Pandas处理时间序列数据操作详解
目录
- 前言
- 一、获取时间
- 二、时间索引
- 三、时间推移
前言
一般从数据库或者是从日志文件读出的数据均带有时间序列,做时序数据处理或者实时分析都需要对其时间序列进行归类归档。而Pandas是处理这些数据很好用的工具包。此篇博客基于Jupyter之上进行演示,本篇博客的愿景是希望我或者读者通过阅读这篇博客能够学会方法并能实际运用。希望读者看完能够提出问题或者看法,博主会长期维护博客做及时更新。纯分享,希望大家喜欢。
一、获取时间
python自带datetime库,通过调用此库可以获取本地时间
from datetime import datetime datetime.now()
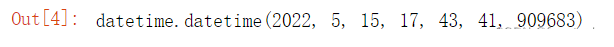
同时也可以独立获取年月日:
datetime.now().day datetime.now().year datetime.now().moth
isoweekday()获取符合ISO标准的指定日期所在的星期数:
datetime.now().isoweekday()
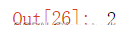
为星期二。
但也有weekeday()方法但是是从0开始,也就是说0也就是周一,需要加一转为周数:
datetime.now().weekday()+1

datetime可以将日期(date)和时间(time)分隔开:
datetime.now().date()

datetime.now().time()
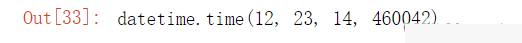
也可以用timetuple()函数将整个时间拆分为结构体:
datetime.now().timetuple()
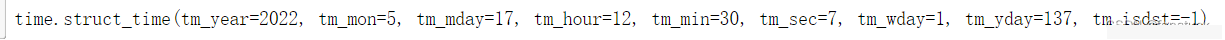
要转换为自定义熟悉的时间表达可以使用strftime()函数,其输出代码格式有以下几种:
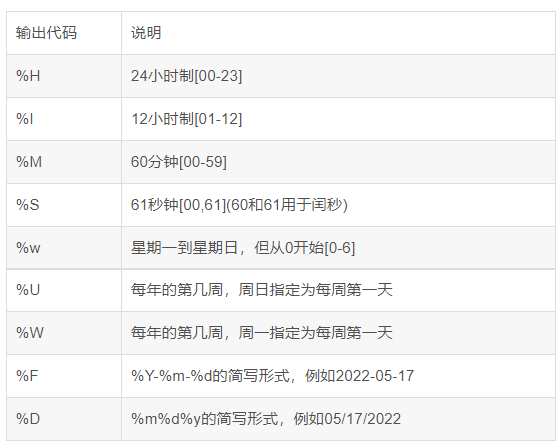
datetime.now().strftime('%Y-%m-%d')
datetime.now().strftime('%m/%d/%Y %H:%M:%S')

二、时间索引
时间索引是根据数据的时间来处理时序数据进行归档筛选的一种索引方式。
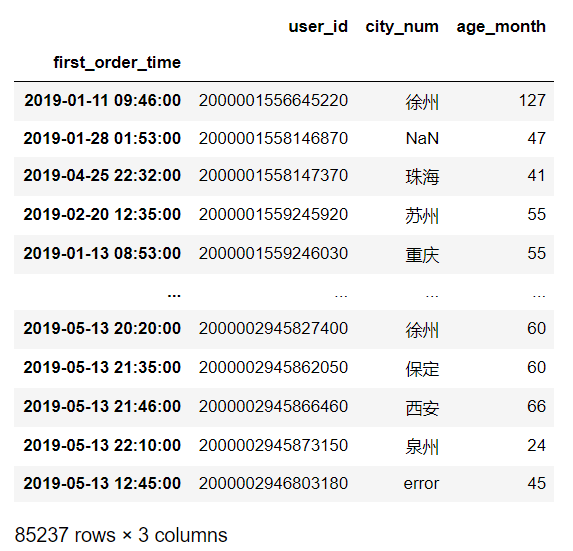
展示数据:

首先查看类型是否为 datetime类型,是该类型再重新设定索引,否则需要先把索引时间列转换为datetime类型再进行设定。
df1.set_index('first_order_time')
若要查找2019年的数据,只需要在 后面加上日期即可:
df1['2019']
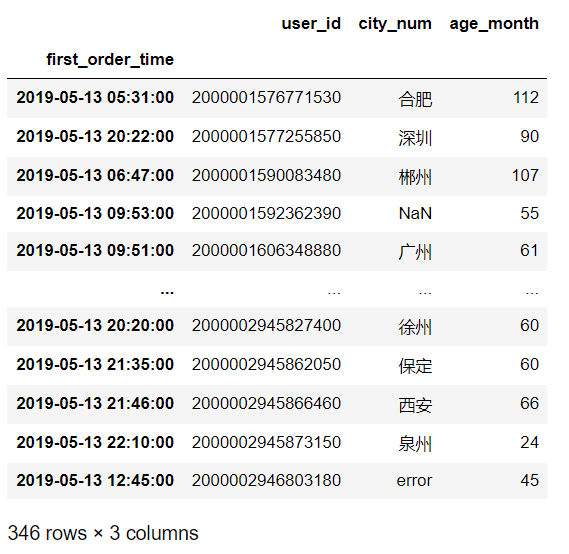
想要获取详细的日期的数据只需要在[]里面输入对应的日期即可:
df1['2019-05-13']
获取区间日期数据:
df1['2019-05-01':'2019-05-13']

