Python实现堆排序案例详解
Python实现堆排序
一、堆排序简介
堆排序(Heap Sort)是利用堆这种数据结构所设计的一种排序算法。
堆的结构是一棵完全二叉树的结构,并且满足堆积的性质:每个节点(叶节点除外)的值都大于等于(或都小于等于)它的子节点。
关于二叉树和完全二叉树的介绍可以参考:https://blog.csdn.net/weixin_43790276/article/details/104737870
堆排序先按从上到下、从左到右的顺序将待排序列表中的元素构造成一棵完全二叉树,然后对完全二叉树进行调整,使其满足堆积的性质:每个节点(叶节点除外)的值都大于等于(或都小于等于)它的子节点。构建出堆后,将堆顶与堆尾进行交换,然后将堆尾从堆中取出来,取出来的数据就是最大(或最小)的数据。重复构建堆并将堆顶和堆尾进行交换,取出堆尾的数据,直到堆中的数据全部被取出,列表排序完成。
堆结构分为大顶堆和小顶堆:
1. 大顶堆:每个节点(叶节点除外)的值都大于等于其子节点的值,根节点的值是所有节点中最大的,所以叫大顶堆,在堆排序算法中用于升序排列。
2. 小顶堆:每个节点(叶节点除外)的值都小于等于其子节点的值,根节点的值是所有节点中最小的,所以叫小顶堆,在堆排序算法中用于降序排列。
二、堆排序原理
堆排序的原理如下:
1. 将待排序列表中的数据按从上到下、从左到右的顺序构造成一棵完全二叉树。
2. 将完全二叉树中每个节点(叶节点除外)的值与其子节点(子节点有一个或两个)中较大的值进行比较,如果节点的值小于子节点的值,则交换他们的位置(大顶堆,小顶堆反之)。
3. 将节点与子节点进行交换后,要继续比较子节点与孙节点的值,直到不需要交换或子节点是叶节点时停止。比较完所有的非叶节点后,即可构建出堆结构。
4. 将数据构造成堆结构后,将堆顶与堆尾交换,然后将堆尾从堆中取出来,添加到已排序序列中,完成一轮堆排序,堆中的数据个数减1。
5. 重复步骤2,3,4,直到堆中的数据全部被取出,列表排序完成。
以列表 [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21] 进行升序排列为例。列表的初始状态如下图。
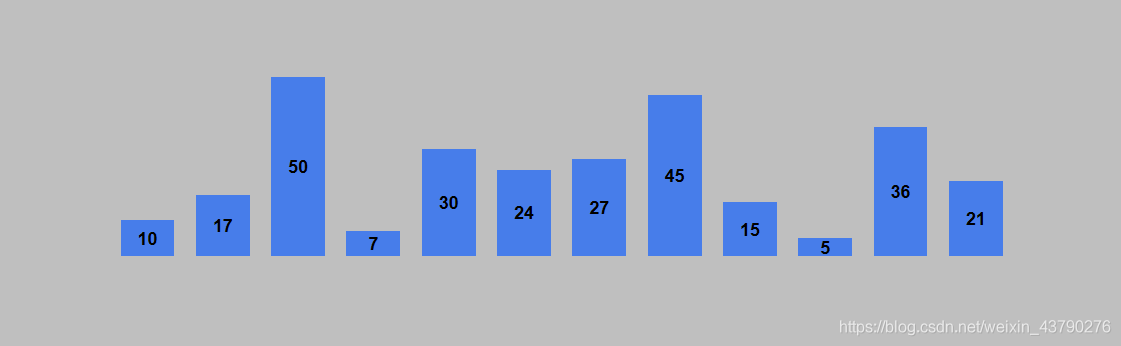
要进行升序排序,则构造堆结构时,使用大顶堆。
