Python用20行代码实现批量抠图功能
目录
- 前言
- 1.准备
- 2.编写代码
- 3.结果分析
前言


抠图前 vs Python自动抠图后
在日常的工作和生活中,我们经常会遇到需要抠图的场景,即便是只有一张图片需要抠,也会抠得我们不耐烦,倘若遇到许多张图片需要抠,这时候你的表情应该会很有趣。
Python能够成为这样的一种工具:在只有一张图片,需要细致地抠出人物的情况下,能帮你减少抠图步骤;在有多张图片需要抠的情况下,能直接帮你输出这些人物的基本轮廓,虽然不够细致,但也够用了。
DeepLabv3+ 是谷歌 DeepLab语义分割系列网络的最新作 ,这个模型可以用于人像分割,支持任意大小的图片输入。如果我们自己来实现这个模型,那可能会非常麻烦,但是幸运的是,百度的paddle hub已经帮我们实现了,我们仅需要加载模型对图像进行分割即可。
1.准备
为了实现这个实验,Python是必不可少的,如果你还没有安装Python,建议阅读我们的这篇文章哦:超详细Python安装指南。
然后,我们需要安装百度的paddlepaddle, 进入他们的官方网站就有详细的指引
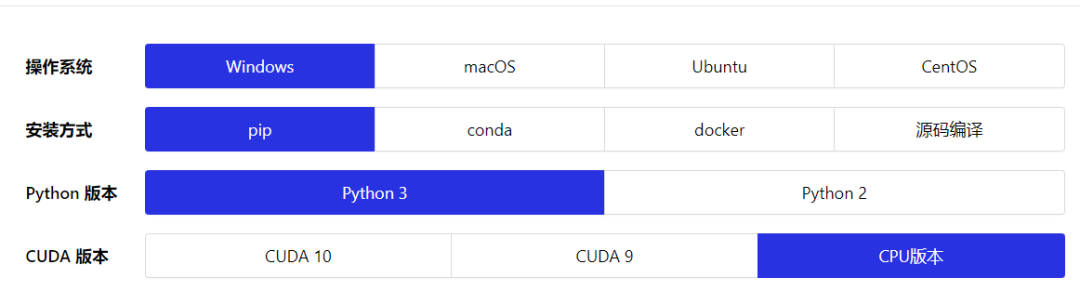
根据你自己的情况选择这些选项,最后一个CUDA版本,由于本实验不需要训练数据,也不需要太大的计算量,所以直接选择CPU版本即可。选择完毕,下方会出现安装指引,不得不说,Paddlepaddle这些方面做的还是比较贴心的(就是名字起的不好)。
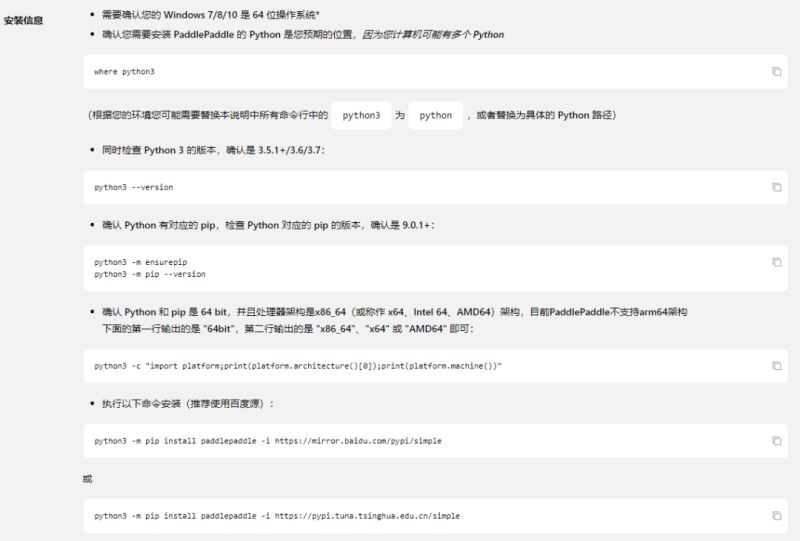
要注意,如果你的Python3环境变量里的程序名称是Python,记得将python3 xxx 语句改为Python xxx 如下进行安装:
python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
2.编写代码
整个步骤分为三步:
1.加载模型
2.指定待抠图的图片目录
3.抠图
import os
import sys
import paddlehub as hub
# 1.加载模型
humanseg = hub.Module(name="deeplabv3p_xception65_humanseg")
# 2.指定待抠图图片目录
path = './source/'
files = []
dirs = os.listdir(path)
for diretion in dirs:
files.append(path + diretion)
# 3.抠图
results = humanseg.segmentation(data={"image": files})
for result in results:
print(result['origin'])
print(result['processed'])
不多不少一共20行代码。抠图完毕后会在本地文件夹下产生一个叫做humanseg_output的文件夹。这里面存放的是已经抠图成功的图片。




素材获取地址
3.结果分析
不得不承认,谷歌的算法就素厉害啊。只要背景好一点,抠出来的细节都和手动抠的细节不相上下,甚至优于人工手段。
不过在背景和人的颜色不相上下的情况下,会产生一些问题,比如下面这个结果:


背后那个大叔完全被忽略掉了(求大叔的内心阴影面积)。尽管如此,这个模型是我迄今为止见过的最强抠图模型,没有之一。
到此这篇关于Python用20行代码实现批量抠图功能的文章就介绍到这了,更多相关Python批量抠图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python图片批量自动抠图去背景的代码详解
今天发现个好东西啊,叫片刻抠图,是一个在线对图片自动抠图去除背景的网站.只要上传图片,就可以自动把背景去掉把目标对象抠出来. 不管是动物.汽车或各种产品,还是人物,都可以全自动做到令人惊艳的抠图效果!而且还说可以做到发丝级 AI 自动抠图,作为一个头发存留不多的程序员,突然莫名感觉到一丝来自这个世界的恶意. 这个抠图有什么用?比如可以把人物抠出来换个背景: 也可以把产品抠出来做成新的商品宣传图:(做电商的朋友肯定懂) 这么好用的东西,现在最关键的是:完全免费! emmmmmm,这个消息被我的几十
