基于YUV 数据格式详解及python实现方式
YUV 数据格式概览
YUV 的原理是把亮度与色度分离,使用 Y、U、V 分别表示亮度,以及蓝色通道与亮度的差值和红色通道与亮度的差值。其中 Y 信号分量除了表示亮度 (luma) 信号外,还含有较多的绿色通道量,单纯的 Y 分量可以显示出完整的黑白图像。U、V 分量分别表示蓝 (blue)、红 (red) 分量信号,它们只含有色彩 (chrominance/color) 信息,所以 YUV 也称为 YCbCr,C 意思可以理解为 (component 或者 color)。
维基百科上的 RGB 转 YUV 的公式能更好的反应 YUV 与 RGB 的关系,以及为什么称为 YCbCr:
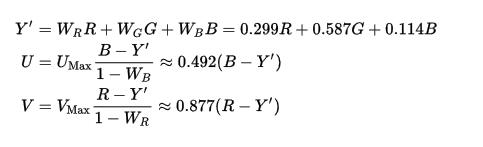
Y 中含有三元色色信息,且有较多的 G,所以他们一起可以显示出全彩的图像。
很显然我们可以想到是不是会有 YCgCb、YCgCr 等,针对不同的应用场景,也确实有相关应用研究。
如下图,一张从上到下分别为原图、Y、U 和 V:

采用 YUV 而不是使用 RGB,既有历史原因:为了兼容老式黑白电视,因为 YUV 如果只输出 Y 就成了黑白图像了。也有 YUV 自己的其他优点,例如可以根据需要,采用特定的 YUV 存储格式,以降低祼码流的空间占用。
YUV 存储格式
YUV 存储格式有两大类:planar 和 packed。
对于 planar 的 YUV 格式,先连续存储所有像素点的 Y,紧接着存储所有像素点的 U,随后是所有像素点的 V。相当于将 YUV 拆分成三个平面 (plane) 存储。
对于 packed 的 YUV 格式,每个像素点的 Y,U,V 是连续交替存储的。
YUV 码流又根据不同的采样方式分为 YUV4:4:4、YUV4:2:2、YUV4:2:0、YUV4:1:1 等存储格式,其中前 3 种较常见。所谓采样意思就是根据一定的间隔取值。其中的比例是指 Y、U、V 表示的像素,三者分别占的比值。可以按照如下方式理解,实现存储和扫描与 DVD 的扫描线有关。
例如:
YUV4:4:4 是指每个像素分别有一个 Y、一个 U 和一个 V 组成,即每 4 个 Y 采样,就对应 4 个 Cb 和 4 个 Cr 采样,也就是一个像素占用 8+8+8=24 位,这种存储方式图像质量最高,但空间占用也最大,空间占用与 RGB 存储时一样。对于一个 M*N分辨率的图像,该模式下存储空间占用字节数为 M*N*3。
YUV4:2:2 是指每 4 个 Y 采样,对应 2 个 Cb 和 2 个 Cr 采样,这样在解析时就会有一些像素点只有亮度信息而没有色度信息,缺失的色度信息就需要在解析时由相邻的其他色度信息根据一定的算法填充。这种方式下平均一个像素占用空间为 8+4+4=16 位。对于一个 M*N 分辨率的图像,空间占用 16/24,即 M*N*3*(16/24) = M*n*2 个字节。
YUV4:2:0 是指每 4 个 4 采样,对应 2 个 U 采样或者 2 个 V 采样,注意其中并不是表示 2 个 U 和 0 个 V,而是指无论水平下采样还是垂直下采样,色度采样都只有亮度的一半。该存储格式下,平均每个像素占用空间为 8+4+0=12 位。对于一个 M*N 分辨率的图像来说,空间占用为原来的 12/24,即 M*N*3*(12/24)=M*N*3/2。节省较多存储空间,该存储格式也最常用。
YUV4:1:1 是指每 4 个 Y 采样,对应 1 个 U 采样和一个 V 采样。平均每个像素占用空间为 8+2+2=12 位。图像空间占用情况同上。这种存储格式实际使用的非常少。
对于 packed 存储格式,略。
YV12/I420/YU12/NV12/NV21
YV12/I420/YU12/NV12/NV21 都属于 YUV 4:2:0。YU12 就是 I420,YV12/I420 也称为 YUV420P(即平面格式,planar),YV12 与标准模式 I420 的区别是 UV 顺序不同。
YV12 取名来源是 Y 后面紧跟 V(然后是 U),12 表示它位深为 12,也就是一个像素占用空间为 12 位。
