gpu_options)
# 保存方式
saver = tf.train.Saver(max_to_keep=5,
keep_checkpoint_every_n_hours=1.0,
write_version=2,
pad_step_number=False)
本次博文实现的目标
本次博文主要是利用slim构建了一个卷积神经网络,用于手写体的识别,经过20000次训练后,精度达到99.2%。
具体的代码可以点击下载
已经存储好的tfrecords也可以点击下载
整体框架构建思路
1、整体框架
整个思路的构建如下图所示:
其中:
- Net.py是网络的主体;
- CNN.py进行模型训练的主体;
- Load_Predict.py是如何用模型进行预测(下一个博文讲解);
- TFrecord_read和TF_record_write主要是用于tfrecord文件的生成。
2、网络构建Net.py
网络构建部分的函数比较简单,主要是设计了一个对象用于读取网络结构,网络结构比较简单,其shape变化如下:
(28,28,1)=>(28,28,32)=>(14,14,32)=>(14,14,64)=>(7,7,64)=>(3136)=>(1024)=>(10)
import tensorflow as tf
import numpy as np
# 创建slim对象
slim = tf.contrib.slim
class Conv_Net(object):
def net(self,inputs):
with tf.variable_scope("Net"):
# 第一个卷积层
net = slim.conv2d(inputs,32,[5,5],padding = "SAME",scope = 'conv1_1')
net = slim.max_pool2d(net,[2,2],stride = 2,padding = "SAME",scope = 'pool1')
# 第二个卷积层
net = slim.conv2d(net,64,[3,3],padding = "SAME",scope = 'conv2_1')
net = slim.max_pool2d(net,[2,2],stride = 2,padding = "SAME",scope = 'pool2')
net = tf.reshape(net,[-1,7*7*64])
# 全连接层
layer1 = slim.fully_connected(net,512,scope = 'fully1')
layer1 = slim.dropout(layer1, 0.5, scope='dropout1')
# 这里的layer3忘了改成layer2了,试了很多结构,这个比较好
layer3 = slim.fully_connected(layer1,10,activation_fn=tf.nn.softmax,scope = 'fully3')
return layer3
def get_loss(self,labels,logits):
with tf.variable_scope("loss"):
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels,logits = logits),name = 'loss')
tf.summary.scalar("loss",loss)
return loss
3、进行模型训练CNN.py
进行模型训练CNN.py中的训练过程主要是模仿SSD的训练过程的框架构成的,如果大家对SSD有疑问,欢迎大家看我的博文SSD算法训练部分详解。
其具体的训练如下:
1、设定训练参数。
2、读取MNIST数据集。
3、建立卷积神经网络。
4、将数据集的image通过神经网络,获得prediction。
5、利用prediction和实际label获得loss。
6、利用优化器完成梯度下降并保存模型。
具体代码如下,其中所有执行步骤已经利用如下格式隔开:
############################################################# # XXXXXXXXXXXXX #############################################################
import tensorflow as tf
import numpy as np
from nets import Net
flags = tf.app.flags
#############################################################
# 设置训练参数
#############################################################
# =========================================================================== #
# General Flags.
# =========================================================================== #
# train_dir用于保存训练后的模型和日志
tf.app.flags.DEFINE_string(
'train_dir', './logs',
'Directory where checkpoints and event logs are written to.')
# num_readers是在对数据集进行读取时所用的平行读取器个数
tf.app.flags.DEFINE_integer(
'num_readers', 4,
'The number of parallel readers that read data from the dataset.')
# 在进行训练batch的构建时,所用的线程数
tf.app.flags.DEFINE_integer(
'num_preprocessing_threads', 4,
'The number of threads used to create the batches.')
# 每十步进行一次log输出,在窗口上
tf.app.flags.DEFINE_integer(
'log_every_n_steps', 100,
'The frequency with which logs are print.')
# 每150秒存储一次记录
tf.app.flags.DEFINE_integer(
'save_summaries_secs', 150,
'The frequency with which summaries are saved, in seconds.')
# 每150秒存储一次模型
tf.app.flags.DEFINE_integer(
'save_interval_secs', 150,
'The frequency with which the model is saved, in seconds.')
