python爬虫之爬取谷歌趋势数据
一、前言
爬取谷歌趋势数据需要科学上网~
二、思路
谷歌数据的爬取很简单,就是代码有点长。主要分下面几个就行了
爬取的三个界面返回的都是json数据。主要获取对应的token值和req,然后构造url请求数据就行


token值和req值都在这个链接的返回数据里。解析后得到token和req就行
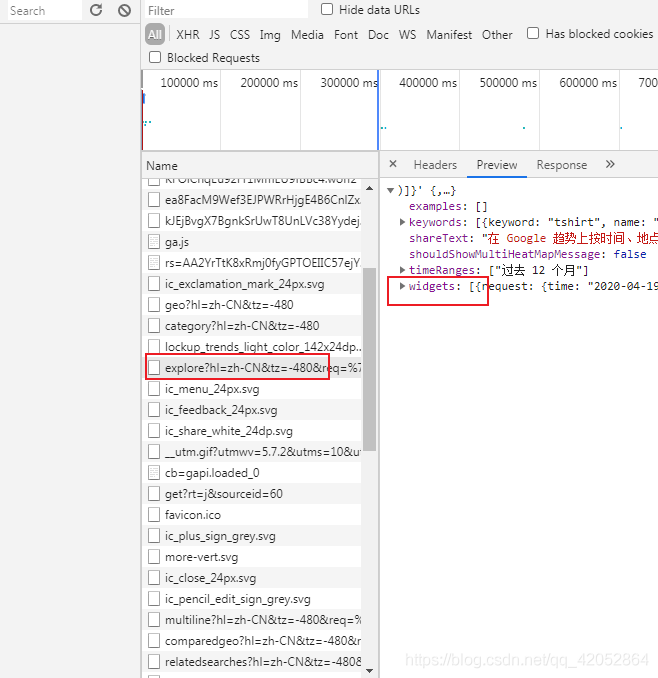
socks5代理不太懂,抄网上的作业,假如了当前程序的全局代理后就可以跑了。全部代码如下
import socket
import socks
import requests
import json
import pandas as pd
import logging
#加入socks5代理后,可以获得当前程序的全局代理
socks.set_default_proxy(socks.SOCKS5,"127.0.0.1",1080)
socket.socket = socks.socksocket
#加入以下代码,否则会出现InsecureRequestWarning警告,虽然不影响使用,但看着糟心
# 捕捉警告
logging.captureWarnings(True)
# 或者加入以下代码,忽略requests证书警告
# from requests.packages.urllib3.exceptions import InsecureRequestWarning
# requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
# 将三个页面获得的数据存为DataFrame
time_trends = pd.DataFrame()
related_topic = pd.DataFrame()
related_search = pd.DataFrame()
#填入自己打开网页的请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'x-client-data': 'CJa2yQEIorbJAQjEtskBCKmdygEI+MfKAQjM3soBCLKaywEI45zLAQioncsBGOGaywE=Decoded:message ClientVariations {// Active client experiment variation IDs.repeated int32 variation_id = [3300118, 3300130, 3300164, 3313321, 3318776, 3321676, 3329330, 3329635, 3329704];// Active client experiment variation IDs that trigger server-side behavior.repeated int32 trigger_variation_id = [3329377];}',
'referer': 'https://trends.google.com/trends/explore',
'cookie': '__utmc=10102256; __utmz=10102256.1617948191.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=10102256.889828344.1617948191.1617948191.1617956555.3; __utmt=1; __utmb=10102256.5.9.1617956603932; SID=8AfEx31goq255ga6Ldt9ljEVZ5xQ7fYTAdzCK3DgEYp2s6MOxeKc__hQ90tTtn0W-6AVoQ.; __Secure-3PSID=8AfEx31goq255ga6Ldt9ljEVZ5xQ7fYTAdzCK3DgEYp2s6MOLU4HYHzyoAXIvtAhfF_WNg.; HSID=AELT1m_DoHJY-r6SW; SSID=AJSlRt0T7ngXXMtqv; APISID=3Nt6oALGV8kSym2M/A2QeNBMtb9P7VcIwV; SAPISID=iAA0fu76JZezPfK4/Apws7zK1y-o74b2YD; __Secure-3PAPISID=iAA0fu76JZezPfK4/Apws7zK1y-o74b2YD; 1P_JAR=2021-04-06-06; SEARCH_SAMESITE=CgQIo5IB; NID=213=oYQE35gIVD2DrxbpY7NdAQsAEyg-If7Jh_nBdSKTkvmtgaVV7tYeSQNq_636cysbsajJP3_dKfr95w51ywK-dxVYhzPP4Zll9JndBYY98vd_XegGoeLEevpxIhNxUAv6H24OVt_edoGFkSjTpWKn4QAoIoerHCViyvozrvGF7m4scupppmxN-h9dwm1nrs15I3b_E-ifLq0lgd9s7QrgA-FRuaDeyuXN8t1K7l_DMTB1jkE5ED_dC-_QAO7DDw; SIDCC=AJi4QfFdMiK_qV41ViVJf0wWmtOu8yUVSQc_UEvemoaQwTGI9W0w2XwwkMCufVcYIS5ogRSkq5w; __Secure-3PSIDCC=AJi4QfEmB-gnzZLHWR4p1EmOfS2dhSz9zWSGNGOozrY2udFk4KwVmVo_srZdZrmdy7h_mwLSwQ'
}
# 获取需要的三个界面的req值和token值
def get_token_req(keyword):
url = 'https://trends.google.com/trends/api/explore?hl=zh-CN&tz=-480&req={{"comparisonItem":[{{"keyword":"{}","geo":"US","time":"today 12-m"}}],"category":0,"property":""}}&tz=-480'.format(
keyword)
html = requests.get(url, headers=headers, verify=False).text
data = json.loads(html[5:])