在 I420(YU12) 格式中,U 平面紧跟在 Y 平面之后,然后才是 V 平面(即:YUV);但 YV12 则是相反(即:YVU)。大部分视频解码器的输出的原始图像都是 I420 格式(例如安卓下的图像通常都是 I420 或 NV21),而多数硬解码器中使用的都是 NV12 格式(例如 Intel MSDK、NVIDIA 的 cuvid、IOS 硬解码)。
另一类 YUV420SP, Y 分量平面格式,UV 打包格式,即 NV12。 NV12 与 NV21 类似,U 和 V 交错排列,不同在于 UV 顺序。
可理解如下:
I420: YYYYYYYY UU VV => YUV420P
YV12: YYYYYYYY VV UU => YUV420P
NV12: YYYYYYYY UVUV => YUV420SP
NV21: YYYYYYYY VUVU => YUV420SP
维基百科上有两张 I420 和 NV12 的两张图非常好:
I420 的单帧结构示意图如下(Planar 方式):
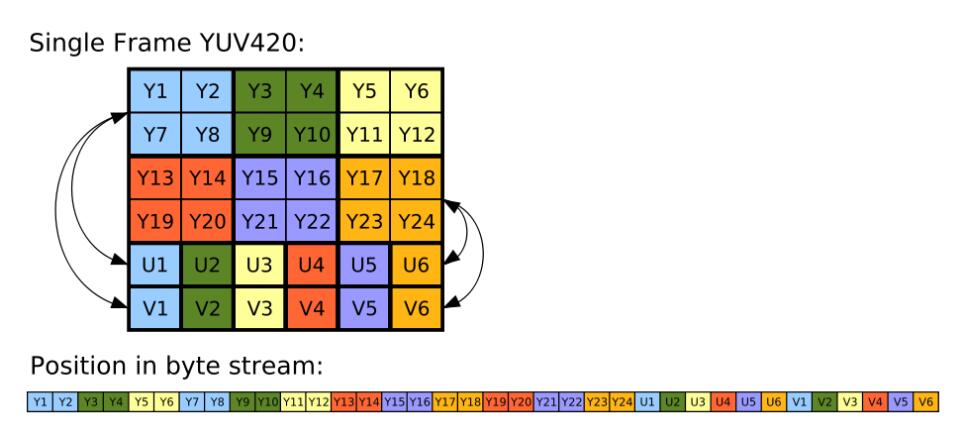
这幅图的上面一幅可以看出 Y1、Y2、Y7、Y8 共用 U1 和 V1。后面的线性数组为其存储顺序,可以看出 Y、U 和 V 都是顺序存储的,往外写的时候,先按顺序将 Y 分量写出,然后再根据 U、V 分别将它们依次写出即可。
NV12 的单帧结构示意图如下(Planar 方式):
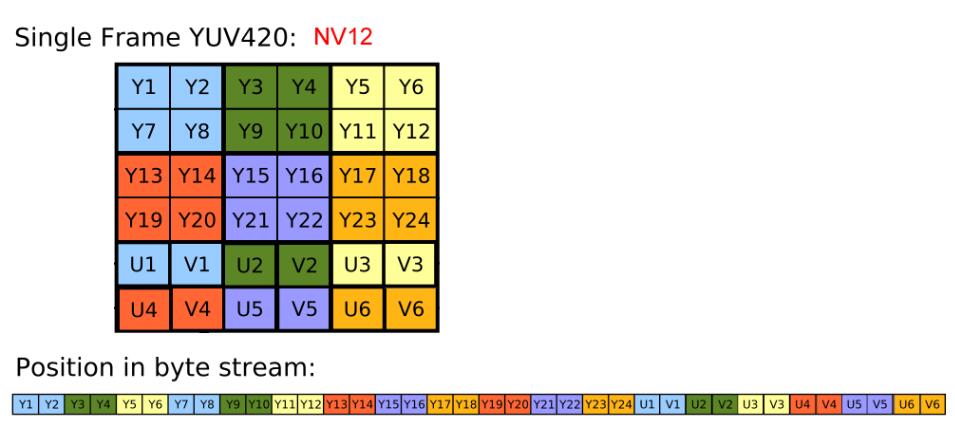
可以看出与 YV12 不同的时,它的 Y 虽然也是顺序存储,但 U、V 却是交错存储的,这种方式存储在往外写出时则先直接顺序写出 Y,然后对 UV 分别依次写出。
Python的实现:将420P转为jpg
from PIL import Image
def yuv420_to_rgb888(width, height, yuv):
# function requires both width and height to be multiples of 4
if (width % 4) or (height % 4):
raise Exception("width and height must be multiples of 4")
rgb_bytes = bytearray(width*height*3)
red_index = 0
green_index = 1
blue_index = 2
y_index = 0
for row in range(0,height):
u_index = width * height + (row//2)*(width//2)
v_index = u_index + (width*height)//4
for column in range(0,width):
Y = yuv[y_index]
U = yuv[u_index]
V = yuv[v_index]
C = (Y - 16) * 298
D = U - 128
E = V - 128
R = (C + 409*E + 128) // 256
G = (C - 100*D - 208*E + 128) // 256
B = (C + 516 * D + 128) // 256
R = 255 if (R > 255) else (0 if (R < 0) else R)
G = 255 if (G > 255) else (0 if (G < 0) else G)
B = 255 if (B > 255) else (0 if (B < 0) else B)
rgb_bytes[red_index] = R
rgb_bytes[green_index] = G
rgb_bytes[blue_index] = B
u_index += (column % 2)
v_index += (column % 2)
y_index += 1
red_index += 3
green_index += 3
blue_index += 3
return rgb_bytes
def testConversion(source, dest):
print("opening file")
f = open(source, "rb")
yuv = f.read()
f.close()
print("read file")
rgb_bytes = yuv420_to_rgb888(4208,3120, yuv)
