Python 抓取数据存储到Redis中的操作
redis是一个key-value存储结构。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set 有序集合)和hash(哈希类型),数据存储如下图分析

为了分别为ID存入多个键值对,此次仅对Hash数据进行操作,例子如下
import os,sys
import requests
import bs4
import redis
#连接Redis
r = redis.Redis(host='127.0.0.1',password='123456',port=6379)
html = 'https://www.dongmanmanhua.cn/dailySchedule?weekday=MONDAY'
result = requests.get(html)
texts = result.text
data = bs4.BeautifulSoup(texts,'html.parser');
lidata = data.select('div#dailyList ul.daily_card li')
#print(lidata)
for x in lidata:
did = x.get('data-title-no')
name = x.select('p.subj')
name1 = name[0].get_text()
url = x.a.get('href')
story = x.a.p
story1 = story.string
user = x.select('p.author')
user1 = user[0].get_text()
like = x.select('em.grade_num')
like1 = like[0].get_text()
rt = {'did':did,'name':name1,'url':url,'story':story1,'user':user1,'like':like1}
#写数据到Redis
idkey = 'name'+did
#hash表数据写入命令hmget,可以一次写入多个键值对
r.hmget(idkey,rt)
#写入命令hset,一次只能写入一个键值对
r.hset(idkey,'did',did)
r.hset(idkey,'name',name1)
r.hset(idkey,'story',story1)
r.hset(idkey,'url',url)
r.hset(idkey,'user',user1)
r.hset(idkey,'like',like1)
print('dman哈希表写入成功')
print(r.hget(idkey,'did'))
print(r.hget(idkey,'name'))
Hash 类其他常用操作
hset(name,key,value) :name对应的hash中设置一个键值对,当name对应的hash中不存在当前key则创建(相当于添加) ,否则做更改操作
hget(name,key) : 在name对应的hash中获取根据key获取value
hmset(name,mapping) :在name对应的hash中批量设置键值对 ,mapping:例 {'k1':'v1','k2':'v2'}
hmget(name,keys,*args) :在name对应的hash中获取多个key的值 ,keys:要获取key的集合,例 ['k1','k2'];*args:要获取的key,如:k1,k2,k3
hgetall(name):获取name对应hash的所有键值
hlen(name):获取name对应的hash中键值的个数
hkeys(name):获取name对应的hash中所有的key的值
hvals(name):获取name对应的hash中所有的value的值
hexists(name,key):检查name对应的hash是否存在当前传入的key
hdel(name,*keys):将name对应的hash中指定key的键值对删除
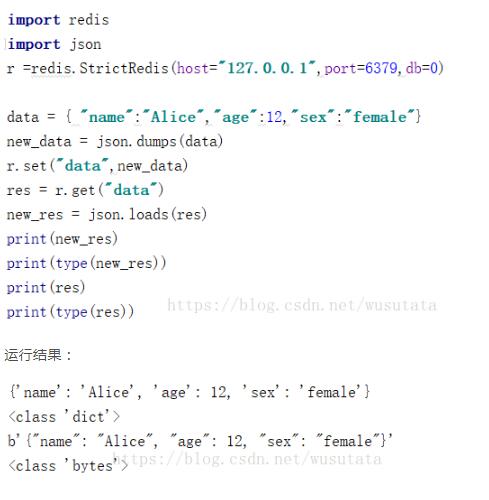
补充知识:将python数据存入redis中,键取字符串类型
使用redis中的字符串类型键来存储一个python的字典。首先需要使用json模块的dumps方法将python字典转换为字符串,然后存入redis,从redis中取出来必须使用json.loads方法转换为python的字典(其他python数据结构处理方式也一样)。
如果不使用json.loads方法转换则会发现从redis中取出的数据的数据类型是bytes.