# 可以使用的gpu内存数量
tf.app.flags.DEFINE_float(
'gpu_memory_fraction', 0.6, 'GPU memory fraction to use.')
# =========================================================================== #
# Learning Rate Flags.
# =========================================================================== #
# 学习率衰减的方式,有固定、指数衰减等
tf.app.flags.DEFINE_string(
'learning_rate_decay_type',
'exponential',
'Specifies how the learning rate is decayed. One of "fixed", "exponential",'
' or "polynomial"')
# 初始学习率
tf.app.flags.DEFINE_float('learning_rate', 0.001, 'Initial learning rate.')
# 结束时的学习率
tf.app.flags.DEFINE_float(
'end_learning_rate', 0.0001,
'The minimal end learning rate used by a polynomial decay learning rate.')
tf.app.flags.DEFINE_float(
'label_smoothing', 0.0, 'The amount of label smoothing.')
# 学习率衰减因素
tf.app.flags.DEFINE_float(
'learning_rate_decay_factor', 0.94, 'Learning rate decay factor.')
tf.app.flags.DEFINE_float(
'num_epochs_per_decay', 2.0,
'Number of epochs after which learning rate decays.')
tf.app.flags.DEFINE_float(
'moving_average_decay', None,
'The decay to use for the moving average.'
'If left as None, then moving averages are not used.')
# adam参数
tf.app.flags.DEFINE_float(
'adam_beta1', 0.9,
'The exponential decay rate for the 1st moment estimates.')
tf.app.flags.DEFINE_float(
'adam_beta2', 0.999,
'The exponential decay rate for the 2nd moment estimates.')
tf.app.flags.DEFINE_float('opt_epsilon', 1.0, 'Epsilon term for the optimizer.')
# =========================================================================== #
# Dataset Flags.
# =========================================================================== #
# 数据集目录
tf.app.flags.DEFINE_string(
'dataset_dir', './record/output.tfrecords', 'The directory where the dataset files are stored.')
# 每一次训练batch的大小
tf.app.flags.DEFINE_integer(
'batch_size', 100, 'The number of samples in each batch.')
# 最大训练次数
tf.app.flags.DEFINE_integer('max_number_of_steps', 20000,
'The maximum number of training steps.')
FLAGS = flags.FLAGS
def get_record_dataset(record_path,
reader=None, image_shape=[784],
num_samples=55000, num_classes=10):
if not reader:
reader = tf.TFRecordReader
keys_to_features = {
'image/encoded': tf.FixedLenFeature([784], tf.float32, default_value=tf.zeros([784], dtype=tf.float32)),
'image/class/label':tf.FixedLenFeature([1], tf.int64,
default_value=tf.zeros([1], dtype=tf.int64))}
items_to_handlers = {
'image': slim.tfexample_decoder.Tensor('image/encoded', shape = [784]),
'label': slim.tfexample_decoder.Tensor('image/class/label', shape=[])}
decoder = slim.tfexample_decoder.TFExampleDecoder(
keys_to_features, items_to_handlers)
labels_to_names = None
items_to_descriptions = {
'image': 'An image with shape image_shape.',
'label': 'A single integer between 0 and 9.'}
return slim.dataset.Dataset(
data_sources=record_path,
reader=reader,
decoder=decoder,
num_samples=num_samples,
num_classes=num_classes,