-
Python用5行代码实现批量抠图的示例代码
前言 对于会PhotoShop的人来说,抠图是非常简单的操作了,有时候几秒钟就能扣好一张图.不过一些比较复杂的图,有时候还是要画点时间的,今天就给大家带了一个非常快速简单的办法,用Python来批量抠取人像. 效果展示 开始吧,我也不看好什么自动抠图,总觉得不够精确,抠不出满意的图.下面我就直接展示一下效果图吧.我们先看看原图 这张图片背景未纯色,我们平时用PhotoShop抠起来也比较简单,对我们计算机来说也不是什么难题,下面是效果图: 因为本身是PNG图片,而且原图是白色背景,所以看不出什么
-
Python快速实现一键抠图功能的全过程
简介 使用百度深度学习框架paddlepaddle对人像图片进行自动化抠图 安装 根据PaddlePaddle官网命令安装 如 pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple pip install paddlehub -i https://mirror.baidu.com/pypi/simple 初试 1.jpg 2.jpg 3.jpg 4.jpg 5.jpg import paddlehub as hu
-
基于Python实现自动抠图小程序
目录 导语 正文 1.前期准备 1.1 首先 1.2 网站小介绍 2.正式抠图 2.1 环境安装 2.2 素材(可自选) 2.3 主程序代码 3.效果图 3.1 界面展示 3.2 图片展示 总结 导语 大家好!我是木木子,今天天气不是很好,下雨了,让我没点儿写文章的动力啊~ 写程序:一天到晚没事做,一行代码改一天,从白天学完天黑! 在日常的工作和生活中,我们经常会遇到需要抠图的场景,即便是只有一张图片需要抠,也会抠得我们不耐烦,倘若遇到许多张图片需要抠,那就…… 今天教你用Python制作一款
-
如何使用五行Python代码轻松实现批量抠图
目录 前言 准备工作 代码实现 补充:可能遇到的坑 总结 前言 你是否曾经想将某张照片中的人物抠出来,然后拼接到其他图片上去,从而可以即使你在天涯海角,我也可以到此一游? 专业点的人使用 PhotoShop 的“魔棒”工具可以抠图,非专业人士可以使用各种美图 APP 来实现,但是他们毕竟处理能力有限,一次只能处理一张图片,而且比较复杂的图像可能耗时较久. 今天我来向大家展示第三种途径——用 Python 一键批量抠图. 准备工作 既然要装逼,准备工作是少不了的.所谓“站在巨人的肩膀上,做事事半功
-
Python用20行代码实现批量抠图功能
目录 前言 1.准备 2.编写代码 3.结果分析 前言 抠图前 vs Python自动抠图后 在日常的工作和生活中,我们经常会遇到需要抠图的场景,即便是只有一张图片需要抠,也会抠得我们不耐烦,倘若遇到许多张图片需要抠,这时候你的表情应该会很有趣. Python能够成为这样的一种工具:在只有一张图片,需要细致地抠出人物的情况下,能帮你减少抠图步骤:在有多张图片需要抠的情况下,能直接帮你输出这些人物的基本轮廓,虽然不够细致,但也够用了. DeepLabv3+ 是谷歌 DeepLab语义分割系列网络的
-
Python用20行代码实现完整邮件功能
目录 Python实现完整邮件 一.邮箱端设置 1.首先登录网页版126邮箱 2.打开 设置-POP3/SMTP/IMAP配置界面 3.新增一个授权码 二.python发送邮件 1.安装邮件模块 2.调用模块 3.设置邮件内容 4.添加附件 三.python读取邮件 Python实现完整邮件 先上效果: 一.邮箱端设置 首先,要对邮件进行一下设置,在邮箱端获取一个授权码. 1.首先登录网页版126邮箱 2.打开 设置-POP3/SMTP/IMAP配置界面 3.新增一个授权码 二.python发送
-
Python使用20行代码实现微信聊天机器人