三、时间推移
如果时序数据提取出来时间并不符合对应时间戳,则可以使用timedelta进行推移时间:
timedelta类表示为时间差,可直接实例化也可以由两个datetime进行相减操作得到。

可表示的时间差依次为:
days,seconds,microseconds,minutes,hours,weeks
如我们要推移一天时间:
date = datetime(2019,5,10) date+timedelta(days = 1)

往后推移只需要减去对应天数就好了。
比起timedelta,有date offset可以直接进行时间推移,并不需要换算,效率比timedelta要快很多。
引入库:
from pandas.tseries.offsets import Day,Hour,Minute date+Day(1)
计算结果为timestamp:
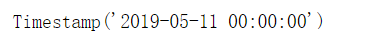
到此这篇关于Pandas处理时间序列数据操作详解的文章就介绍到这了,更多相关Pandas时间序列内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python+pandas+时间、日期以及时间序列处理方法
先简单的了解下日期和时间数据类型及工具 python标准库包含于日期(date)和时间(time)数据的数据类型,datetime.time以及calendar模块会被经常用到. datetime以毫秒形式存储日期和时间,datetime.timedelta表示两个datetime对象之间的时间差. 给datetime对象加上或减去一个或多个timedelta,会产生一个新的对象 from datetime import datetime from datetime import timedel
-
python Pandas库基础分析之时间序列的处理详解
前言 在使用Python进行数据分析时,经常会遇到时间日期格式处理和转换,特别是分析和挖掘与时间相关的数据,比如量化交易就是从历史数据中寻找股价的变化规律.Python中自带的处理时间的模块有datetime,NumPy库也提供了相应的方法,Pandas作为Python环境下的数据分析库,更是提供了强大的日期数据处理的功能,是处理时间序列的利器. 1.生成日期序列 主要提供pd.data_range()和pd.period_range()两个方法,给定参数有起始时间.结束时间.生成时期的数目及时
-
python pandas 对时间序列文件处理的实例
如下所示: import pandas as pd from numpy import * import matplotlib.pylab as plt import copy def read(filename): dat=pd.read_csv(filename,iterator=True) loop = True chunkSize = 1000000 R=[] while loop: try: data = dat.get_chunk(chunkSize) data=data.loc[:
-
python时间日期函数与利用pandas进行时间序列处理详解
python标准库包含于日期(date)和时间(time)数据的数据类型,datetime.time以及calendar模块会被经常用到. datetime以毫秒形式存储日期和时间,datetime.timedelta表示两个datetime对象之间的时间差. 下面我们先简单的了解下python日期和时间数据类型及工具 给datetime对象加上或减去一个或多个timedelta,会产生一个新的对象 from datetime import datetime from datetime impo
-
Pandas中时间序列的处理大全
一.时间序列数据的生成 pd.date_ranges生成时间序列 time格式:年月日分隔符号可以是"-","/",空格这三种格式(年月日.日月年.月日年都可以):时分秒只能用":"分隔,顺序只能是时分秒. start:起始时间(time) end:终止时间(time) periods:期数(int),使用时只能出现start或者end,两者不能同时出现 freq:频率(numY,num年:numM,num月:numD,num日),详细参数见下表
-

