如何基于windows实现python定时爬虫
Windows系统下使用任务计划程序,Linux下可以使用crontab命令添加自启动计划。
这里写Windows 10 / windows Server 2016系统的设置方法。
首先编写一个.bat脚本。新建一个txt,将下面三行代码复制进去,main.py改成自己程序名字。保存为.bat文件,放在对应的.py文件同一目录。
这时候点击.bat文件即可执行py文件。然后我们将.bat脚本设置自启动。
@echo offstart python main.py %*exit
按下图点开任务计划程序。

创建基本任务,填写名称,下一步。

这里可以设置想要自启动频率。

然后设置自启动的时间。

任务执行操作为启动程序。
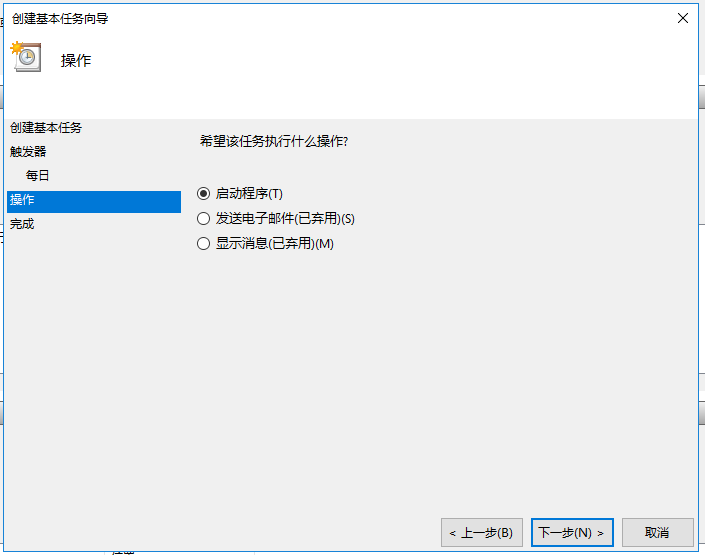
选择自启动的脚本。“起始于”那里填写脚本的目录路径。

红框处打钩。

选择操作系统版本。

设置完成。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
windows下搭建python scrapy爬虫框架步骤
网络上现有的windows下搭建scrapy教程都比较旧,一般都是咔咔咔安装一堆软件,太麻烦,这是因为scrapy框架用到好多不同的模块,其实查阅最新的官网scrapy文档,在windows下搭建scrapy框架,官方文档是建议使用集成包的,以免安装太过复杂而出现问题,首先百度scrapy,就可以找到scrapy的官方文档 1.找到windows下的框架安装的文档教程,这里建议我们安装Anaconda或者Miniconda集成包,下面我选择安装Miniconda安装包来安装scrapy框架 2.
-
Linux部署python爬虫脚本,并设置定时任务的方法
去年因项目需要,用python写了个爬虫.因爬到的数据需要存到生产环境的PG数据库.所以需要将脚本部署到CentOS服务器,并设置定时任务,自动启动脚本. 实施步骤如下: 1.安装pip(操作系统自带了python2.6可以直接用,但是没有pip) # 下载pip安装包 wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=834b2904f92d46aaa333267fb1c922bb" --
-
python 每天如何定时启动爬虫任务(实现方法分享)
python2.7环境下运行 安装相关模块 想要每天定时启动,最好是把程序放在linux服务器上运行,毕竟linux可以不用关机,即定时任务一直存活: #coding:utf8 import datetime import time def doSth(): # 把爬虫程序放在这个类里 print(u'这个程序要开始疯狂的运转啦') # 一般网站都是1:00点更新数据,所以每天凌晨一点启动 def main(h=1,m=0): while True: now = datetime.datetim
-
python 爬虫 实现增量去重和定时爬取实例
前言: 在爬虫过程中,我们可能需要重复的爬取同一个网站,为了避免重复的数据存入我们的数据库中 通过实现增量去重 去解决这一问题 本文还针对了那些需要实时更新的网站 增加了一个定时爬取的功能: 本文作者同开源中国(殊途同归_): 解决思路: 1.获取目标url 2.解析网页 3.存入数据库(增量去重) 4.异常处理 5.实时更新(定时爬取) 下面为数据库的配置 mysql_congif.py: import pymysql def insert_db(db_table, issue, time_s
-