近来,打开微信群发消息,就会秒收到一些活跃分子的回复,有的时候感觉对方回答很在理,但是有的时候发现对方的回答其实是驴唇不对马嘴,仔细深究发现,原来对方是机器人.今天,小编就带大家用20行代码,带你一起打造一个微信聊天机器人,让你的微信群一直嗨不停~~ 首先我们需要安装一个微信相关的第三方库,itchat,在Windows上通过命令:pip install itchat,就可以将其安装. 其二,我们需要去图灵机器人官网:http://www.tuling123.com,注册一下,即可获得一个机器人
-
Python使用5行代码批量做小姐姐的素描图
目录 1. 流程分析 2. 具体实现 3. 百度图片爬虫+生成素描图 我给大家带来的是 50行代码,生成一张素描图.让自己也是一个素描"大师".那废话不多说,我们直接先来看看效果吧. 上图的右边就是我们的效果,那具体有哪些步骤呢? 1. 流程分析 对于上面的流程来说是非常简单的,接下来我们来看看具体的实现. 2. 具体实现 安装所需要的库: pip install opencv-python 导入所需要的库: import cv2 编写主体代码也是非常的简单的,代码如下: import
-
不到20行代码用Python做一个智能聊天机器人
伴随着自然语言技术和机器学习技术的发展,越来越多的有意思的自然语言小项目呈现在大家的眼前,聊天机器人就是其中最典型的应用,今天小编就带领大家用不到20行代码,运用两种方式搭建属于自己的聊天机器人. 1.神器wxpy库 首先,小编先向大家介绍一下本次运用到的python库,本次项目主要运用到的库有wxpy和chatterbot. wxpy是在 itchat库 的基础上,通过大量接口优化,让模块变得简单易用,并进行了功能上的扩展.什么是接口优化呢,简单来说就是用户直接调用函数,并输入几个参数,就可以
-
python随机生成大小写字母数字混合密码(仅20行代码)
用简单的方法生成随机性较大的密码 仅用20行代码随机生成密码 核心思路:利用random模块 random模块随机生成数字,大小写字母,循环次数 while循环+随机生成的循环次数-->随机plus++ 大写字母ASKII码在65-90之间 小写字母Askll码在97-122之间 最终效果: x个大写字母+y个数字+z个小写字母(x,y,z均随机) 随机性相较于以往单调的 小写+数字+大写+小写+数字+大写- 循环有所提升 import random print("随机数生成") time
-
20行代码教你用python给证件照换底色的方法示例
1.图片来源 该图片来源于百度图片,如果侵权,请联系我删除!图片仅用于知识交流. 2.读取图片并显示 imread():读取图片: imshow():展示图片: waitkey():设置窗口等待,如果不设置,窗口会一闪而过: import cv2 import numpy as np # 读取照片 img=cv2.imread('girl.jpg') # 显示图像 cv2.imshow('img',img) # 窗口等待的命令,0表示无限等待 cv2.waitKey(0) 效果如下: 3.图片缩
-
Java用20行代码实现抖音小视频批量转换为gif动态图
本文主要介绍了Java用20行代码实现抖音小视频批量转换为gif动态图,分享给大家,具体如下: 效果图 本功能实现需要用到第三方jar包 jave,JAVE 是java调用FFmpeg的封装工具. spring boot项目pom文件中添加以下依赖 <!-- https://mvnrepository.com/artifact/ws.schild/jave-core --> <dependency> <groupId>ws.schild</groupId>
-
女神相册密码忘记了 我只用Python写了20行代码
视频地址 我用20行代码,帮女神破解相册密码 一.事情是这样的 今早上班,公司女神小姐姐说,她去年去三亚旅游的照片打不开了 好奇问了一下才知道. 原来是,她把照片压缩了,而且还加了密码. 但是密码不记得了,只记得是一串6位数字. 话说照片压缩率也不高,而且还加密,难道是有什么可爱的小照片 但是作为一个正(ba)直(gua)的技术人员 我跟她说:"这事交给我,python写个脚本,帮你破解掉~~" 二.首先回顾一下女神的操作流程 对相册进行压缩的时候,添加了密码. LIke This ↓