详解Python对某地区二手房房价数据分析
目录
- 房价数据分析
- 数据简单清洗
- 各区均价分析
- 全市二手房装修程度分析
- 各区二手房数量所占比比例
- 热门户型均价分析
- 总结
房价数据分析
数据简单清洗
data.csv
数据显示
# 导入模块
import pandas as pd # 导入数据统计模块
import matplotlib # 导入图表模块
import matplotlib.pyplot as plt # 导入绘图模块
# 避免中文乱码
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为SimHei显示中文
matplotlib.rcParams['axes.unicode_minus'] = False # 设置正常显示字符,使用rc配置文件来自定义
# 简单清洗
data = pd.read_csv('data.csv') # 读取csv数据
del data['Unnamed: 0'] # 将索引列删除
data.dropna(axis=0, how='any', inplace=True) # 删除data数据中的所有空值
data['单价'] = data['单价'].map(lambda d: d.replace('元/平米', '')) # 将单价“元/平米”去掉
data['单价'] = data['单价'].astype(float) # 将房子单价转换为浮点类型,float(data['',单价])
data['总价'] = data['总价'].map(lambda d: d.replace('万', '')) # 将总价“万”去掉
data['总价'] = data['总价'].astype(float) # 将房子总价转换为浮点类型,float(data['',单价])
data['建筑面积'] = data['建筑面积'].map(lambda p: p.replace('平米', '')) # 将建筑面积“平米去掉”
data['建筑面积'] = data['建筑面积'].astype(float) # 将将建筑面积转换为浮点类型
各区均价分析
# 获取各区二手房均价分析,根据需求,,进一步处理数据,如果要写相应算法,需要根据算法所需求的数据处理
def get_average_price():
group = data.groupby('区域') # 将房子区域分组
average_price_group = group['单价'].mean() # 计算每个区域的均价,average_price_group字典
x = average_price_group.index # 区域
y = average_price_group.values.astype(int) # 区域对应的均价a =['t':'123'] a.keys()
return x, y # 返回区域与对应的均价,region二关 average_price均价
# 显示均价条形图
def average_price_bar(x, y, title):
plt.figure() # 图形画布
plt.bar(x, y, alpha=0.8) # 绘制条形图
plt.xlabel("区域") # 区域文字
plt.ylabel("均价") # 均价文字
plt.title(title) # 表标题文字
# 为每一个图形加数值标签
for x, y in enumerate(y):
plt.text(x, y + 100, y, ha='center')
plt.show()
if __name__ == '__main__':
x, y = get_average_price()
title = '各区均价分析'
average_price_bar(x, y, title)
运行如图

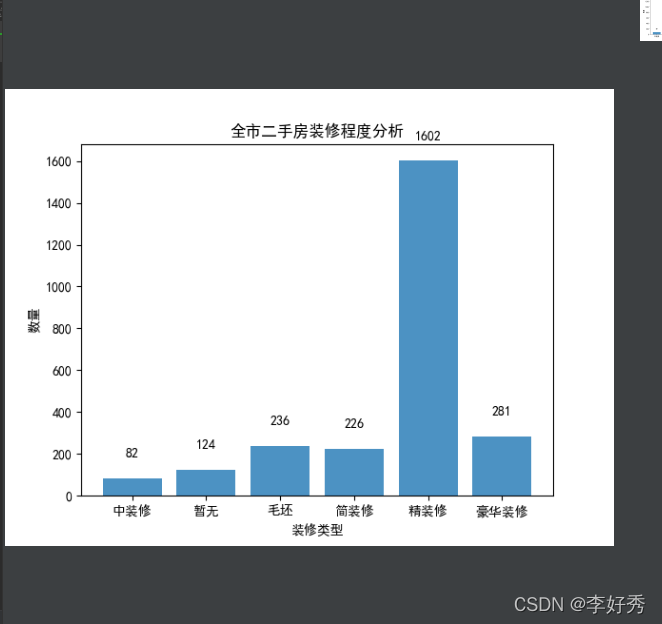
全市二手房装修程度分析
# 获取各区二手房均价分析,根据需求,,进一步处理数据,如果要写相应算法,需要根据算法所需求的数据处理
def get_decorate_sum():
group = data.groupby('装修') # 将房子区域分组
# decorate_sum_group = group['装修'].count() # 计算每个区域的均价,average_price_group字典
decorate_sum_group = group.size() # 计算每个区域的均价,average_price_group字典
x = decorate_sum_group.index # 区域
y = decorate_sum_group.values.astype(int) # 区域对应的均价a =['t':'123'] a.keys()
return x, y # 返回区域与对应的均价,region二关 average_price均价