1. 将待排序列表中的数据按从上到下、从左到右的顺序构造成一棵完全二叉树。
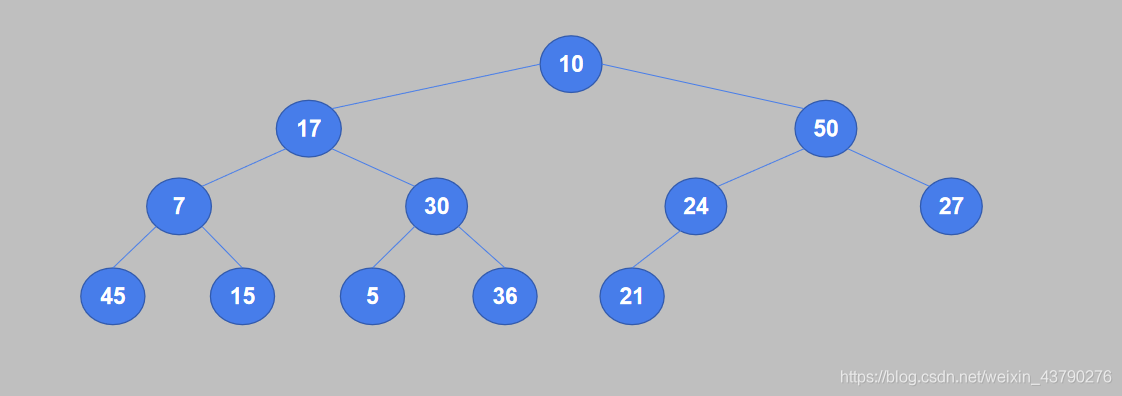
2. 从完全二叉树的最后一个非叶节点开始,将它的值与其子节点中较大的值进行比较,如果值小于子节点则交换。24是最后一个非叶子节点,它只有一个子节点21,24大于21,不需要交换。
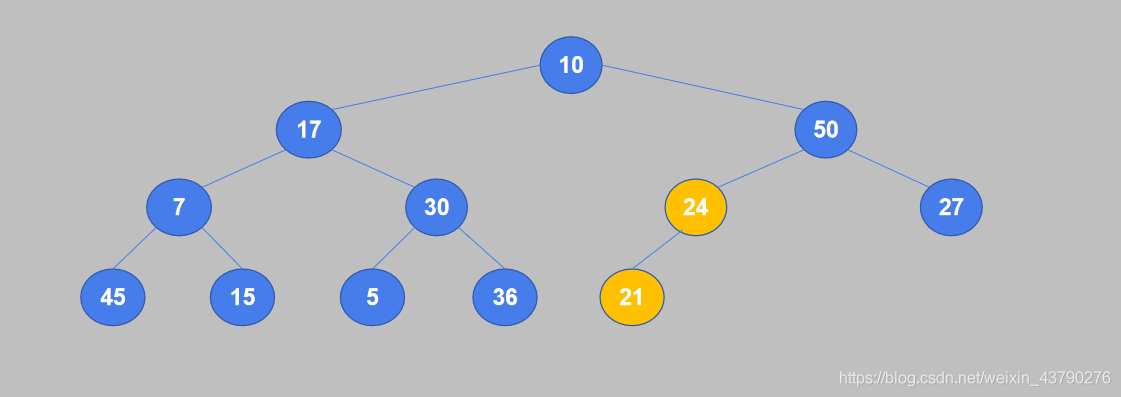
3. 继续将倒数第二个非叶节点的值与其子节点中较大的值进行比较,如果值小于子节点则交换。节点30有两个子节点5和36,较大的是36,30小于36,交换位置。
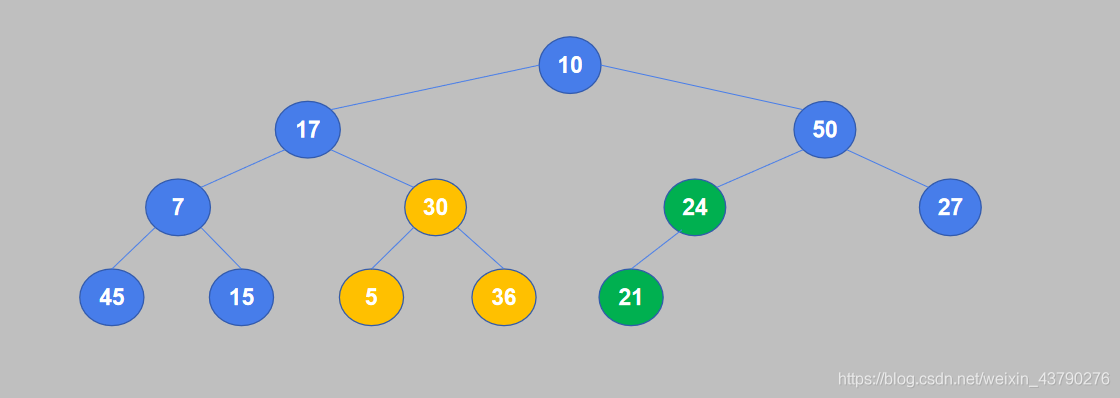
4. 重复对下一个节点进行比较。7小于45,交换位置。
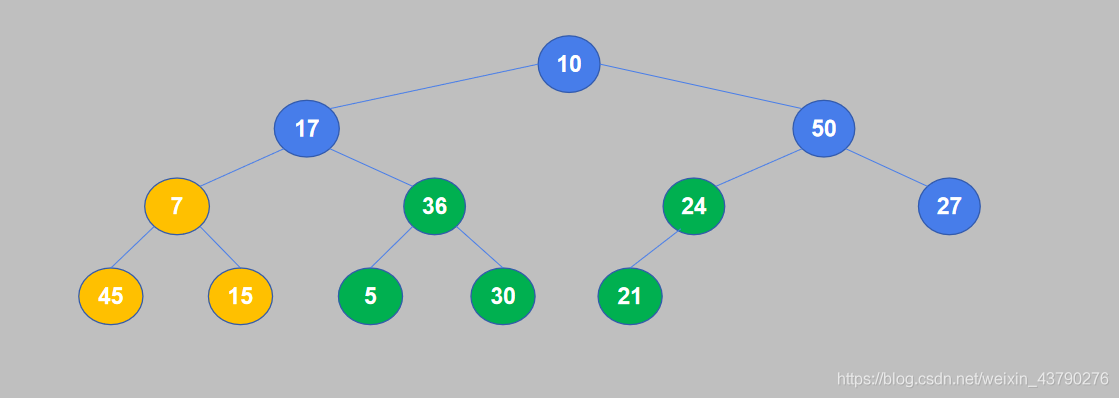
5. 继续重复,50大于27,不需要交换位置。如果不需要进行交换,则不用再比较子节点与孙节点。
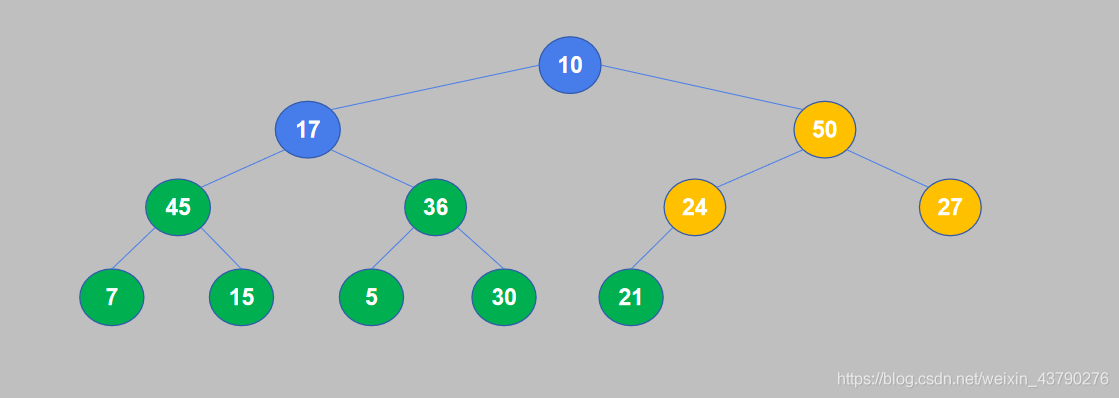
6. 继续重复,17小于45,交换位置。
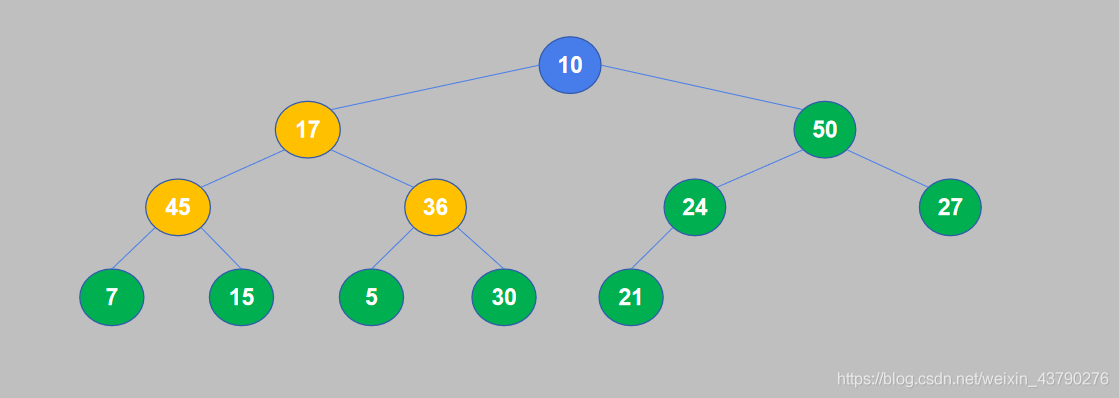
7. 17和45交换位置之后,17交换到了子节点的位置,还需要继续将其与孙节点进行比较。17大于15,不需要交换。
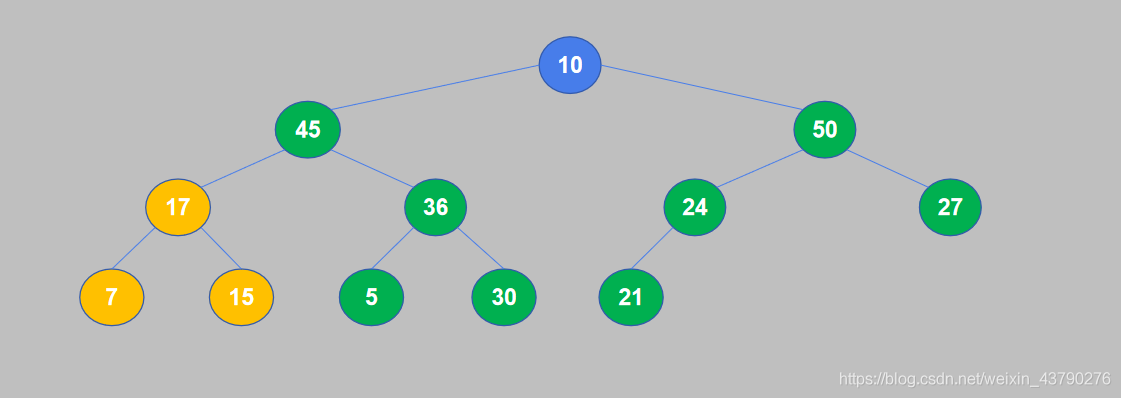
8. 继续对下一个节点进行比较,10小于50,交换位置。
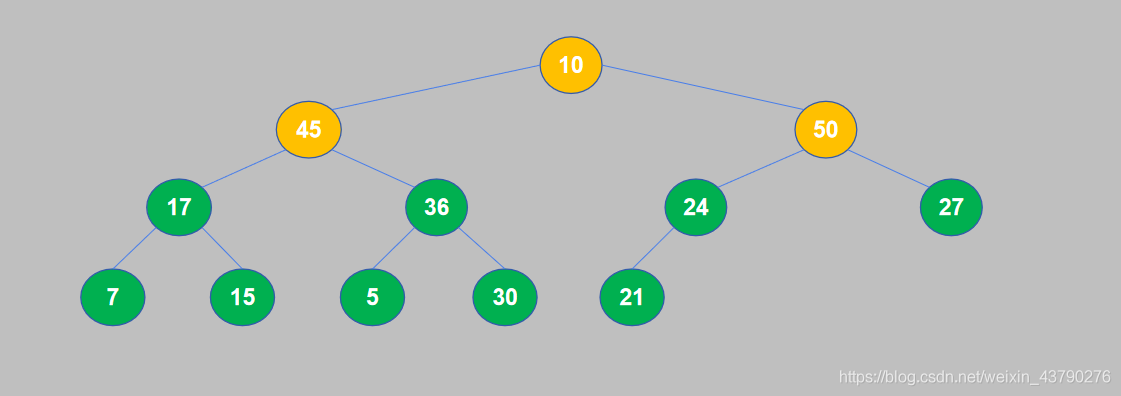
9. 10和50交换位置之后,10交换到了子节点的位置,还需要继续将其与孙节点进行比较。10小于于27,交换位置。
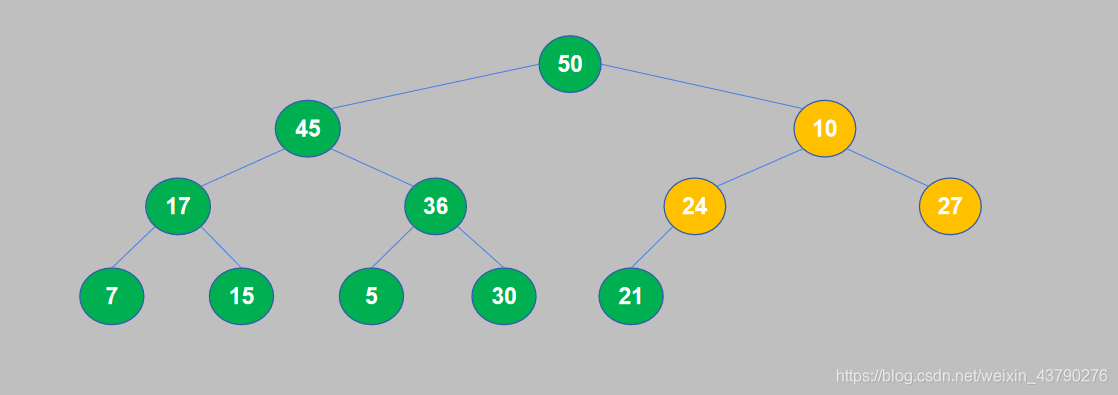
10. 此时,一个大顶堆构造完成,满足了堆积的性质:每个节点(叶节点除外)的值都大于等于它的子节点。
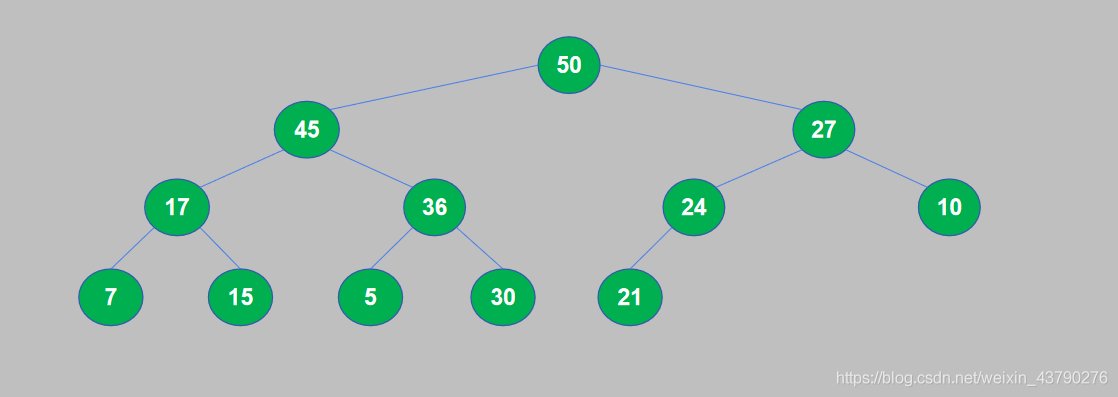
11. 大顶堆构建完成后,将堆顶与堆尾交换位置,然后将堆尾从堆中取出。将50和21交换位置,交换后21到了堆顶,50(最大的数据)到了堆尾,然后将50从堆中取出。