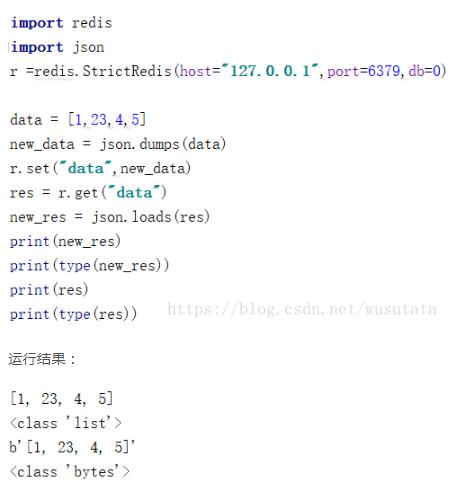
当使用的python数据结构是列表时:
以上这篇Python 抓取数据存储到Redis中的操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python操作redis方法总结
连接 Redis import redisc 连接方式:redis提供了2个方法 1:StrictRedis:实现大部分官方的命令 2:Redis:是StrictRedis的子类,用于向后兼容旧版的redis. 官方推荐使用StrictRedis方法. 举例(普通连接): import redis #decode_responses=True 自动解码 r = redis.Redis(host='127.0.0.1',port=6379,password='123456',db=0,decode
-
Python获取Redis所有Key以及内容的方法
一.获取所有Key # -*- encoding: UTF-8 -*- __author__ = "Sky" import redis pool=redis.ConnectionPool(host='127.0.0.1',port=6379,db=0) r = redis.StrictRedis(connection_pool=pool) keys = r.keys() print type(keys) print keys 运行结果: <type 'list'> ['fa
-
Python读写Redis数据库操作示例
使用Python如何操作Redis呢?下面用实例来说明用Python读写Redis数据库.比如,我们插入一条数据,如下: 复制代码 代码如下: import redis class Database: def __init__(self): self.host = 'localhost' self.port = 6379 def write(self,website,city,year,month,day,deal_number):
-
Python定时从Mysql提取数据存入Redis的实现
设计思路: 1.程序一旦run起来,python会把mysql中最近一段时间的数据全部提取出来 2.然后实例化redis类,将数据简单解析后逐条传入redis队列 3.定时器设计每天凌晨12点开始跑 ps:redis是个内存数据库,做后台消息队列的缓存时有很大的用处,有兴趣的小伙伴可以去查看相关的文档. # -*- coding:utf-8 -*- import MySQLdb import schedule import time import datetime import random i
-
Python 抓取数据存储到Redis中的操作
redis是一个key-value存储结构.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorted set 有序集合)和hash(哈希类型),数据存储如下图分析 为了分别为ID存入多个键值对,此次仅对Hash数据进行操作,例子如下 import os,sys import requests import bs4 import redis #连接Redis r = redis.Redis(host='127
-

手把手教你Python抓取数据并可视化
目录 前言 一.数据抓取篇 1.简单的构建反爬措施 2.解析数据 3.完整代码 二.数据可视化篇 1.数据可视化库选用 2.案例实战 (1).柱状图Bar (2).地图Map (3).饼图Pie (4).折线图Line (5).组合图表 总结 前言 大家好,这次写作的目的是为了加深对数据可视化pyecharts的认识,也想和大家分享一下.如果下面文章中有错误的地方还请指正,哈哈哈!!!本次主要用到的第三方库: requests pandas pyecharts 之所以数据可视化选用pyechar
-
Python抓取数据到可视化全流程的实现过程
目录 1.爬取目标网站:业绩预告_数据中心_同花顺财经 2.获取序号.股票代码.等你所需要的信息 3.组成DataFrame 4.处理数据 1.爬取目标网站:业绩预告_数据中心_同花顺财经 (ps:headers不会设置的可以看这篇:Python 用requests.get获取网页内容为空 ’ ’) import pandas as pd import numpy as np import matplotlib.pyplot as plt import re import requests##把