items_to_descriptions=items_to_descriptions,
labels_to_names=labels_to_names)
if __name__ == "__main__":
# 打印日志
tf.logging.set_verbosity(tf.logging.DEBUG)
with tf.Graph().as_default():
# 最大世代
MAX_EPOCH = 50000
# 创建slim对象
slim = tf.contrib.slim
# 步数
global_step = slim.create_global_step()
#############################################################
# 读取MNIST数据集
#############################################################
# 读取数据集
dataset = get_record_dataset(FLAGS.dataset_dir,num_samples = 55000)
# 创建provider
provider = slim.dataset_data_provider.DatasetDataProvider(
dataset,
num_readers= FLAGS.num_readers,
common_queue_capacity=20*FLAGS.batch_size,
common_queue_min=10*FLAGS.batch_size,
shuffle=True)
# 在提供商处获取image
image, label = provider.get(['image', 'label'])
# 每次提取100个手写体
inputs, labels = tf.train.batch([image, label],
batch_size=FLAGS.batch_size,
allow_smaller_final_batch=True,
num_threads=FLAGS.num_readers,
capacity=FLAGS.batch_size*5)
#############################################################
#建立卷积神经网络,并将数据集的image通过神经网络,获得prediction。
#############################################################
inputs = tf.cast(inputs,tf.float32)
inputs_reshape = tf.reshape(inputs,[-1,28,28,1])
Conv_Net = Net.Conv_Net()
logits = Conv_Net.net(inputs_reshape)
#############################################################
# 利用prediction和实际label获得loss。
#############################################################
# 获得损失值
loss = Conv_Net.get_loss(labels = labels,logits = logits)
decay_steps = int(dataset.num_samples / FLAGS.batch_size *
FLAGS.num_epochs_per_decay)
# 学习率指数下降
learning_rate = tf.train.exponential_decay(FLAGS.learning_rate,
global_step,
decay_steps,
FLAGS.learning_rate_decay_factor,
staircase=False,
name='exponential_decay_learning_rate')
#############################################################
# 利用优化器完成梯度下降并保存模型。
#############################################################
# 优化器
optimizer = tf.train.AdamOptimizer(learning_rate)
# 构建训练对象
train_op = slim.learning.create_train_op(loss, optimizer,
summarize_gradients=False)
# gpu使用比率
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=FLAGS.gpu_memory_fraction,
allow_growth = True)
# 参数配置
config = tf.ConfigProto(allow_soft_placement=True,
log_device_placement=False,
gpu_options=gpu_options)
# 保存方式
saver = tf.train.Saver(max_to_keep=5,
keep_checkpoint_every_n_hours=1.0,
write_version=2,
pad_step_number=False)
# 托管训练
slim.learning.train(
train_op,
logdir=FLAGS.train_dir,
master='',
is_chief=True,
number_of_steps = FLAGS.max_number_of_steps,
log_every_n_steps = FLAGS.log_every_n_steps,
save_summaries_secs= FLAGS.save_summaries_secs,
saver=saver,
save_interval_secs = FLAGS.save_interval_secs,
session_config=config,
sync_optimizer=None)
4、训练结果
在完成数据集的构建后,直接运行CNN.py就可以开始训练。训练的graph如下:
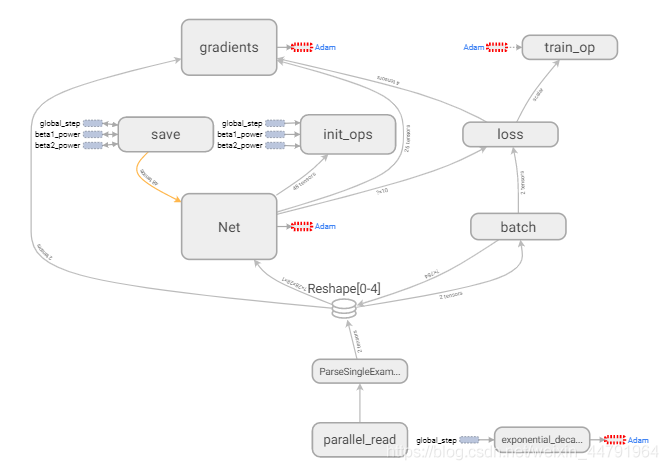
Net的内容为(这里的layer3忘了改成layer2了,试了很多结构,这个比较好):

输出的logs为:
…… INFO:tensorflow:global step 17899: loss = 1.4701 (0.040 sec/step) INFO:tensorflow:global step 17999: loss = 1.4612 (0.040 sec/step) INFO:tensorflow:global step 18099: loss = 1.4612 (0.051 sec/step) INFO:tensorflow:global step 18199: loss = 1.4612 (0.040 sec/step) INFO:tensorflow:global step 18299: loss = 1.4668 (0.048 sec/step) INFO:tensorflow:global step 18399: loss = 1.4615 (0.039 sec/step) INFO:tensorflow:global step 18499: loss = 1.4612 (0.050 sec/step) INFO:tensorflow:global step 18599: loss = 1.4812 (0.050 sec/step) INFO:tensorflow:global step 18699: loss = 1.4612 (0.060 sec/step) INFO:tensorflow:global step 18799: loss = 1.4712 (0.050 sec/step) INFO:tensorflow:global step 18899: loss = 1.4712 (0.040 sec/step) INFO:tensorflow:global step 18999: loss = 1.4716 (0.040 sec/step) INFO:tensorflow:global step 19199: loss = 1.4613 (0.040 sec/step) INFO:tensorflow:global step 19299: loss = 1.4619 (0.040 sec/step) INFO:tensorflow:global step 19399: loss = 1.4732 (0.040 sec/step) INFO:tensorflow:global step 19499: loss = 1.4612 (0.050 sec/step) INFO:tensorflow:global step 19599: loss = 1.4614 (0.040 sec/step) INFO:tensorflow:global step 19699: loss = 1.4612 (0.040 sec/step) INFO:tensorflow:global step 19799: loss = 1.4612 (0.040 sec/step) INFO:tensorflow:global step 19899: loss = 1.4612 (0.040 sec/step) INFO:tensorflow:global step 19999: loss = 1.4612 (0.040 sec/step) INFO:tensorflow:Stopping Training. INFO:tensorflow:Finished training! Saving model to disk.
以上就是python神经网络使用slim函数训练保存模型的详细内容,更多关于slim函数训练保存模型的资料请关注我们其它相关文章!
相关推荐
-
python神经网络Keras构建CNN网络训练
目录 Keras中构建CNN的重要函数 1.Conv2D 2.MaxPooling2D 3.Flatten 全部代码 利用Keras构建完普通BP神经网络后,还要会构建CNN Keras中构建CNN的重要函数 1.Conv2D Conv2D用于在CNN中构建卷积层,在使用它之前需要在库函数处import它. from keras.layers import Conv2D 在实际使用时,需要用到几个参数. Conv2D( nb_filter = 32, nb_row = 5, nb_col = 5
-
python神经网络使用Keras构建RNN训练
目录 Keras中构建RNN的重要函数 1.SimpleRNN 2.model.train_on_batch Keras中构建RNN的重要函数 1.SimpleRNN SimpleRNN用于在Keras中构建普通的简单RNN层,在使用前需要import. from keras.layers import SimpleRNN 在实际使用时,需要用到几个参数. model.add( SimpleRNN( batch_input_shape = (BATCH_SIZE,TIME_STEPS,INPUT
-
Python实现Keras搭建神经网络训练分类模型教程
我就废话不多说了,大家还是直接看代码吧~ 注释讲解版: # Classifier example import numpy as np # for reproducibility np.random.seed(1337) # from keras.datasets import mnist from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense, Act
-

python实现BP神经网络回归预测模型
神经网络模型一般用来做分类,回归预测模型不常见,本文基于一个用来分类的BP神经网络,对它进行修改,实现了一个回归模型,用来做室内定位.模型主要变化是去掉了第三层的非线性转换,或者说把非线性激活函数Sigmoid换成f(x)=x函数.这样做的主要原因是Sigmoid函数的输出范围太小,在0-1之间,而回归模型的输出范围较大.模型修改如下: 代码如下: #coding: utf8 '''' author: Huangyuliang ''' import json import random impo
-
python神经网络使用Keras进行模型的保存与读取
目录 学习前言 Keras中保存与读取的重要函数 1.model.save 2.load_model 全部代码 学习前言 开始做项目的话,有些时候会用到别人训练好的模型,这个时候要学会load噢. Keras中保存与读取的重要函数 1.model.save model.save用于保存模型,在保存模型前,首先要利用pip install安装h5py的模块,这个模块在Keras的模型保存与读取中常常被使用,用于定义保存格式. pip install h5py 完成安装后,可以通过如下函数保存模型.
