HashMap在JDK7与JDK8中的实现过程解析
HashMap的实现原理
首先有一个每个元素都是链表(可能表述不准确)的数组,当添加一个元素(key-value)时,就首先计算元素key的hash值,以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了,这时就添加到同一hash值的元素的后面,他们在数组的同一位置,但是形成了链表,同一各链表上的Hash值是相同的,所以说数组存放的是链表。而当链表长度太长时,链表就转换为红黑树,这样大大提高了查找的效率。 当链表数组的容量超过初始容量的0.75时,再散列将链表数组扩大2倍,把原链表数组的搬移到新的数组中
即HashMap的原理图是:

现在我来分析下JDK7与JDK8中HashMap的实现过程。
JDK7中的HashMap
HashMap底层维护一个数组,数组中的每一项都是一个Entry
transient Entry<K,V>[] table;
我们向 HashMap 中所放置的对象实际上是存储在该数组当中;
而Map中的key,value则以Entry的形式存放在数组中
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
而这个Entry应该放在数组的哪一个位置上(这个位置通常称为位桶或者hash桶,即hash值相同的Entry会放在同一位置,用链表相连),是通过key的hashCode来计算的。
final int hash(Object k) {
int h = 0;
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
通过hash计算出来的值将会使用indexFor方法找到它应该所在的table下标:
static int indexFor(int h, int length) {
return h & (length-1);
}
这个方法其实相当于对table.length取模。
当两个key通过hashCode计算相同时,则发生了hash冲突(碰撞),HashMap解决hash冲突的方式是用链表。
当发生hash冲突时,则将存放在数组中的Entry设置为新值的next(这里要注意的是,比如A和B都hash后都映射到下标i中,之前已经有A了,当map.put(B)时,将B放到下标i中,A则为B的next,所以新值存放在数组中,旧值在新值的链表上)
示意图:
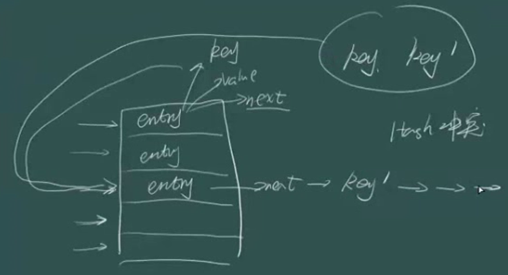
所以当hash冲突很多时,HashMap退化成链表。
总结一下map.put后的过程:
当向 HashMap 中 put 一对键值时,它会根据 key的 hashCode 值计算出一个位置, 该位置就是此对象准备往数组中存放的位置。
如果该位置没有对象存在,就将此对象直接放进数组当中;如果该位置已经有对象存在了,则顺着此存在的对象的链开始寻找(为了判断是否是否值相同,map不允许<key,value>键值对重复), 如果此链上有对象的话,再去使用 equals方法进行比较,如果对此链上的每个对象的 equals 方法比较都为 false,则将该对象放到数组当中,然后将数组中该位置以前存在的那个对象链接到此对象的后面。
值得注意的是,当key为null时,都放到table[0]中
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
当size大于threshold时,会发生扩容。 threshold等于capacity*load factor
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
jdk7中resize,只有当 size>=threshold并且 table中的那个槽中已经有Entry时,才会发生resize。即有可能虽然size>=threshold,但是必须等到每个槽都至少有一个Entry时,才会扩容。还有注意每次resize都会扩大一倍容量
JDK8中的HashMap
一直到JDK7为止,HashMap的结构都是这么简单,基于一个数组以及多个链表的实现,hash值冲突的时候,就将对应节点以链表的形式存储。
这样子的HashMap性能上就抱有一定疑问,如果说成百上千个节点在hash时发生碰撞,存储一个链表中,那么如果要查找其中一个节点,那就不可避免的花费O(N)的查找时间,这将是多么大的性能损失。这个问题终于在JDK8中得到了解决。再最坏的情况下,链表查找的时间复杂度为O(n),而红黑树一直是O(logn),这样会提高HashMap的效率。
JDK7中HashMap采用的是位桶+链表的方式,即我们常说的散列链表的方式,而JDK8中采用的是位桶+链表/红黑树(有关红黑树请查看红黑树)的方式,也是非线程安全的。当某个位桶的链表的长度达到某个阀值的时候,这个链表就将转换成红黑树。
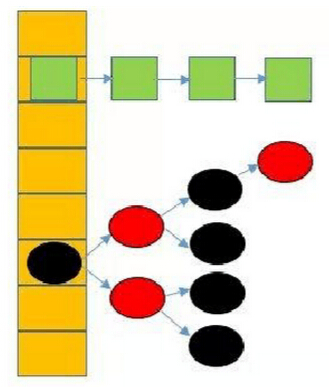
JDK8中,当同一个hash值的节点数不小于8时,将不再以单链表的形式存储了,会被调整成一颗红黑树(上图中null节点没画)。这就是JDK7与JDK8中HashMap实现的最大区别。
接下来,我们来看下JDK8中HashMap的源码实现。
JDK中Entry的名字变成了Node,原因是和红黑树的实现TreeNode相关联。
transient Node<K,V>[] table;
当冲突节点数不小于8-1时,转换成红黑树。
static final int TREEIFY_THRESHOLD = 8;
以put方法在JDK8中有了很大的改变