windows7 32、64位下python爬虫框架scrapy环境的搭建方法
适用于python 2.7 64位安装 一.操作系统:WIN7 64位 二.python版本:2.7 64位(scrapy目前不支持3.x) 不确定位数的,看图 三.安装相关软件(可以从我的百度网盘下载:链接: https://pan.baidu.com/s/1MzHNALJcRePSoaEqBQvGAQ 提取码: xd5e ) 我配置环境的时候是直接pip install scrapy安装的,但是在过程中出现一些错误,发现是由于以下软件安装失败导致的.所以请先安装这4个相关软件再安装scrap
-
浅析python实现scrapy定时执行爬虫
项目需要程序能够放在超算中心定时运行,于是针对scrapy写了一个定时爬虫的程序main.py ,直接放在scrapy的存储代码的目录中就能设定时间定时多次执行. 最简单的方法:直接使用Timer类 import time import os while True: os.system("scrapy crawl News") time.sleep(86400) #每隔一天运行一次 24*60*60=86400s或者,使用标准库的sched模块 import sched #初始化sch
-
如何基于windows实现python定时爬虫
Windows系统下使用任务计划程序,Linux下可以使用crontab命令添加自启动计划. 这里写Windows 10 / windows Server 2016系统的设置方法. 首先编写一个.bat脚本.新建一个txt,将下面三行代码复制进去,main.py改成自己程序名字.保存为.bat文件,放在对应的.py文件同一目录. 这时候点击.bat文件即可执行py文件.然后我们将.bat脚本设置自启动. @echo offstart python main.py %*exit 按下图点开任务计划
-
asp.net基于windows服务实现定时发送邮件的方法
本文实例讲述了asp.net基于windows服务实现定时发送邮件的方法.分享给大家供大家参考,具体如下: //定义组件 private System.Timers.Timer time; public int nowhour; public int minutes; public string sendTime; public Thread th; public string isOpen;//是否启用定时发送 public string strToEUser; public static i
-
python基于windows平台锁定键盘输入的方法
本文实例讲述了python基于windows平台锁定键盘输入的方法.分享给大家供大家参考.具体分析如下: pywin32中没有BlockInput这个函数.VC++中有,发现这个方法就可以了. 该代码可阻断windows平台下的鼠标键盘输入,如下所示: # coding: UTF-8 import time from ctypes import * user32 = windll.LoadLibrary('user32.dll') user32.BlockInput(True); time.sl
-
用python写一个windows下的定时关机脚本(推荐)
由于本人经常使用笔记本共享WiFi,但是又不想笔记本开机一夜(为了低碳环保嘛 ~_~!),所以每次都要用使用DOS命令关机,感觉好麻烦.正好最近在学习Python,于是决定用python写一个定时关机的脚本: 话不多说由于代码比较简单,直接上代码. 代码块 # -*- coding: utf-8 -*- """ Created on Sat Dec 19 11:18:16 2015 @author: win7 """ '''定时关机''' '''
-
基于windows下pip安装python模块时报错总结
这几天把python版本升级后,发现pip安装模块好多都报错(暂不确定是不是因为升级导致的),我定睛一看,发现是权限的问题,那么怎么解决呢? 1 权限问题 C:\Users\ljf>pip install xlwt Exception: Traceback (most recent call last): File "c:\program files\python35\lib\site-packages\pip\basecommand.py", line 21 1, in mai
-
python中用Scrapy实现定时爬虫的实例讲解
一般网站发布信息会在具体实现范围内发布,我们在进行网络爬虫的过程中,可以通过设置定时爬虫,定时的爬取网站的内容.使用python爬虫框架Scrapy框架可以实现定时爬虫,而且可以根据我们的时间需求,方便的修改定时的时间. 1.Scrapy介绍 Scrapy是python的爬虫框架,用于抓取web站点并从页面中提取结构化的数据.任何人都可以根据需求方便的修改.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试. 2.使用Scrapy框架定时爬取 import time from scrapy
-
Python网络爬虫与信息提取(实例讲解)
课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解析HTML页面 4.Re框架:正则框架,提取页面关键信息 5.Scrapy框架:网络爬虫原理介绍,专业爬虫框架介绍 理念:The Website is the API ... Python语言常用的IDE工具 文本工具类IDE: IDLE.Notepad++.Sublime Text.Vim & Emacs.Atom.Komodo E
-
Python使用爬虫抓取美女图片并保存到本地的方法【测试可用】
本文实例讲述了Python使用爬虫抓取美女图片并保存到本地的方法.分享给大家供大家参考,具体如下: 图片资源来自于www.qiubaichengren.com 代码基于Python 3.5.2 友情提醒:血气方刚的骚年.请 谨慎阅图! 谨慎阅图!! 谨慎阅图!!! code: #!/usr/bin/env python # -*- coding: utf-8 -*- import os import urllib import urllib.request import re from urll
-
详解python定时简单爬取网页新闻存入数据库并发送邮件
本人小白一枚,简单记录下学校作业项目,代码十分简单,主要是对各个库的理解,希望能给别的初学者一点启发. 一.项目要求 1.程序可以从北京工业大学首页上爬取新闻内容:http://www.bjut.edu.cn 2.程序可以将爬取下来的数据写入本地MySQL数据库中. 3.程序可以将爬取下来的数据发送到邮箱. 4.程序可以定时执行. 二.项目分析 1.爬虫部分利用requests库爬取html文本,再利用bs4中的BeaultifulSoup库来解析html文本,提取需要的内容. 2.使用pymy
-
一文读懂python Scrapy爬虫框架
Scrapy是什么? 先看官网上的说明,http://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. S