# 显示均价条形图
def average_price_bar(x, y, title):
plt.figure() # 图形画布
plt.bar(x, y, alpha=0.8) # 绘制条形图
plt.xlabel("装修类型") # 区域文字
plt.ylabel("数量") # 均价文字
plt.title(title) # 表标题文字
# 为每一个图形加数值标签
for x, y in enumerate(y):
plt.text(x, y + 100, y, ha='center')
plt.show()
if __name__ == '__main__':
x, y = get_decorate_sum()
title = '全市二手房装修程度分析'
average_price_bar(x, y, title)
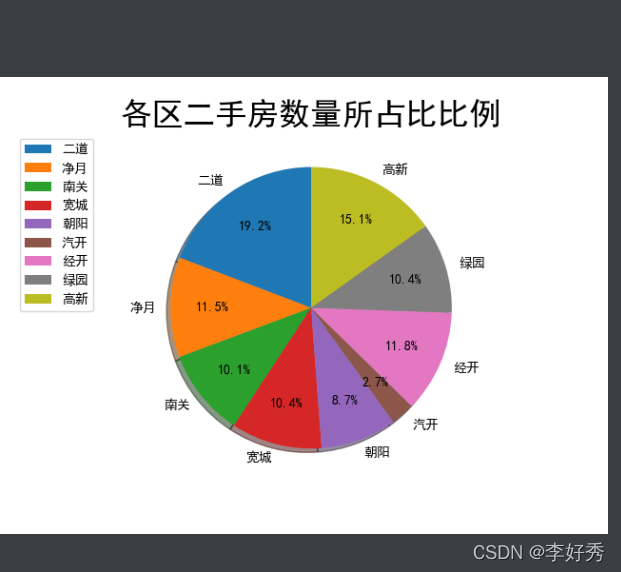
各区二手房数量所占比比例
# 获取各区二手房各区比例数量,进一步处理数据,如果要写相应算法,需要根据算法所需求的数据处理
def get_proportional_quantity():
area = data['区域'].groupby(data['区域']).count() # 将房子区域分组比例数量
areaName = (area).index.values # 将房子区域分组比例取名
return area, areaName
# 显示均价条形图
def proportional_quantity_pie(area, areaName, title):
plt.figure() # 图形画布
plt.pie(area, labels=areaName, labeldistance=1.1, autopct='%.1f%%',
shadow=True, startangle=90, pctdistance=0.7)
plt.title(title, fontsize=24) # 表标题文字
plt.legend(bbox_to_anchor=(-0.1, 1)) # 作者标题
plt.show()
if __name__ == '__main__':
# 对应x,y
area, areaName = get_proportional_quantity()
title = '各区二手房数量所占比比例'
proportional_quantity_pie(area, areaName, title)
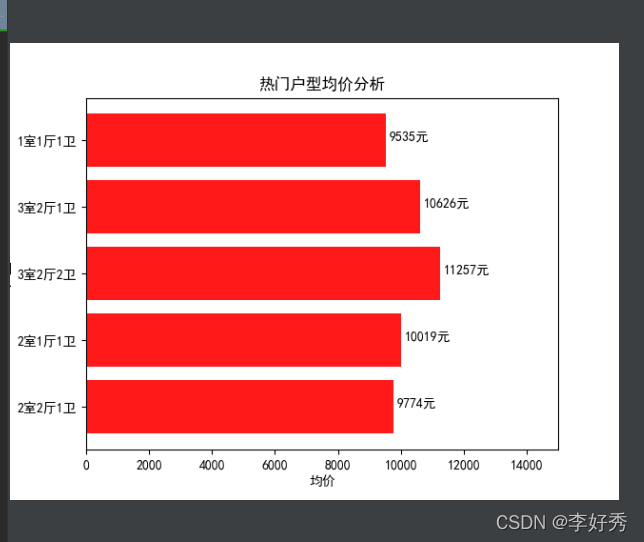
热门户型均价分析
# 获取各区热门户型分析,根据需求,,进一步处理数据,如果要写相应算法,需要根据算法所需求的数据处理
def get_hot_portal():
# 另外一种方法获取并取值
"""
group = data.groupby('户型').size # 将房子区域分组
sort_data = group.sort_values(ascending=False) # 将户型分组数量进行降序
five_data = sort_data.head() # 提取前5组户型数据
house_type_mean = data.groupby('户型')['单价'].mean().astype(int) # 计算每个户型的均价
x = house_type_mean[five_data.index].index # 户型
y = house_type_mean[five_data.index].value # 户型对应的均价
"""
group = data.groupby('户型') # 将房子区域分组
a = group['户型'].count().sort_values(ascending=False).head() # 计算每个户型的均价 字典
b = group['单价'].mean()[a.index] # 区域对应的均价a =['t':'123'] a.keys()
x = b.index
y = b.values.astype(int)
return x, y # 返回区域与对应的均价,region二关 average_price均价
# 显示均价横条形图
def hot_portal_barh(x, y, title):
plt.figure() # 图形画布
plt.barh(x, y, alpha=0.9, color='red') # 绘制条形图
plt.xlabel("均价") # 区域文字
plt.ylabel("户型") # 均价文字
plt.title(title) # 表标题文字
plt.xlim(0, 15000) # X轴的大小
# 为每一个图形加数值标签
for y, x in enumerate(y):
plt.text(x + 100, y, str(x) + '元', ha='left')
plt.show()