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
//如果当前map中无数据,执行resize方法。并且返回n
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果要插入的键值对要存放的这个位置刚好没有元素,那么把他封装成Node对象,放在这个位置上就完事了
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//否则的话,说明这上面有元素
else {
Node<K,V> e; K k;
//如果这个元素的key与要插入的一样,那么就替换一下,也完事。
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//1.如果当前节点是TreeNode类型的数据,执行putTreeVal方法
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//还是遍历这条链子上的数据,跟jdk7没什么区别
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//2.完成了操作后多做了一件事情,判断,并且可能执行treeifyBin方法
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) //true || --
e.value = value;
//3.
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//判断阈值,决定是否扩容
if (++size > threshold)
resize();
//4.
afterNodeInsertion(evict);
return null;
}
treeifyBin()就是将链表转换成红黑树。
之前的indefFor()方法消失 了,直接用(tab.length-1)&hash,所以看到这个,代表的就是数组的下角标。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
Reference:
1. http://www.tuicool.com/articles/Yruqiye
3. https://segmentfault.com/a/1190000003617333
4. http://blog.csdn.net/q291611265/article/details/46797557
到此这篇关于HashMap在JDK7与JDK8中的实现原理解析的文章就介绍到这了,更多相关JDK7与JDK8中HashMap的实现内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

HashMap红黑树入门(实现一个简单的红黑树)
目录 1.树结构入门 1.1 什么是树? 1.2 树结构常用术语 1.3 二叉搜索树 2.红黑树原理讲解 2.1 红黑树的性质: 2.2 红黑树案例分析 3.手写红黑树 4. HashMap底层的红黑树 5 将链表转换为红黑树 treeifyBin() 总结: JDK集合源码之HashMap解析 1.树结构入门 1.1 什么是树? 树(tree)是一种抽象数据类型(ADT),用来模拟具有树状结构性质的数据集合.它是由n(n>0)个有限节点通过连接它们的边组成一个具有层次关系的集合. 把它叫做&quo
-
jdk7 中HashMap的知识点总结
HashMap中的几个重要变量 默认初始容量,必须是2的n次方 static final int DEFAULT_INITIAL_CAPACITY = 16; 最大容量,当通过构造方法传入的容量比它还大时,就用这个最大容量,必须是2的n次方 static final int MAXIMUM_CAPACITY = 1 << 30; 默认负载因子 static final float DEFAULT_LOAD_FACTOR = 0.75f; 用来存储键值对,可以看到键值对都是存储在Entry中的
-
解析ConcurrentHashMap: 红黑树的代理类(TreeBin)
前一章是get.remove方法分析,喜欢的朋友点击查看.本篇为ConcurrentHashMap源码系列的最后一篇,来分析一下TreeBin 红黑树代理节点的源码: 1.TreeBin内部类分析 TreeBin是红黑树的代理,对红黑树不太了解的,可以参考: static final class TreeBin<K,V> extends Node<K,V> { // 红黑树根节点 TreeNode<K,V> root; // 链表的头节点 volatile TreeNo
-
JDK8中的HashMap初始化和扩容机制详解
一.HashMap初始化方法 HashMap() 不带参数,默认初始化大小为16,加载因子为0.75: HashMap(int initialCapacity) 指定初始化大小: HashMap(int initialCapacity, float loadFactor) 指定初始化大小和加载因子大小: HashMap(Map<? extends K,? extends V> m) 用现有的一个map来构造HashMap. 二.分析初始化过程 1.初始化代码测试用例 Map<String
-
为什么JDK8中HashMap依然会死循环
