Python批量将csv文件编码方式转换为UTF-8的实战记录
当我们用pandas是操作CSV文件的时候,常常会因为编码问题出现报错。
pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader.read()
pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader._read_low_memory()
pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader._read_rows()
pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader._convert_column_data()
pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader._convert_tokens()
pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader._convert_with_dtype()
pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader._string_convert()
pandas_libs\parsers.pyx in pandas._libs.parsers._string_box_utf8()
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xca in position 0: invalid continuation byte
如果只是一两个文件,我们可以用系统自带记事本的方法进行解决:
1、右键csv文件,打开方式选择“记事本”打开;
2、ctrl+shift+s另存为,将编码方式由ansi给改为UTF-8,点击确定并替换原文件。

嫌麻烦的也可以在每次用pandas读取csv前加入以下代码。
import pandas as pd
filename='222.csv'
try:
df = pd.read_csv(filename, encoding='utf-8')
except BaseException:
df = pd.read_csv(filename, encoding='cp950')
df.to_csv(filename, encoding='utf-8', index=False)
如果很多类似的ASCII的CSV文件就会非常头痛,下面我们用Python编写一个程序,用来检测并批量转换csv文件的编码方式。
需要指出的是,这个程序并不完善,运行速度没有进行优化,并且仍然有部分文件未能转换成功,但足以应对日常的分析需要。经过尝试,有几种csv文件无法转换:
1、包含图片或者图表的csv文件
2、原先的csv文件内容就是乱码的
觉得有帮助,那请给这篇文章点个赞吧️
演示效果:
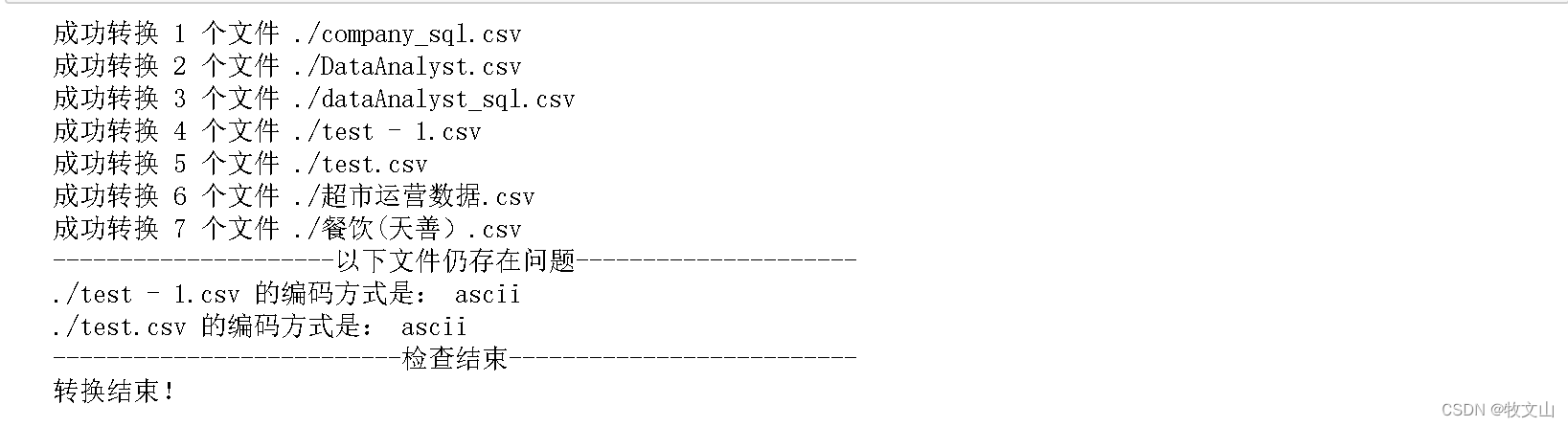
代码:
import os
from chardet.universaldetector import UniversalDetector
def get_filelist(path):
"""
获取路径下所有csv文件的路径列表
"""
Filelist = []
for home, dirs, files in os.walk(path):
for filename in files:
if ".csv" in filename:
Filelist.append(os.path.join(home, filename))
return Filelist
def read_file(file):
"""
逐个读取文件的内容
"""
with open(file, 'rb') as f:
return f.read()
def get_encode_info(file):
"""
逐个读取文件的编码方式
"""
with open(file, 'rb') as f:
detector = UniversalDetector()
for line in f.readlines():
detector.feed(line)
if detector.done:
break
detector.close()
return detector.result['encoding']
def convert_encode2utf8(file, original_encode, des_encode):
"""
将文件的编码方式转换为utf-8,并写入原先的文件中。
"""
file_content = read_file(file)
file_decode = file_content.decode(original_encode, 'ignore')
file_encode = file_decode.encode(des_encode)
with open(file, 'wb') as f:
f.write(file_encode)
def read_and_convert(path):
"""
读取文件并转换
"""
Filelist = get_filelist(path=path)
fileNum= 0
for filename in Filelist:
try:
file_content = read_file(filename)
encode_info = get_encode_info(filename)
if encode_info != 'utf-8':
fileNum +=1
convert_encode2utf8(filename, encode_info, 'utf-8')
print('成功转换 %s 个文件 %s '%(fileNum,filename))
except BaseException:
print(filename,'存在问题,请检查!')
