亲自教你实现栈及C#中Stack源码分析
定义
栈又名堆栈,是一种操作受限的线性表,仅能在表尾进行插入和删除操作。
它的特点是先进后出,就好比我们往桶里面放盘子,放的时候都是从下往上一个一个放(入栈),取的时候只能从上往下一个一个取(出栈),这个比喻并非十分恰当,比如拿盘子的时候只是习惯从上面开始拿,也可以从中间拿,而栈的话是只能操作最上面的元素,这样比喻只是为了便于了解。

刚开始接触栈可能会有些疑问,我们已经有数组和链表了,为什么还要栈这个操作受限制的数据结构呢?数组和链表虽然灵活,但是操作起来也更容易出错,而栈因为操作受限,在特定场景中使用还是有优势的。
当某个数据集合只涉及在一端插入和删除数据,并且满足先进后出的特性时,我们就应该首选“栈”这种数据结构。
栈的实现
栈的实现方式有两种,一种是基于数组实现的顺序栈,另一种是基于链表实现的链式栈。它的主要操作也就两个,即入栈和出栈,难度并不大😏。
先了解一下入栈(Push)和出栈(Pop),如下图
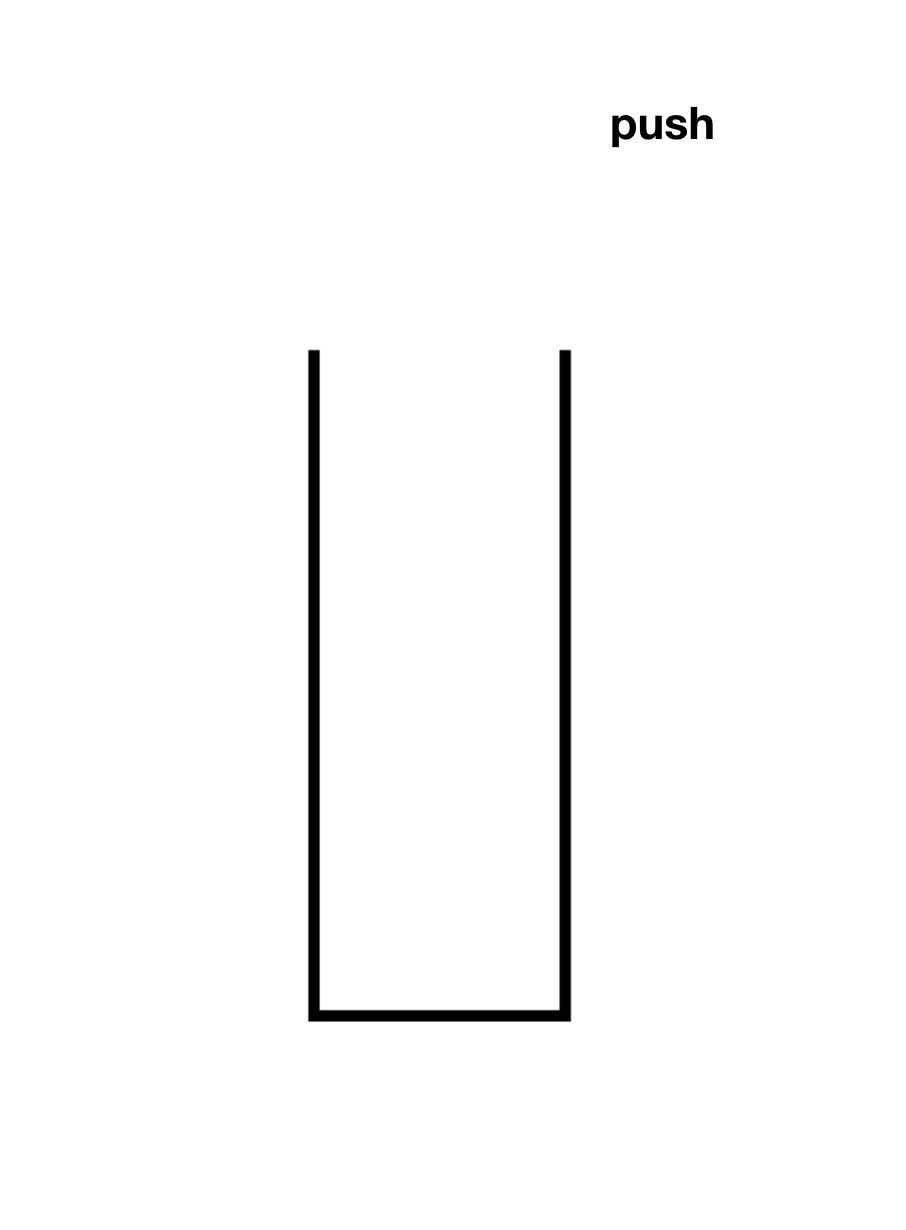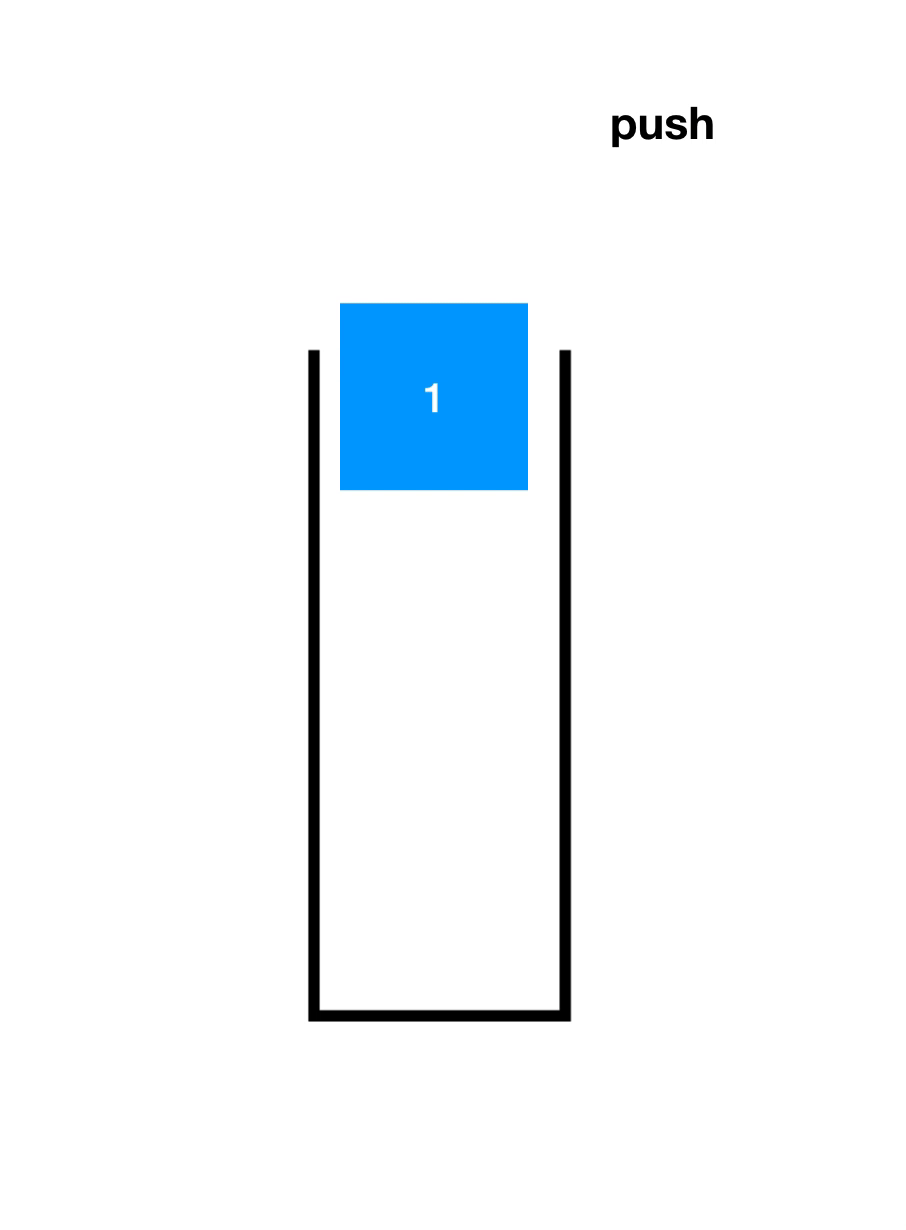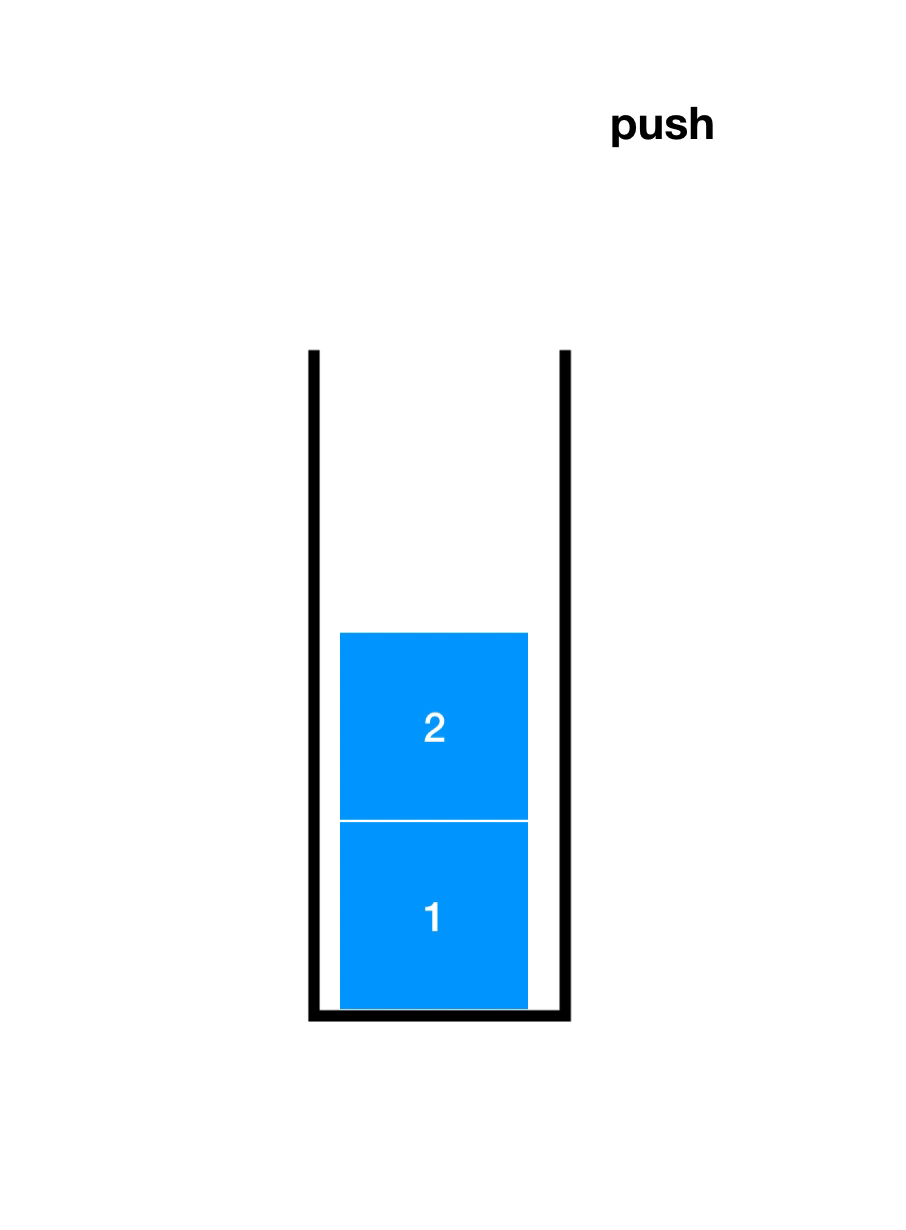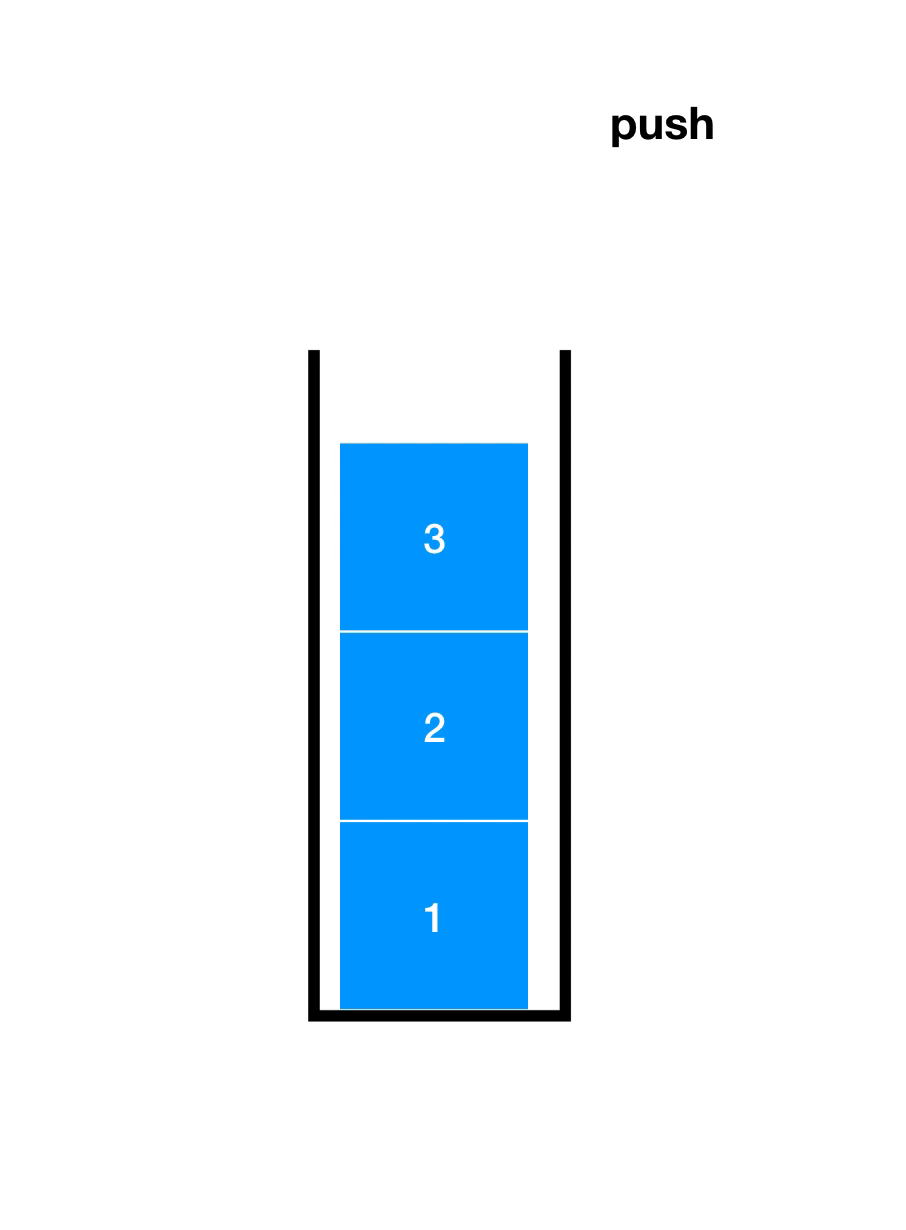

顺序栈
基于数组实现,就面临着数组大小固定、扩容成本大的问题,下面是使用C#实现出栈和入栈简单功能代码。
// 基于数组实现的顺序栈
public class ArrayStack
{
private string[] items; // 数组
private int count; // 栈中元素个数
private int n; //栈的大小
// 初始化数组,申请一个大小为n的数组空间
public ArrayStack(int n)
{
this.items = new string[n];
this.n = n;