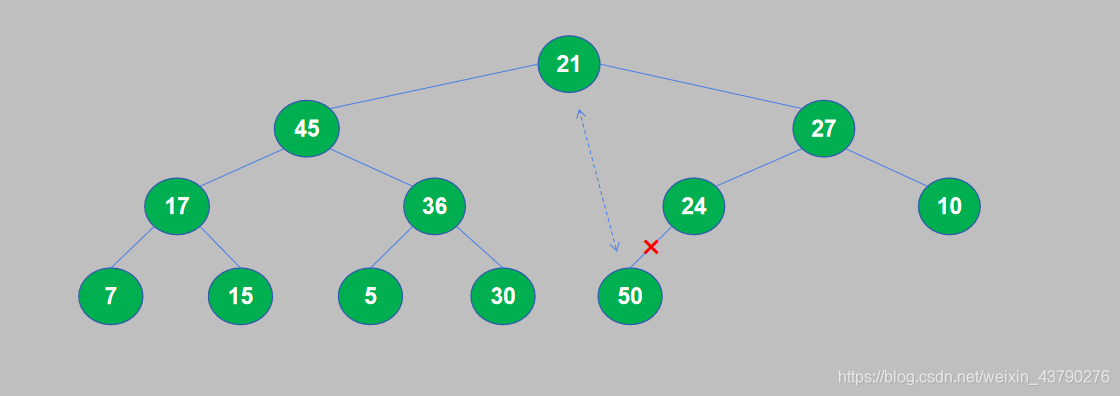
12. 将50从堆中取出后,找到了待排序列表中的最大值,50添加到已排序序列中,第一轮堆排序完成,堆中的元素个数减1。
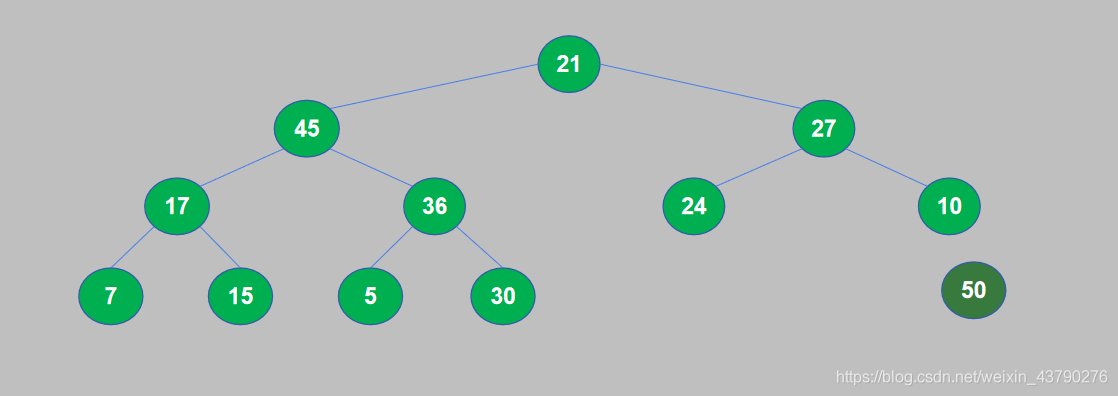
13. 取出最大数据后,重复将完全二叉树构建成大顶堆,交换堆顶和堆尾,取出堆尾。这样每次都是取出当前堆中最大的数据,添加到已排序序列中,直到堆中的数据全部被取出。

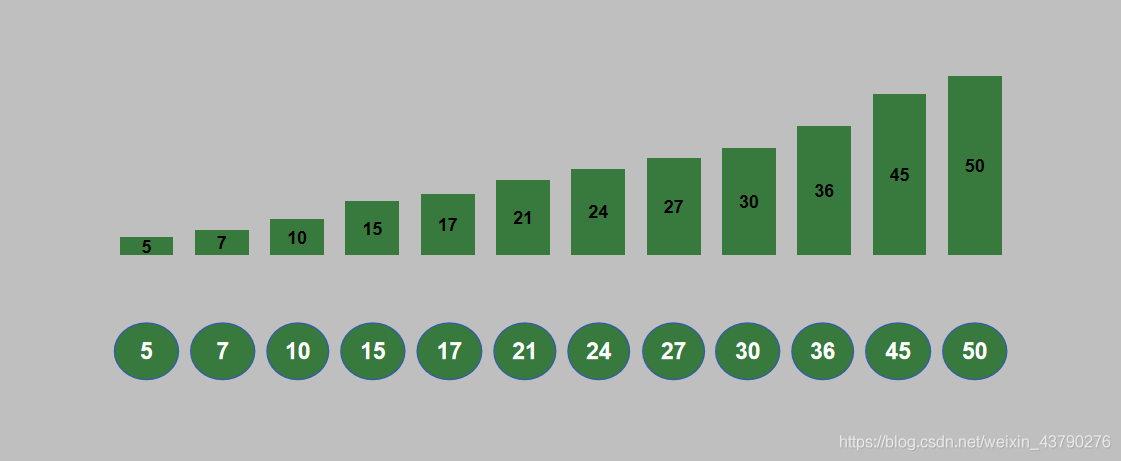
14. 循环进行 n 轮堆排序之后,列表排序完成。排序结果如下图。
三、Python实现堆排序
# coding=utf-8
def heap_sort(array):
first = len(array) // 2 - 1
for start in range(first, -1, -1):
# 从下到上,从右到左对每个非叶节点进行调整,循环构建成大顶堆
big_heap(array, start, len(array) - 1)
for end in range(len(array) - 1, 0, -1):
# 交换堆顶和堆尾的数据
array[0], array[end] = array[end], array[0]
# 重新调整完全二叉树,构造成大顶堆
big_heap(array, 0, end - 1)
return array
def big_heap(array, start, end):
root = start
# 左孩子的索引
child = root * 2 + 1
while child <= end:
# 节点有右子节点,并且右子节点的值大于左子节点,则将child变为右子节点的索引
if child + 1 <= end and array[child] < array[child + 1]:
child += 1
if array[root] < array[child]:
# 交换节点与子节点中较大者的值
array[root], array[child] = array[child], array[root]
# 交换值后,如果存在孙节点,则将root设置为子节点,继续与孙节点进行比较
root = child