if __name__ == '__main__':
x, y = get_hot_portal()
title = '热门户型均价分析'
hot_portal_barh(x, y, title)
前面三个图较简单,最后相对于前面三个较为麻烦
先获取得到热门户型前五名,通过户型得到对应的户型的平均值
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

python使用dabl几行代码实现数据处理分析及ML自动化
目录 dabl 1.数据预处理 2.探索性数据分析 3.建模 结论 数据科学模型开发涉及各种组件,包括数据收集.数据处理.探索性数据分析.建模和部署.在训练机器学习或深度学习模型之前,必须清洗数据集并使其适合训练.通常这些过程是重复的,且占用了大部时间. 为了克服这个问题,今天我分享一个名为 dabl 的开源 Python 工具包,它可以自动化机器学习模型开发,包括数据预处理.特征可视化和分析.建模.欢迎收藏学习,喜欢点赞支持. dabl dabl 是一个数据分析基线库,可以让机器学习建模更容易
-
python数据可视化使用pyfinance分析证券收益示例详解
目录 pyfinance简介 pyfinance包含六个模块 returns模块应用实例 收益率计算 CAPM模型相关指标 风险指标 基准比较指标 风险调整收益指标 综合业绩评价指标分析实例 结语 pyfinance简介 在查找如何使用Python实现滚动回归时,发现一个很有用的量化金融包--pyfinance.顾名思义,pyfinance是为投资管理和证券收益分析而构建的Python分析包,主要是对面向定量金融的现有包进行补充,如pyfolio和pandas等. pyfinance包含六个模块
-
Python实现微信好友数据爬取及分析
前言 随着微信的普及,越来越多的人开始使用微信.微信渐渐从一款单纯的社交软件转变成了一个生活方式,人们的日常沟通需要微信,工作交流也需要微信.微信里的每一个好友,都代表着人们在社会里扮演的不同角色. 今天这篇文章会基于Python对微信好友进行数据分析,这里选择的维度主要有:性别.头像.签名.位置,主要采用图表和词云两种形式来呈现结果,其中,对文本类信息会采用词频分析和情感分析两种方法.常言道:工欲善其事,必先利其器也.在正式开始这篇文章前,简单介绍下本文中使用到的第三方模块: itchat:微
-
python数据分析近年比特币价格涨幅趋势分布
目录 使用技术点: 使用工具: 导入第三方库 大家好,我是辣条. 曾经有一个真挚的机会,摆在我面前,但是我没有珍惜,等到失去的时候才后悔莫及,尘世间最痛苦的事莫过于此,如果老天可以再给我一个再来一次机会的话,我会买下那个比特币,哪怕付出所有零花钱,如果非要在这个机会加上一个期限的话,我希望是十年前. 看着这份台词是不是很眼熟,我稍稍改了一下,曾经差一点点点就购买比特币了,肠子都悔青了现在,今天对比特币做一个简单的数据分析. # 安装对应的第三方库 !pip install pandas !pip
-
Python人工智能之波士顿房价数据分析
目录 1.数据概览分析 1.1 数据概览 1.2 数据分析 2. 项目总体思路 2.1 数据读取 2.2 模型预处理 (1)数据离群点处理 (2)数据归一化处理 2.3. 特征工程 2.4. 模型选择 2.5. 模型评价 2.6. 模型调参 3. 项目总结 [人工智能项目]机器学习热门项目-波士顿房价 1.数据概览分析 1.1 数据概览 本次提供: train.csv,训练集: test.csv,测试集: submission.csv 真实房价文件: 训练集404行数据,14列,每行数据表示房屋
-
详解Python对某地区二手房房价数据分析
目录 房价数据分析 数据简单清洗 各区均价分析 全市二手房装修程度分析 各区二手房数量所占比比例 热门户型均价分析 总结 房价数据分析 数据简单清洗 data.csv 数据显示 # 导入模块 import pandas as pd # 导入数据统计模块 import matplotlib # 导入图表模块 import matplotlib.pyplot as plt # 导入绘图模块 # 避免中文乱码 matplotlib.rcParams['font.sans-serif'] = ['Sim
-
详解python中groupby函数通俗易懂
一.groupby 能做什么? python中groupby函数主要的作用是进行数据的分组以及分组后地组内运算! 对于数据的分组和分组运算主要是指groupby函数的应用,具体函数的规则如下: df[](指输出数据的结果属性名称).groupby([df[属性],df[属性])(指分类的属性,数据的限定定语,可以有多个).mean()(对于数据的计算方式--函数名称) 举例如下: print(df["评分"].groupby([df["地区"],df["类
-
详解Python中的枚举类型