this.count = 0;
}
// 入栈操作
public bool Push(string item)
{
// 数组空间不够了,直接返回false,入栈失败。
if (count == n) return false;
// 将item放到下标为count的位置,并且count加一
items[count] = item;
++count;
return true;
}
// 出栈操作
public string Pop()
{
// 栈为空,则直接返回null
if (count == 0) return null;
// 返回下标为count-1的数组元素,并且栈中元素个数count减一
string tmp = items[count - 1];
--count;
return tmp;
}
}
上面代码有一些很明显的缺点,比如存储的数据类型固定为string(C#中使用泛型可以很好的解决),大小固定...这只是简单的功能演示,后面分析C#中Stack源码时这些问题都会被化解。
出栈和入栈的时间复杂度是多少呢?这个很好计算,因为出栈和入栈都只涉及栈顶的元素,所以是O(1)。
空间复杂度呢?还是O(1),因为这里只额外使用了count和n两个临时变量。
💁♂ 空间复杂度是指除了原本的数据存储空间外,算法运行还需要额外的存储空间。例子中大小为n的数组是无法省略的,也就是说这n个空间是必须的,对复杂度不了解的可以点击查看一文搞定算法复杂度分析。
链式栈
话不多说,上代码
// 链表实现栈
public class LinkStack<T>
{
//栈顶指示器
public Node<T> Top { get; set; }
//栈中结点的个数
public int NCount { get; set; }
//初始化
public LinkStack()
{
Top = null;
NCount = 0;
}
//获取栈的长度
public int GetLength()
{
return NCount;