child = root * 2 + 1
else:
break
if __name__ == '__main__':
array = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]
print(heap_sort(array))
运行结果:
[5, 7, 10, 15, 17, 21, 24, 27, 30, 36, 45, 50]
代码中,先实现一个big_heap(array, start, end)函数,用于比较节点与其子节点中的较大者,如果值小于子节点的值则进行交换。代码中不需要真正将数据都添加到完全二叉树中,而是根据待排序列表中的数据索引来得到节点与子节点的位置关系。完全二叉树中,节点的索引为i,则它的左子节点的索引为2*i+1,右子节点的索引为2*i+2,有n个节点的完全二叉树中,非叶子节点有n//2个,列表的索引从0开始,所以索引为0~n//2-1的数据为非叶子节点。
实现堆排序函数heap_sort(array)时,先调用big_heap(array, start, end)函数循环对非叶子节点进行调整,构造大顶堆,然后将堆顶和堆尾交换,将堆尾从堆中取出,添加到已排序序列中,完成一轮堆排序。然后循环构建大顶堆,每次将最大的元素取出,直到堆中的数据全部被取出。
四、堆排序的时间复杂度和稳定性
1. 时间复杂度
在堆排序中,构建一次大顶堆可以取出一个元素,完成一轮堆排序,一共需要进行n轮堆排序。每次构建大顶堆时,需要进行的比较和交换次数平均为logn(第一轮构建堆时步骤多,后面重建堆时步骤会少很多)。时间复杂度为 T(n)=nlogn ,再乘每次操作的步骤数(常数,不影响大O记法),所以堆排序的时间复杂度为 O(nlogn) 。
2. 稳定性
在堆排序中,会交换节点与子节点,如果有相等的数据,可能会改变相等数据的相对次序。所以堆排序是一种不稳定的排序算法。
到此这篇关于Python实现堆排序案例详解的文章就介绍到这了,更多相关Python实现堆排序内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python实现堆排序的实例讲解