req_1 = data['widgets'][0]['request']
token_1 = data['widgets'][0]['token']
req_2 = data['widgets'][2]['request']
token_2 = data['widgets'][2]['token']
req_3 = data['widgets'][3]['request']
token_3 = data['widgets'][3]['token']
result = {'req_1': req_1, 'token_1': token_1, 'req_2': req_2, 'token_2': token_2, 'req_3': req_3,
'token_3': token_3}
return result
# 请求三个界面的数据,返回的是json数据,所以数据不用解析,完美
def get_info(keyword):
content = []
keyword = keyword
result = get_token_req(keyword)
#第一个界面
req_1 = result['req_1']
token_1 = result['token_1']
url_1 = "https://trends.google.com/trends/api/widgetdata/multiline?hl=zh-CN&tz=-480&req={}&token={}&tz=-480".format(
req_1, token_1)
r_1 = requests.get(url_1, headers=headers, verify=False)
if r_1.status_code == 200:
try:
content_1 = r_1.content
content_1 = json.loads(content_1.decode('unicode_escape')[6:])['default']['timelineData']
result_1 = pd.json_normalize(content_1)
result_1['value'] = result_1['value'].map(lambda x: x[0])
result_1['keyword'] = keyword
except Exception as e:
print(e)
result_1 = None
else:
print(r_1.status_code)
#第二个界面
req_2 = result['req_2']
token_2 = result['token_2']
url_2 = 'https://trends.google.com/trends/api/widgetdata/relatedsearches?hl=zh-CN&tz=-480&req={}&token={}'.format(
req_2, token_2)
r_2 = requests.get(url_2, headers=headers, verify=False)
if r_2.status_code == 200:
try:
content_2 = r_2.content
content_2 = json.loads(content_2.decode('unicode_escape')[6:])['default']['rankedList'][1]['rankedKeyword']
result_2 = pd.json_normalize(content_2)
result_2['link'] = "https://trends.google.com" + result_2['link']
result_2['keyword'] = keyword
except Exception as e:
print(e)
result_2 = None
else:
print(r_2.status_code)
#第三个界面
req_3 = result['req_3']
token_3 = result['token_3']
url_3 = 'https://trends.google.com/trends/api/widgetdata/relatedsearches?hl=zh-CN&tz=-480&req={}&token={}'.format(
req_3, token_3)
r_3 = requests.get(url_3, headers=headers, verify=False)
if r_3.status_code == 200:
try:
content_3 = r_3.content
content_3 = json.loads(content_3.decode('unicode_escape')[6:])['default']['rankedList'][1]['rankedKeyword']
result_3 = pd.json_normalize(content_3)
result_3['link'] = "https://trends.google.com" + result_3['link']
result_3['keyword'] = keyword
except Exception as e:
print(e)
result_3 = None
else:
print(r_3.status_code)
content = [result_1, result_2, result_3]
return content
def main():
global time_trends,related_search,related_topic
with open(r'C:\Users\Desktop\words.txt','r',encoding = 'utf-8') as f:
words = f.readlines()
for keyword in words:
keyword = keyword.strip()
data_all = get_info(keyword)
time_trends = pd.concat([time_trends,data_all[0]],sort = False)
related_topic = pd.concat([related_topic,data_all[1]],sort = False)