def recheck_again(path):
"""
再次判断文件是否为utf-8
"""
print('---------------------以下文件仍存在问题---------------------')
Filelist = get_filelist(path)
for filename in Filelist:
encode_info_ch = get_encode_info(filename)
if encode_info_ch != 'utf-8':
print(filename,'的编码方式是:',encode_info_ch)
print('--------------------------检查结束--------------------------')
if __name__ == "__main__":
"""
输入文件路径
"""
path = './'
read_and_convert(path)
recheck_again(path)
print('转换结束!')
核心代码是:
def get_encode_info(file):
"""
逐个读取文件的编码方式
"""
with open(file, 'rb') as f:
detector = UniversalDetector()
for line in f.readlines():
detector.feed(line)
if detector.done:
break
detector.close()
return detector.result['encoding']
Filelist = get_filelist(path=path)
fileNum= 0
for filename in Filelist:
try:
file_content = read_file(filename)
encode_info = get_encode_info(filename)
if encode_info != 'utf-8':
fileNum +=1
convert_encode2utf8(filename, encode_info, 'utf-8')
print('成功转换 %s 个文件 %s '%(fileNum,filename))
except BaseException:
print(filename,'存在问题,请检查!')
总结
到此这篇关于Python批量将csv文件编码方式转换为UTF-8的文章就介绍到这了,更多相关Python批量转换csv文件编码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python批量转换文件编码格式
自己写的方法,适用于linux, #!/usr/bin/python #coding=utf-8 import sys import os, os.path import dircache import commands def add(x,y): return x*y def trans(dirname): lis = dircache.opendir(dirname) for a in lis: af=dirname+os.sep+a ## print af if os.path.isdir
-
使用python批量转换文件编码为UTF-8的实现
由于这两天换了IDE,在导入以前的工程的时候发现了一个大问题,由于以前脑残的我不知道改编码方式,导致出现了大量的GBK,这就很难受,要是一个两个还好说,可是这么多要是一个一个的改我会觉得现在的我比以前还脑残,于是乎,我就想用python批量的修改一下,然后就产生了这篇文章,其中好多不足的地方还请大佬指导 本来一开始的思路还是比较清晰,觉得也比较简单,天真的认为用GBK的方式读取出文件内容,然后UTF8写入就好了,可是在实际的操作中我发现我就是太天真了,出现了大量的问题,比如说: 怎么查看文件的编
-
Python实现批量转换文件编码的方法
本文实例讲述了Python实现批量转换文件编码的方法.分享给大家供大家参考.具体如下: 这里将某个目录下的所有文件从一种编码转换为另一种编码,然后保存 import os import shutil def match(config,fullpath,type): flag=False if type == 'exclude': for item in config['src']['exclude']: if fullpath.startswith(config['src']['path']+o
-
python实现批量转换文件编码(批转换编码示例)
复制代码 代码如下: # -*- coding:utf-8 -*-__author__ = 'walkskyer' import osimport glob class Encoding: def __init__(self): #文件扩展名 self.ext = ".*" #编码 self.srcEncoding=None self.dstEncoding=None def convertEncoding(s
-

Python批量将csv文件编码方式转换为UTF-8的实战记录
当我们用pandas是操作CSV文件的时候,常常会因为编码问题出现报错. pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader.read() pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader._read_low_memory() pandas_libs\parsers.pyx in pandas._libs.parsers.TextReader._read_rows
-