堆排序 堆是一种完全二叉树(是除了最后一层,其它每一层都被完全填充,保持所有节点都向左对齐),首先需要知道概念:最大堆问题,最大堆就是根节点比子节点值都大,并且所有根节点都满足,那么称它为最大堆.反之最小堆. 当已有最大堆,如下图,首先将7提出,然后将堆中最后一个元素放到顶点上,此时这个堆不满足最大堆了,那么我们要给它构建成最大堆,需要找到此时堆中对打元素然后交换,此时最大值为6,符合最大堆后,我们将6提取出来,然后将堆中最后一个元素放到堆的顶部...以此类推.最后提取的数值7,6,5,4,3,
-
Python排序搜索基本算法之堆排序实例详解
本文实例讲述了Python排序搜索基本算法之堆排序.分享给大家供大家参考,具体如下: 堆是一种完全二叉树,堆排序是一种树形选择排序,利用了大顶堆堆顶元素最大的特点,不断取出最大元素,并调整使剩下的元素还是大顶堆,依次取出最大元素就是排好序的列表.举例如下,把序列[26,5,77,1,61,11,59,15,48,19]排序,如下: 基于堆的优先队列算法代码如下: def fixUp(a): #在堆尾加入新元素,fixUp恢复堆的条件 k=len(a)-1 while k>1 and a[k//2
-
Python堆排序原理与实现方法详解
本文实例讲述了Python堆排序原理与实现方法.分享给大家供大家参考,具体如下: 在这里要事先说明一下我也是新手,很多东西我了解不是很深入,写算法完全是锻炼自己逻辑能力同时顺带帮助读研的朋友么解决一些实际问题.所以很多时候考虑的东西不是很全面能请各位看到博文的大牛们指正.对于排序算法说实在的我觉得已经写烂了,但是为什么还是要过一遍呢?还是为了能够打牢基础.说一下自己的看法,对于已经的玩烂的算法因该怎么学.首先最重要的还是了解算法的基本模型和算法思想,我觉得这是非常重要的.其次的话首先先尝试自己实
-
Python实现基于二叉树存储结构的堆排序算法示例
本文实例讲述了Python实现基于二叉树存储结构的堆排序算法.分享给大家供大家参考,具体如下: 既然用Python实现了二叉树,当然要写点东西练练手. 网络上堆排序的教程很多,但是却几乎都是以数组存储的数,直接以下标访问元素,当然这样是完全没有问题的,实现简单,访问速度快,也容易理解. 但是以练手的角度来看,我还是写了一个二叉树存储结构的堆排序 其中最难的问题就是交换二叉树中两个节点. 因为一个节点最多与三个节点相连,那么两个节点互换,就需要考虑到5个节点之间的关系,也需要判断是左右孩子,这将是