}
//判断栈是否为空
public bool IsEmpty()
{
if ((Top == null) && (0 == NCount))
{
return true;
}
return false;
}
//入栈
public void Push(T item)
{
Node<T> p = new Node<T>(item);
if (Top == null)
{
Top = p;
}
else
{
p.Next = Top;
Top = p;
}
NCount++;
}
//出栈
public T Pop()
{
if (IsEmpty())
{
return default(T);
}
Node<T> p = Top;
Top = Top.Next;
--NCount;
return p.Data;
}
}
//结点定义
public class Node<T>
{
public T Data;
public Node<T> Next;
public Node(T item)
{
Data = item;
}
}
时间复杂度和空间复杂度均为O(1).
C#中Stack源码分析
前面我们已经知道了顺序栈和链式栈的优缺点,那么C#语言中自带的Stack是基于什么实现的呢?
答案是顺序栈。Stack是一个泛型类,里面定义了一个泛型数组用以存储数据
private T[] _array;
既然是一个顺序栈,为什么在使用的过程中什么不需要初始化数组大小,也不用担心扩容问题呢?
当我们实例化Stack的时候,会调用它的构造函数,初始化数组大小为0.
public Stack()
{
_array = _emptyArray;
_size = 0;
_version = 0;
}
向数组中添加元素时,会检测数组是否还有空闲容量,如果超出数组大小,将进行扩容
public void Push(T item)
{
if (_size == _array.Length)
{