目录 什么是枚举类型 为什么要使用枚举 如何使用枚举 从字典创建枚举 最后的话 你好,我是 征哥,今天分享一下 Python 中的枚举类型,为什么需要枚举类型,及如何使用. 什么是枚举类型 枚举(Enum)是一种数据类型,是绑定到唯一值的符号表示.您可以使用它来创建用于变量和属性的常量集.它们类似于全局变量,但是,它们提供了更有用的功能,例如分组和类型安全.Python 在 3.4 版本中添加了标准库 enum. 为什么要使用枚举 使用枚举有以下好处: 代码更容易阅读,更容易维护. 减少由转换或
-
详解python里使用正则表达式的分组命名方式
详解python里使用正则表达式的分组命名方式 分组匹配的模式,可以通过groups()来全部访问匹配的元组,也可以通过group()函数来按分组方式来访问,但是这里只能通过数字索引来访问,如果某一天产品经理需要修改需求,让你在它们之中添加一个分组,这样一来,就会导致匹配的数组的索引的变化,作为开发人员的你,必须得一行一行代码地修改.因此聪明的开发人员又想到一个好方法,把这些分组进行命名,只需要对名称进行访问分组,不通过索引来访问了,就可以避免这个问题.那么怎么样来命名呢?可以采用(?P<nam
-
详解Python实现多进程异步事件驱动引擎
本文介绍了详解Python实现多进程异步事件驱动引擎,分享给大家,具体如下: 多进程异步事件驱动逻辑 逻辑 code # -*- coding: utf-8 -*- ''' author: Jimmy contact: 234390130@qq.com file: eventEngine.py time: 2017/8/25 上午10:06 description: 多进程异步事件驱动引擎 ''' __author__ = 'Jimmy' from multiprocessing import
-
详解Python import方法引入模块的实例
详解Python import方法引入模块的实例 在Python用import或者from-import或者from-import-as-来导入相应的模块,作用和使用方法与C语言的include头文件类似.其实就是引入某些成熟的函数库和成熟的方法,避免重复造轮子,提高开发速度. python的import方法可以引入系统的模块,也可以引入我们自己写好的共用模块,这点和PHP非常相似,但是它们的具体细节还不是很一样.因为php是在引入的时候指明引入文件的具体路径,而python中不能够写文件路径进
-
详解python中executemany和序列的使用方法
详解python中executemany和序列的使用方法 一 代码 import sqlite3 persons=[ ("Jim","Green"), ("Hu","jie") ] conn=sqlite3.connect(":memory:") conn.execute("CREATE TABLE person(firstname,lastname)") conn.executeman
-
详解Python 序列化Serialize 和 反序列化Deserialize
详解Python 序列化Serialize 和 反序列化Deserialize 序列化 (serialization) 序列化是将对象状态转换为可保持或传输的格式的过程.与序列化相对的是反序列化, 它将流转换为对象.这两个过程结合起来,可以轻松地存储和传输数据. 序列化和反序列化的目的 1.以某种存储形式使自定义对象持久化: 2.将对象从一个地方传递到另一个地方. 3.使程序更具维护性 序列化 由于存在于内存中的对象都是暂时的,无法长期驻存,为了把对象的状态保持下来,这时需要把对象写入到磁盘
-
详解python里使用正则表达式的全匹配功能
详解python里使用正则表达式的全匹配功能 python中很多匹配,比如搜索任意位置的search()函数,搜索边界的match()函数,现在还需要学习一个全匹配函数,就是搜索的字符与内容全部匹配,它就是fullmatch()函数. 例子如下: #python 3.6 #蔡军生 #http://blog.csdn.net/caimouse/article/details/51749579 # import re text = 'This is some text -- with punctua
-
详解python实现读取邮件数据并下载附件的实例
详解python实现读取邮件数据并下载附件的实例 实现结果图: 实现代码: #!/usr/bin/python2.7 # _*_ coding: utf-8 _*_ """ @Author: MarkLiu """ import poplib import email from email.parser import Parser from email.header import decode_header from email.utils im