-
Python实现的堆排序算法示例
本文实例讲述了Python实现的堆排序算法.分享给大家供大家参考,具体如下: 堆排序的思想: 堆是一种数据结构,可以将堆看作一棵完全二叉树,这棵二叉树满足,任何一个非叶节点的值都不大于(或不小于)其左右孩子节点的值. 将一个无序序列调整为一个堆,就可以找出这个序列的最大值(或最小值),然后将找出的这个值交换到序列的最后一个,这样有序序列就元素就增加一个,无序序列元素就减少一个,对新的无序序列重复这样的操作,就实现了排序. 堆排序的执行过程: 1.从无序序列所确定的完全二叉树的第一个非叶子节点开始
-
Python实现堆排序案例详解
Python实现堆排序 一.堆排序简介 堆排序(Heap Sort)是利用堆这种数据结构所设计的一种排序算法. 堆的结构是一棵完全二叉树的结构,并且满足堆积的性质:每个节点(叶节点除外)的值都大于等于(或都小于等于)它的子节点. 关于二叉树和完全二叉树的介绍可以参考:https://blog.csdn.net/weixin_43790276/article/details/104737870 堆排序先按从上到下.从左到右的顺序将待排序列表中的元素构造成一棵完全二叉树,然后对完全二叉树进行调整,使
-
Python heapq库案例详解
Python heapq heapq 库是 Python 标准库之一,提供了构建小顶堆的方法和一些对小顶堆的基本操作方法(如入堆,出堆等),可以用于实现堆排序算法. 堆是一种基本的数据结构,堆的结构是一棵完全二叉树,并且满足堆积的性质:每个节点(叶节点除外)的值都大于等于(或都小于等于)它的子节点. 堆结构分为大顶堆和小顶堆,在 heapq 中使用的是小顶堆: 大顶堆:每个节点(叶节点除外)的值都大于等于其子节点的值,根节点的值是所有节点中最大的. 小顶堆:每个节点(叶节点除外)的值都小于等于其
-
Python ord函数()案例详解
python中ord函数 Python ord()函数 (Python ord() function) ord() function is a library function in Python, it is used to get number value from given character value, it accepts a character and returns an integer i.e. it is used to convert a character to an