T[] array = new T[(_array.Length == 0) ? 4 : (2 * _array.Length)];
Array.Copy(_array, 0, array, 0, _size);
_array = array;
}
_array[_size++] = item;
_version++;
}
正是因为C#帮我们封装好了,所以我们使用起来才感觉如此的方便。
Push()函数的时间复杂度是多少呢?当栈中有空闲空间时,可以直接添加,它的时间复杂度是O(1)。但当内存不够需要扩容时,需要重新申请内存,进行数据搬移,所以时间复杂度就变成了O(n),其平均时间复杂度也为O(1).
总结

到此这篇关于手把手教你实现栈及C#中Stack源码分析的文章就介绍到这了,更多相关C#中Stack源码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

浅谈C#中堆和栈的区别(附上图解)
线程堆栈:简称栈 Stack 托管堆: 简称堆 Heap 使用.Net框架开发程序的时候,我们无需关心内存分配问题,因为有GC这个大管家给我们料理一切.如果我们写出如下两段代码: 代码段1: public int AddFive(int pValue) { int result; result = pValue + 5; return result; } 代码段2: public class MyInt { public int MyValue; } public MyInt AddFive(i
-
C# 通过ServiceStack 操作Redis
作 者 : 明志德道 1.引用Nuget包 ServiceStack.Redis 我这里就用别人已经封装好的Reids操作类来和大家一起参考了下,看看怎么使用ServiceStack.Redis 操作Redis数据 RedisConfigInfo--redis配置文件信息 /// <summary> /// redis配置文件信息 /// 也可以放到配置文件去 /// </summary> public sealed class RedisConfigInfo { //