-
python神经网络slim常用函数训练保存模型
目录 学习前言 slim是什么 slim常用函数 1.slim = tf.contrib.slim 2.slim.create_global_step 3.slim.dataset.Dataset 4.slim.dataset_data_provider.DatasetDataProvider 5.slim.conv2d 6.slim.max_pool2d 7.slim.fully_connected 8.slim.learning.train 本次博文实现的目标 整体框架构建思路 1.整体框架
-
python神经网络Keras常用学习率衰减汇总
目录 前言 为什么要调控学习率 下降方式汇总 2.指数型下降 3.余弦退火衰减 4.余弦退火衰减更新版 前言 增加了论文中的余弦退火下降方式.如图所示: 学习率是深度学习中非常重要的一环,好好学习吧! 为什么要调控学习率 在深度学习中,学习率的调整非常重要. 学习率大有如下优点: 1.加快学习速率. 2.帮助跳出局部最优值. 但存在如下缺点: 1.导致模型训练不收敛. 2.单单使用大学习率容易导致模型不精确. 学习率小有如下优点: 1.帮助模型收敛,有助于模型细化. 2.提高模型精度. 但存在如
-
Python之Numpy 常用函数总结
目录 通用函数 常见的简单数组函数 一元函数 二元函数 通用函数 常见的简单数组函数 先看看代码操作: mport numpy as np # # 产生一个数组 arr=np.arange(15) arr >>array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]) # 对里面的元素进行开根号处理 np.sqrt(arr) >>array([0. , 1. , 1.41421356, 1.73205081, 2. , 2.
-
Python的flask常用函数route()
目录 一.route()路由概述 二.静态路由和动态路径 方式1:静态路由 方式2:动态路由 三.route()其它参数 1.methods=[‘GET’,‘POST’] 一.route()路由概述 功能:将URL绑定到函数 路由函数route()的调用有两种方式:静态路由和动态路由 二.静态路由和动态路径 方式1:静态路由 @app.route(“/xxx”) xxx为静态路径 如::/index / /base等,可以返回一个值.字符串.页面等 from flask import Flask
-
Python OS模块常用函数说明
Python的标准库中的os模块包含普遍的操作系统功能.如果你希望你的程序能够与平台无关的话,这个模块是尤为重要的.即它允许一个程序在编写后不需要任何改动,也不会发生任何问题,就可以在Linux和Windows下运行. 下面列出了一些在os模块中比较有用的部分.它们中的大多数都简单明了. os.sep可以取代操作系统特定的路径分隔符.windows下为 "\\" os.name字符串指示你正在使用的平台.比如对于Windows,它是'nt',而对于Linux/Unix用户,它是'pos
-
python神经网络tensorflow利用训练好的模型进行预测
目录 学习前言 载入模型思路 实现代码 学习前言 在神经网络学习中slim常用函数与如何训练.保存模型文章里已经讲述了如何使用slim训练出来一个模型,这篇文章将会讲述如何预测. 载入模型思路 载入模型的过程主要分为以下四步: 1.建立会话Session: 2.将img_input的placeholder传入网络,建立网络结构: 3.初始化所有变量: 4.利用saver对象restore载入所有参数. 这里要注意的重点是,在利用saver对象restore载入所有参数之前,必须要建立网络结构,因
-
一文秒懂python正则表达式常用函数
导读: 正则表达式是处理字符串类型的"核武器",不仅速度快,而且功能强大.本文不过多展开正则表达式相关语法,仅简要 介绍 python中正则表达式常用函数及其使用方 法,以作快速查询浏览. 01 Re概览 Re模块是python的内置模块,提供了正则表达式在python中的所有用法,默认安装位置在python根目录下的Lib文件夹(如 ..\Python\Python37\Lib).主要提供了3大类字符串操作方法: 字符查找/匹配 字符替换 字符分割 由于是面向字符串类型的模块,就不得
-
python神经网络AlexNet分类模型训练猫狗数据集
目录 什么是AlexNet模型 训练前准备 1.数据集处理 2.创建Keras的AlexNet模型 开始训练 1.训练的主函数 2.Keras数据生成器 3.主训练函数全部代码 训练结果 最近在做实验室的工作,要用到分类模型,老板一星期催20次,我也是无语了,上有对策下有政策,在下先找个猫猫狗狗的数据集练练手,快乐极了 什么是AlexNet模型 AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的.也是在那年之后,更多的更深的神经网络