-
Python rindex()方法案例详解
描述 Python rindex() 方法返回子字符串最后一次出现在字符串中的索引位置,该方法与 rfind() 方法一样,只不过如果子字符串不在字符串中会报一个异常. 语法 rindex() 方法语法: S.rindex(sub[,start=0[,end=len(S)]]) 参数 sub -- 指定检索的子字符串 S -- 父字符串 start -- 可选参数,开始查找的位置,默认为0.(可单独指定) end -- 可选参数,结束查找位置,默认为字符串的长度.(不能单独指定) 返回值 返回子
-
我用Python抓取了7000 多本电子书案例详解
安装 安装很简单,只要执行: pip install requests-html 就可以了. 分析页面结构 通过浏览器审查元素可以发现这个电子书网站是用 WordPress 搭建的,首页列表元素很简单,很规整 所以我们可以查找 .entry-title > a 获取所有图书详情页的链接,接着我们进入详情页,来寻找下载链接,由下图 可以发现 .download-links > a 里的链接就是该书的下载链接,回到列表页可以发现该站一共 700 多页,由此我们便可以循环列表获取所有的下载链接. R
-
python爬虫破解字体加密案例详解
本次案例以爬取起小点小说为例 案例目的: 通过爬取起小点小说月票榜的名称和月票数,介绍如何破解字体加密的反爬,将加密的数据转化成明文数据. 程序功能: 输入要爬取的页数,得到每一页对应的小说名称和月票数. 案例分析: 找到目标的url: (右键检查)找到小说名称所在的位置: 通过名称所在的节点位置,找到小说名称的xpath语法: (右键检查)找到月票数所在的位置: 由上图发现,检查月票数据的文本,得到一串加密数据. 我们通过xpathhelper进行调试发现,无法找到加密数据的语法.因此,需要通
-
python爬虫线程池案例详解(梨视频短视频爬取)