Python批量将csv文件转化成xml文件的实例
一.前言 逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本).纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据.CSV文件由任意数目的记录组成,记录间以某种换行符分隔:每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符.通常,所有记录都有完全相同的字段序列,通常都是纯文本文件. 可扩展标记语言,标准通用标记语言的子集,简称XML.是一种用
-
python批量实现Word文件转换为PDF文件
本文为大家分享了python批量转换Word文件为PDF文件的具体方法,供大家参考,具体内容如下 1.目的 通过万能的Python把一个目录下的所有Word文件转换为PDF文件. 2.遍历目录 作者总结了三种遍历目录的方法,分别如下. 2.1.调用glob 遍历指定目录下的所有文件和文件夹,不递归遍历,需要手动完成递归遍历功能. import glob as gb path = gb.glob('d:\\2\\*') for path in path: print path 2.2.调用os.w
-
Python Pandas批量读取csv文件到dataframe的方法
PYTHON Pandas批量读取csv文件到DATAFRAME 首先使用glob.glob获得文件路径.然后定义一个列表,读取文件后再使用concat合并读取到的数据. #读取数据 import pandas as pd import numpy as np import glob,os path=r'e:\tj\month\fx1806' file=glob.glob(os.path.join(path, "zq*.xls")) print(file) dl= [] for f i
-
Python中的CSV文件使用"with"语句的方式详解
是否可以直接使用with语句与CSV文件?能够做这样的事情似乎很自然: import csv with csv.reader(open("myfile.csv")) as reader: # do things with reader 但是csv.reader不提供__enter__和__exit__方法,所以这不行.但是我可以分两步做: import csv with open("myfile.csv") as f: reader = csv.reader(f)
-
利用python合并csv文件的方式实例
目录 1.用concat方法合并csv 2.glob模块批量合并csv 补充:Python处理(加载.合并)多个csv文件 总结 1.用concat方法合并csv 将两个相同的csv文件进行数据合并,通过pandas的read_csv和to_csv来完成,即采用concat方法: #加载第三方库 import pandas as pd import numpy as np #读取文件 df1 = pd.read_csv("文件-1.csv") df2 = pd.read_csv(&qu
-
使用Python pandas读取CSV文件应该注意什么?
示例文件 将以下内容保存为文件 people.csv. id,姓名,性别,出生日期,出生地,职业,爱好 1,张小三,m,1992-10-03,北京,工程师,足球 2,李云义,m,1995-02-12,上海,程序员,读书 下棋 3,周娟,女,1998-03-25,合肥,护士,音乐,跑步 4,赵盈盈,Female,2001-6-32,,学生,画画 5,郑强强,男,1991-03-05,南京(nanjing),律师,历史-政治 如果一切正常的话,在Jupyter Notebook 中应该显示以下内容:
-
Python pandas读取CSV文件的注意事项(适合新手)
目录 前言 示例文件 文件编码 空值 日期错误 函数映射 方法1:直接使用labmda表达式 方法二:使用自定义函数 方法三:使用数值字典映射 总结 前言 本文是给使用pandas的新手而写,主要列出一些常见的问题,根据笔者所踩过的坑,进行归纳总结,希望对读者有所帮助. 示例文件 将以下内容保存为文件 people.csv. id,姓名,性别,出生日期,出生地,职业,爱好 1,张小三,m,1992-10-03,北京,工程师,足球 2,李云义,m,1995-02-12,上海,程序员,读书 下棋 3
-
Python批量提取PDF文件中文本的脚本
本文实例为大家分享了Python批量提取PDF文件中文本的具体代码,供大家参考,具体内容如下 首先需要执行命令pip install pdfminer3k来安装处理PDF文件的扩展库. import os import sys import time pdfs = (pdfs for pdfs in os.listdir('.') if pdfs.endswith('.pdf')) for pdf1 in pdfs: pdf = pdf1.replace(' ', '_').replace('-
-
python批量读取txt文件为DataFrame的方法
我们有时候会批量处理同一个文件夹下的文件,并且希望读取到一个文件里面便于我们计算操作.比方我有下图一系列的txt文件,我该如何把它们写入一个txt文件中并且读取为DataFrame格式呢? 首先我们要用到glob模块,这个python内置的模块可以说是非常的好用. glob.glob('*.txt') 得到如下结果: all.txt是我最后得到的结果文件.可以见返回的是一个包含txt文件名称的列表,当然如果你的文件夹下面只有txt文件,那么你用os.listdir()可以得到一个一样的列表 然后