-
C#探秘系列(三)——StackTrace,Trim
一: Environment.StackTrace 可能我们看到最多的就是catch中的e参数,里面会有一个StackTrace,然后不可否认的这玩意太有用了,它会把调用堆栈中的信息输出出来,有了它,我们就可以快速的知道运行代码的执行流并且快速的定位到问题. 有时候我们会遇到这样两个问题: ①:线上的bug在本地不能重现. ②:由于太多的多态,设计模式,程序员反而对线上的代码执行流向会搞的稀里糊涂的. 为了搞清楚并解决这两个问题,我们看生产日志的时候很在乎代码的执行流以及想获取当前上下文的可疑变
-
在c#中使用servicestackredis操作redis的实例代码
声明一个客户端对象: 复制代码 代码如下: protected RedisClient Redis = new RedisClient("127.0.0.1", 6379);//redis服务IP和端口 一 .基本KEY/VALUE键值对操作: 1. 添加/获取: List<string> storeMembers = new List<string>(); storeMembers.ForEach(x => Redis.AddItemToList(&q
-
C#使用Object类实现栈的方法详解
本文实例讲述了C#使用Object类实现栈的方法.分享给大家供大家参考,具体如下: Stack类的代码: using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace 使用Object类实现后进先出队列 { class Stack { private Object[] _items; public Object[] Items { get { return this.