-
Python抓取框架 Scrapy的架构
最近在学Python,同时也在学如何使用python抓取数据,于是就被我发现了这个非常受欢迎的Python抓取框架Scrapy,下面一起学习下Scrapy的架构,便于更好的使用这个工具. 一.概述 下图显示了Scrapy的大体架构,其中包含了它的主要组件及系统的数据处理流程(绿色箭头所示).下面就来一个个解释每个组件的作用及数据的处理过程. 二.组件 1.Scrapy Engine(Scrapy引擎) Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发.更多的详细内容可以看下
-
浅谈如何使用python抓取网页中的动态数据实现
我们经常会发现网页中的许多数据并不是写死在HTML中的,而是通过js动态载入的.所以也就引出了什么是动态数据的概念,动态数据在这里指的是网页中由Javascript动态生成的页面内容,是在页面加载到浏览器后动态生成的,而之前并没有的. 在编写爬虫进行网页数据抓取的时候,经常会遇到这种需要动态加载数据的HTML网页,如果还是直接从网页上抓取那么将无法获得任何数据. 今天,我们就在这里简单聊一聊如何用python来抓取页面中的JS动态加载的数据. 给出一个网页:豆瓣电影排行榜,其中的所有电影信息都是
-
python制作爬虫并将抓取结果保存到excel中
学习Python也有一段时间了,各种理论知识大体上也算略知一二了,今天就进入实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫. 第一步:分析网站的请求过程 我们在查看拉勾网上的招聘信息的时候,搜索Python,或者是PHP等等的岗位信息,其实是向服务器发出相应请求,由服务器动态的响应请求,将我们所需要的内容通过浏览器解析,呈现在我们的面前. 可以看到我们发出的请求当中,FormData中的kd参数,就代表着向服务器请求关键词为Python的招聘信息. 分析比较复杂的页面请求与响应信息,
-
Python基于多线程实现抓取数据存入数据库的方法
本文实例讲述了Python基于多线程实现抓取数据存入数据库的方法.分享给大家供大家参考,具体如下: 1. 数据库类 """ 使用须知: 代码中数据表名 aces ,需要更改该数据表名称的注意更改 """ import pymysql class Database(): # 设置本地数据库用户名和密码 host = "localhost" user = "root" password = "&quo
-
python实现scrapy爬虫每天定时抓取数据的示例代码
1. 前言. 1.1. 需求背景. 每天抓取的是同一份商品的数据,用来做趋势分析. 要求每天都需要抓一份,也仅限抓取一份数据. 但是整个爬取数据的过程在时间上并不确定,受本地网络,代理速度,抓取数据量有关,一般情况下在20小时左右,极少情况下会超过24小时. 1.2. 实现功能. 通过以下三步,保证爬虫能自动隔天抓取数据: 每天凌晨00:01启动监控脚本,监控爬虫的运行状态,一旦爬虫进入空闲状态,启动爬虫. 一旦爬虫执行完毕,自动退出脚本,结束今天的任务. 一旦脚本距离启动时间超过24小时,自动
-
python抓取网页中链接的静态图片
本文实例为大家分享了python抓取网页中链接的静态图片的具体代码,供大家参考,具体内容如下 # -*- coding:utf-8 -*- #http://tieba.baidu.com/p/2460150866 #抓取图片地址 from bs4 import BeautifulSoup import urllib.request from time import sleep html_doc = "http://tieba.baidu.com/p/2460150866" def ge
-
python将类似json的数据存储到MySQL中的实例
由于之前对于爬取下来的数据都是存入MongoDB中,想起来还没有尝试存入MySQL,于是将一篇简单的文章爬取下来,存入MySQL试试 这里用到的python模块是pymysql,因为MySQLdb之前已经停止维护 首先在cmd中连接MySQL并且创建一个数据库json 在图形化界面workbench中可以看到 接下来就要在pycharm中写代码了,在pycharm中导入pymysql后即可 #建立python与MySQL之间的连接 mysql = pymysql.connect(host="lo