Pandas处理时间序列数据操作详解
目录 前言 一.获取时间 二.时间索引 三.时间推移 前言 一般从数据库或者是从日志文件读出的数据均带有时间序列,做时序数据处理或者实时分析都需要对其时间序列进行归类归档.而Pandas是处理这些数据很好用的工具包.此篇博客基于Jupyter之上进行演示,本篇博客的愿景是希望我或者读者通过阅读这篇博客能够学会方法并能实际运用.希望读者看完能够提出问题或者看法,博主会长期维护博客做及时更新.纯分享,希望大家喜欢. 一.获取时间 python自带datetime库,通过调用此库可以获取本地时间 fr
-
Python Pandas学习之基本数据操作详解
目录 1索引操作 1.1直接使用行列索引(先列后行) 1.2结合loc或者iloc使用索引 1.3使用ix组合索引 2赋值操作 3排序 3.1DataFrame排序 3.2Series排序 为了更好的理解这些基本操作,下面会通过读取一个股票数据,来进行Pandas基本数据操作的语法介绍. # 读取文件(读取保存文件后面会专门进行讲解,这里先直接调用下api) data = pd.read_csv("./data/stock_day.csv") # 读取当前目录下一个csv文件 # 删
-
Python必备技巧之字符数据操作详解
目录 字符串操作 字符串 + 运算符 字符串 * 运算符 字符串 in 运算符 内置字符串函数 字符串索引 字符串切片 字符串切片中的步幅 将变量插入字符串 修改字符串 内置字符串方法 bytes对象 定义文字bytes对象 bytes使用内置bytes()函数定义对象 bytes对象操作,操作参考字符串. bytearray对象,Python 支持的另一种二进制序列类型 字符串操作 字符串 + 运算符 +运算符用于连接字符串,返回一个由连接在一起的操作数组成的字符串. >>> s =
-
vue.js前后端数据交互之提交数据操作详解
本文实例讲述了vue.js前后端数据交互之提交数据操作.分享给大家供大家参考,具体如下: 前端小白刚开始做页面的时候,我们的前端页面中经常会用到表单,所以学会提交表单也是一个基本技能,其实用ajax就能实现,但他的原始语法有点...额 ...复杂,所以这里给大家提供一种用vue-resource向后端提交数据. (1)第一步,先在template中写一个表单: <el-form :model="ruleForm" :rules="rules" ref=&quo
-
Thinkphp5.0 框架使用模型Model添加、更新、删除数据操作详解
本文实例讲述了Thinkphp5.0 框架使用模型Model添加.更新.删除数据操作.分享给大家供大家参考,具体如下: Thinkphp5.0 的使用模型Model添加数据 使用create()方法添加数据 $res = TestUser::create([ 'name' => 'zhao liu', 'password' => md5(123456), 'email' => 'zhaoliu@qq.com' ]); dump($res); 使用save()方法添加数据 $userMod
-
Laravel框架Eloquent ORM简介、模型建立及查询数据操作详解
本文实例讲述了Laravel框架Eloquent ORM简介.模型建立及查询数据操作.分享给大家供大家参考,具体如下: 注:以下知识点可能有不全面之处,望见谅 NO.1Eloquent ORM简介 Laravel所自带的Eloquent ORM是一个优美.简洁的ActiveRecord实现,用来实现数据库操作 每个数据表都有与之相对应的"模型(Model)"用于和数据交互 NO.2模型的建立 最基础的模型代码如下: namespace App; use Illuminate\Datab
-
sqlserver数据库导入数据操作详解(图)
Microsoft SQL Server Management Studio是SQL SERVER的客户端工具,相信大家都知道.我不知道大伙使用导入数据的情况怎么样,反正我最近是遇到过.主要是因为没有远程数据库服务器的权限,而需要测试新修改的内容对旧数据的冲突.因为流程改变,免不了需要修改数据来适应新的变化.所以需要在测试环境里面去模拟真实环境的数据.当时还搞笑,直接是粘贴到EXCEL,然后再复制到数据库.对于一般来说,这种方式也可以,但是对于一些特殊的字符,如果直接粘贴到EXCEL里面的话,并
-
Pandas对CSV文件读写操作详解
目录 什么是 CSV 文件 CSV 库解析 CSV 文件 读取 CSV 文件 CSV reader 参数 CSV 文件的写入 使用 pandas 库解析 CSV 文件 pandas 读取 CSV 文件 pandas 写入 CSV 文件 什么是 CSV 文件 CSV 文件(逗号分隔值文件)是一种纯文本文件,它使用特定的结构来排列表格数据.因为它是一个纯文本文件,所以只能包含实际的文本数据,换句话说就是可打印的 ASCII 或 Unicode 字符. 通常,CSV 文件的结构由其名称给出,使用逗号分
-
Python Pandas数据处理高频操作详解
目录 引入依赖 算法相关依赖 获取数据 生成df 重命名列 增加列 缺失值处理 独热编码 替换值 删除列 数据筛选 差值计算 数据修改 时间格式转换 设置索引列 折线图 散点图 柱状图 热力图 66个最常用的pandas数据分析函数 从各种不同的来源和格式导入数据 导出数据 创建测试对象 查看.检查数据 数据选取 数据清理 筛选,排序和分组依据 数据合并 数据统计 16个函数,用于数据清洗 1.cat函数 2.contains 3.startswith/endswith 4.count 5.ge
-
基于Python对数据shape的常见操作详解
这一阵在用python做DRL建模的时候,尤其是在配合使用tensorflow的时候,加上tensorflow是先搭框架再跑数据,所以调试起来很不方便,经常遇到输入数据或者中间数据shape的类型不统一,导致一些op老是报错.而且由于水平菜,所以一些常用的数据shape转换操作也经常百度了还是忘,所以想再整理一下. 一.数据的基本属性 求一组数据的长度 a = [1,2,3,4,5,6,7,8,9,10,11,12] print(len(a)) print(np.size(a)) 求一组数据的s