-
C#创建安全的栈(Stack)存储结构
在C#中,用于存储的结构较多,如:DataTable,DataSet,List,Dictionary,Stack等结构,各种结构采用的存储的方式存在差异,效率也必然各有优缺点.现在介绍一种后进先出的数据结构. 谈到存储结构,我们在项目中使用的较多.对于Task存储结构,栈与队列是类似的结构,在使用的时候采用不同的方法.C#中栈(Stack)是编译期间就分配好的内存空间,因此你的代码中必须就栈的大小有明确的定义:堆是程序运行期间动态分配的内存空间,你可以根据程序的运行情况确定要分配的堆内存的大小.
-
C#使用foreach语句遍历堆栈(Stack)的方法
本文实例讲述了C#使用foreach语句遍历堆栈(Stack)的方法.分享给大家供大家参考.具体如下: using System; using System.Collections; public class StacksW3 { static void Main(string[] args) { Stack a = new Stack(10); int x = 0; a.Push(x); x++; a.Push(x); foreach (int y in a) { Console.WriteL
-
C#数据结构之堆栈(Stack)实例详解
本文实例讲述了C#数据结构之堆栈(Stack).分享给大家供大家参考,具体如下: 堆栈(Stack)最明显的特征就是"先进后出",本质上讲堆栈也是一种线性结构,符合线性结构的基本特点:即每个节点有且只有一个前驱节点和一个后续节点. 相对前面学习过的顺序表.链表不同的地方在于:Stack把所有操作限制在"只能在线性结构的某一端"进行,而不能在中间插入或删除元素.下面是示意图: 从示意图中可以看出,堆栈有二种实现方式:基于数组的顺序堆栈实现.类似链表的链式堆栈实现 先抽
-
亲自教你实现栈及C#中Stack源码分析
定义 栈又名堆栈,是一种操作受限的线性表,仅能在表尾进行插入和删除操作. 它的特点是先进后出,就好比我们往桶里面放盘子,放的时候都是从下往上一个一个放(入栈),取的时候只能从上往下一个一个取(出栈),这个比喻并非十分恰当,比如拿盘子的时候只是习惯从上面开始拿,也可以从中间拿,而栈的话是只能操作最上面的元素,这样比喻只是为了便于了解. 刚开始接触栈可能会有些疑问,我们已经有数组和链表了,为什么还要栈这个操作受限制的数据结构呢?数组和链表虽然灵活,但是操作起来也更容易出错,而栈因为操作受限,在特定场
-
Java编程中ArrayList源码分析
之前看过一句话,说的特别好.有人问阅读源码有什么用?学习别人实现某个功能的设计思路,提高自己的编程水平. 是的,大家都实现一个功能,不同的人有不同的设计思路,有的人用一万行代码,有的人用五千行.有的人代码运行需要的几十秒,有的人只需要的几秒..下面进入正题了. 本文的主要内容: · 详细注释了ArrayList的实现,基于JDK 1.8 . ·迭代器SubList部分未详细解释,会放到其他源码解读里面.此处重点关注ArrayList本身实现. ·没有采用标准的注释,并适当调整了代码的缩进以方便介
-
Angular中$compile源码分析
$compile,在Angular中即"编译"服务,它涉及到Angular应用的"编译"和"链接"两个阶段,根据从DOM树遍历Angular的根节点(ng-app)和已构造完毕的 \$rootScope对象,依次解析根节点后代,根据多种条件查找指令,并完成每个指令相关的操作(如指令的作用域,控制器绑定以及transclude等),最终返回每个指令的链接函数,并将所有指令的链接函数合成为一个处理后的链接函数,返回给Angluar的bootstrap
-
Postgres中UPDATE更新语句源码分析