related_search = pd.concat([related_search,data_all[2]],sort = False)
if __name__ == "__main__":
main()
到此这篇关于python爬虫之爬取谷歌趋势数据的文章就介绍到这了,更多相关python爬取谷歌趋势内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python爬虫利用selenium实现自动翻页爬取某鱼数据的思路详解
基本思路: 首先用开发者工具找到需要提取数据的标签列 利用xpath定位需要提取数据的列表 然后再逐个提取相应的数据: 保存数据到csv: 利用开发者工具找到下一页按钮所在标签: 利用xpath提取此标签对象并返回: 调用点击事件,并循环上述过程: 最终效果图: 代码: from selenium import webdriver import time import re class Douyu(object): def __init__(self): # 开始时的url self.start
-
python实现模拟器爬取抖音评论数据的示例代码
目标: 由于之前和朋友聊到抖音评论的爬虫,demo做出来之后一直没整理,最近时间充裕后,在这里做个笔记. 提示:大体思路 通过fiddle + app模拟器进行抖音抓包,使用python进行数据整理 安装需要的工具: python3 下载 fiddle 安装及配置 手机模拟器下载 抖音部分: 模拟器下载好之后, 打开模拟器 在应用市场下载抖音 对抖音进行fiddle配置,配置成功后就可以当手机一样使用了 一.工具配置及抓包: 我们随便打开一个视频之后,fiddle就会刷新新的数据包 在json中
-
Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境
-
python爬取股票最新数据并用excel绘制树状图的示例
大家好,最近大A的白马股们简直 跌妈不认,作为重仓了抱团白马股基金的养鸡少年,每日那是一个以泪洗面啊. 不过从金融界最近一个交易日的大盘云图来看,其实很多中小股还是红色滴,绿的都是白马股们. 以下截图来自金融界网站-大盘云图: 那么,今天我们试着用python爬取最近交易日的股票数据,并试着用excel简单绘制以下上面这个树状图.本文旨在抛砖引玉,吼吼. 1. python爬取网易财经不同板块股票数据 目标网址: http://quotes.money.163.com/old/#query=hy
-
Python爬虫之爬取2020女团选秀数据
一.先看结果 1.1创造营2020撑腰榜前三甲 创造营2020撑腰榜前三名分别是 希林娜依·高.陈卓璇 .郑乃馨 >>>df1[df1['排名']<=3 ][['排名','姓名','身高','体重','生日','出生地']] 排名 姓名 身高 体重 生日 出生地 0 1.0 希林娜依·高 NaN NaN 1998年07月31日 新疆 1 2.0 陈卓璇 168.0 42.0 1997年08月13日 贵州 2 3.0 郑乃馨 NaN NaN 1997年06月25日 泰国 1.2青春有
-
Python爬虫爬取全球疫情数据并存储到mysql数据库的步骤
思路:使用Python爬虫对腾讯疫情网站世界疫情数据进行爬取,封装成一个函数返回一个 字典数据格式的对象,写另一个方法调用该函数接收返回值,和数据库取得连接后把 数据存储到mysql数据库. 一.mysql数据库建表 CREATE TABLE world( id INT(11) NOT NULL AUTO_INCREMENT, dt DATETIME NOT NULL COMMENT '日期', c_name VARCHAR(35) DEFAULT NULL COMMENT '国家'
-
Python爬虫之爬取某文库文档数据
一.基本开发环境 Python 3.6 Pycharm 二.相关模块的使用 import os import requests import time import re import json from docx import Document from docx.shared import Cm 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.目标网页分析 网站的文档内容,都是以图片形式存在的.它有自己的数据接口 接口链接: https://openapi.book11
-
python爬虫实现爬取同一个网站的多页数据的实例讲解
对于一个网站的图片.文字音视频等,如果我们一个个的下载,不仅浪费时间,而且很容易出错.Python爬虫帮助我们获取需要的数据,这个数据是可以快速批量的获取.本文小编带领大家通过python爬虫获取获取总页数并更改url的方法,实现爬取同一个网站的多页数据. 一.爬虫的目的 从网上获取对你有需要的数据 二.爬虫过程 1.获取url(网址). 2.发出请求,获得响应. 3.提取数据. 4.保存数据. 三.爬虫功能 可以快速批量的获取想要的数据,不用手动的一个个下载(图片.文字音视频等) 四.使用py
-
使用Python爬取Json数据的示例代码
一年一度的双十一即将来临,临时接到了一个任务:统计某品牌数据银行中自己品牌分别在2017和2018的10月20日至10月31日之间不同时间段的AIPL("认知"(Aware)."兴趣"(Interest)."购买"(Purchase)."忠诚"(Loyalty))流转率. 使用Fiddler获取到目标地址为: https://databank.yushanfang.com/api/ecapi?path=/databank/cr
-
python selenium实现智联招聘数据爬取
一.主要目的 最近在玩Python网络爬虫,然后接触到了selenium这个模块,就捉摸着搞点有意思的,顺便记录一下自己的学习过程. 二.前期准备 操作系统:windows10 浏览器:谷歌浏览器(Google Chrome) 浏览器驱动:chromedriver.exe (我的版本->89.0.4389.128 ) 程序中我使用的模块 import csv import os import re import json import time import requests from sele