python爬虫-梨视频短视频爬取(线程池) 示例代码 import requests from lxml import etree import random from multiprocessing.dummy import Pool # 多进程要传的方法,多进程pool.map()传的第二个参数是一个迭代器对象 # 而传的get_video方法也要有一个迭代器参数 def get_video(dic): headers = { 'User-Agent':'Mozilla/5.0 (Wind
-
python爬虫系列网络请求案例详解
学习了之前的基础和爬虫基础之后,我们要开始学习网络请求了. 先来看看urllib urllib的介绍 urllib是Python自带的标准库中用于网络请求的库,无需安装,直接引用即可. 主要用来做爬虫开发,API数据获取和测试中使用. urllib库的四大模块: urllib.request: 用于打开和读取url urllib.error : 包含提出的例外,urllib.request urllib.parse:用于解析url urllib.robotparser:用于解析robots.tx
-
Python中return用法案例详解
python中return的用法 1.return语句就是把执行结果返回到调用的地方,并把程序的控制权一起返回 程序运行到所遇到的第一个return即返回(退出def块),不会再运行第二个return. 例如: def haha(x,y): if x==y: return x,y print(haha(1,1)) 已改正: 结果:这种return传参会返回元组(1, 1) 2.但是也并不意味着一个函数体中只能有一个return 语句,例如: def test_return(x): if x >
-
Python实现OCR识别之pytesseract案例详解
Python实现OCR识别:pytesseract Python常用pytesseract进行图片上的文字识别,即OCR识别,完整的代码比较简单,只要下面一行即可,但是实际使用时环境配置上容易出错. from PIL import Image import pytesseract text = pytesseract.image_to_string(Image.open('/Users/alice/Documents/Develop/PythonCode/textinphoto.PNG')) p