目录 PG中UPDATE源码分析 整体流程分析 解析部分——生成语法解析树UpdateStmt 解析部分——生成查询树Query 优化器——生成执行计划 执行器 事务 总结 PG中UPDATE源码分析 本文主要描述SQL中UPDATE语句的源码分析,代码为PG13.3版本. 整体流程分析 以update dtea set id = 1;这条最简单的Update语句进行源码分析(dtea不是分区表,不考虑并行等,没有建立任何索引),帮助我们理解update的大致流程. SQL流程如下: parse
-
Vue 中 template 有且只能一个 root的原因解析(源码分析)
引言 今年, 疫情 并没有影响到各种面经的正常出现,可谓是络绎不绝(学不动...).然后,在前段时间也看到一个这样的关于 Vue 的问题, 为什么每个组件 template 中有且只能一个 root? 可能,大家在平常开发中,用的较多就是 template 写 html 的形式.当然,不排除用 JSX 和 render() 函数的.但是,究其本质,它们最终都会转化成 render() 函数.然后,再由 render() 函数转为 Vritual DOM (以下统称 VNode ).而 rende
-
详解go中panic源码解读
panic源码解读 前言 本文是在go version go1.13.15 darwin/amd64上进行的 panic的作用 panic能够改变程序的控制流,调用panic后会立刻停止执行当前函数的剩余代码,并在当前Goroutine中递归执行调用方的defer: recover可以中止panic造成的程序崩溃.它是一个只能在defer中发挥作用的函数,在其他作用域中调用不会发挥作用: 举个栗子 package main import "fmt" func main() { fmt.
-
Python虚拟机栈帧对象及获取源码学习
目录 Python虚拟机 1. 栈帧对象 1.1 PyFrameObject 1.2 栈帧对象链 1.3 栈帧获取 2. 字节码执行 Python虚拟机 注:本篇是根据教程学习记录的笔记,部分内容与教程是相同的,因为转载需要填链接,但是没有,所以填的原创,如果侵权会直接删除.此外,本篇内容大部分都咨询了ChatGPT,为笔者解决了很多问题. 问题: 在Python 程序执行过程与字节码中,我们研究了Python程序的编译过程:通过Python解释器中的编译器对 Python 源码进行编译,最终获
-
在Java8与Java7中HashMap源码实现的对比
一.HashMap的原理介绍 此乃老生常谈,不作仔细解说. 一句话概括之:HashMap是一个散列表,它存储的内容是键值对(key-value)映射. 二.Java 7 中HashMap的源码分析 首先是HashMap的构造函数代码块1中,根据初始化的Capacity与loadFactor(加载因子)初始化HashMap. //代码块1 public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0)
-
java 中Buffer源码的分析
java 中Buffer源码的分析 Buffer Buffer的类图如下: 除了Boolean,其他基本数据类型都有对应的Buffer,但是只有ByteBuffer才能和Channel交互.只有ByteBuffer才能产生Direct的buffer,其他数据类型的Buffer只能产生Heap类型的Buffer.ByteBuffer可以产生其他数据类型的视图Buffer,如果ByteBuffer本身是Direct的,则产生的各视图Buffer也是Direct的. Direct和Heap类型Buff
-
Java 中模仿源码自定义ArrayList
Java 中模仿源码自定义ArrayList 最近看了下ArrayList的源码,抽空根据ArrayList的底层结构写了一个功能简单无泛型的自定义ArrayLsit,帮助自己更好理解ArrayList:,其实现的底层数据结构为数Object组,代码如下: /** * 自己实现一个ArrayList * */ public class MyArrayList { private Object[] elementData; private int size; public int size(){