JDK8中HashMap依然会死循环! 是否你听说过JDK8之后HashMap已经解决的扩容死循环的问题,虽然HashMap依然说线程不安全,但是不会造成服务器load飙升的问题. 然而事实并非如此.少年可曾了解一种红黑树成环的场景,=v= 今日在查看监控时候发现,某一台机器load飙升 感觉问题不对劲,ssh大法登陆机器,top,top -Hp,jstack,jmap四连击保存下来堆栈,cpu使用最高的线程,内存信息准备分析. 首先查看使用最耗费cpu的线程堆栈信息 cat stack | g
-
HashMap在JDK7与JDK8中的实现过程解析
HashMap的实现原理 首先有一个每个元素都是链表(可能表述不准确)的数组,当添加一个元素(key-value)时,就首先计算元素key的hash值,以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了,这时就添加到同一hash值的元素的后面,他们在数组的同一位置,但是形成了链表,同一各链表上的Hash值是相同的,所以说数组存放的是链表.而当链表长度太长时,链表就转换为红黑树,这样大大提高了查找的效率. 当链表数组的容量超过初始容量的0.75时,再散列将链表数组扩
-
Springboot工程中使用filter过程解析
一.什么是filter 过滤器实际上就是用来对web资源进行拦截,做一些处理后再交给下一个过滤器或servlet处理 通常都是用来拦截request进行处理的,也可以对返回的response进行拦截处理 . filter可以在请求到达servlet前或者请求完成响应后进行后续的处理. 二.在springboot工程中使用filter 创建一个filter,并使用注解配置该filter的名称和拦截路径等属性 @WebFilter(filterName = "AFilter",urlPat
-
如何在vue中使用jointjs过程解析
在vue中引入joint.js的问题,之前在网上搜了很多,都没有给出一个确切的答案,捣鼓了两天终于弄明白了,做个记录. 首先,我参考了一篇来自stackoverflow的文章 看完这篇文章,大家应该至少大致怎么做了,下面我们来具体看一下: 首先在vue项目中运行npm install jointjs --save 然后在入口文件,我的是main.js,也有可能是app.js中加入下面两行,把joint.js和jquery作为全局变量 window.$ = require('jquery'); w
-
Pymysql实现往表中插入数据过程解析
代码如下 # -*- coding = utf-8 -*- # @time:2020/5/28/028 21:00 # Author:cyx # @File:插入数据.py # @Software:PyCharm import pymysql con = pymysql.connect(host='localhost',user='root',password='123456',database='python_db',port=3366) # 创建游标对象 cur = con.cursor()
-
如何在postman测试用例中实现断言过程解析
首先我们在postman中打开一个用例. Respomse body:Contains string断言方法 (Respomse body:Contains string为包含断言,只要在结果中包含我们填写的字符,执行就是通过的) 1.选择Tests,在图片右下加选择Respomse body:Contains string的断言方法, 在Tests框中会自动显示内容,然后我们只要去填写就好了. 2,在include('' '')中填写包含的内容,只要在结果中出现此内容,结果就是通过的(通过为p
-
浅谈JDK7和JDK8的区别在哪
一.接口中的default方法 一般来说接口中的方法都是不实现的,基本通过实现类来实现方法.但是jdk8中提供了一种被default修饰的方法,可以直接在接口中进行实现. 二.lambda表达式 jdk8引入了lambda表达式,也可称为closure(闭包),通常是在需要一个函数,但又不想费神去命名一个函数的场合下使用,也就是指匿名函数. lambda允许把函数作为一个方法的参数(函数作为参数传递进方法中). 由于其几乎被所有主流开发语言支持.是java8新引入的一种语法,是一种紧凑的传递代码
-
深入理解JDK8中Stream使用
概述 Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找.过滤和映射数据等操作.使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询.也可以使用 Stream API 来并行执行操作.简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式. 特点: 不是数据结构,不会保存数据. 不会修改原来的数据源,它会将操作后的数据保存到另外一个对象中.(保留意见:毕竟peek方法可以修改流中元素)
-
JDK8中Optional类巧用之判空操作
前言 相信大家肯定所有的开发者都对Java8里面的所有的东西都感兴趣,虽然目前的 JDK 已经更新到 JDK17 了,但是我相信,现在很多公司使用的还都是 JDK8 甚至是 JDK7,但是,就算是有些公司已经升级到 JDK8 但是对于 JDK8 里面的一些东西的使用,却没有使用的淋漓尽致. 今天就给大家放出几个 JDK8 里面比较好用的. JDK8 大家都是知道 JDK8 就开始使用 Lambda 表达式,但是很多不管是在教程上还是在其他的书籍上,都没有说在实际开发的时候去使用上这个 Lambd