# cProfile.runctx('yuv420_to_rgb888(1920,1088, yuv)', {'yuv420_to_rgb888':yuv420_to_rgb888}, {'yuv':yuv})
print("finished conversion. Creating image object")
img = Image.frombytes("RGB", (4208,3120), bytes(rgb_bytes))
print("Image object created. Starting to save")
img.save(dest, "JPEG")
img.close()
print("Save completed")
testConversion("C:/adb1031/yuveffectout/MV_F_Cap1.yuv", "C:/adb1031/yuveffectout/MV_F_Cap1.jpg")
testConversion("C:/adb1031/yuveffectout/MV_F_Cap2.yuv", "C:/adb1031/yuveffectout/MV_F_Cap2.jpg")
Python的实现:将NV21转为jpg
from PIL import Image
def yuv420_to_rgb888(width, height, yuv):
# function requires both width and height to be multiples of 4
if (width % 4) or (height % 4):
raise Exception("width and height must be multiples of 4")
rgb_bytes = bytearray(width*height*3)
red_index = 0
green_index = 1
blue_index = 2
y_index = 0
v_index = width * height
for row in range(0,height):
v_index = width * height + (row//2)*width
u_index = v_index + 1
for column in range(0,width):
Y = yuv[y_index]
#print(y_index)
U = yuv[u_index]
V = yuv[v_index]
C = (Y - 16) * 298
D = U - 128
E = V - 128
R = (C + 409*E + 128) // 256
G = (C - 100*D - 208*E + 128) // 256
B = (C + 516 * D + 128) // 256
R = 255 if (R > 255) else (0 if (R < 0) else R)
G = 255 if (G > 255) else (0 if (G < 0) else G)
B = 255 if (B > 255) else (0 if (B < 0) else B)
rgb_bytes[red_index] = R
rgb_bytes[green_index] = G
rgb_bytes[blue_index] = B
if column==0:
v_index = v_index
elif column%2==0:
v_index = v_index + 2
u_index = v_index + 1
y_index += 1
red_index += 3
green_index += 3
blue_index += 3
return rgb_bytes
def testConversion(source, dest):
print("opening file")
f = open(source, "rb")
yuv = f.read()
f.close()
print("read file")
rgb_bytes = yuv420_to_rgb888(1280,720, yuv)
# cProfile.runctx('yuv420_to_rgb888(1920,1088, yuv)', {'yuv420_to_rgb888':yuv420_to_rgb888}, {'yuv':yuv})
print("finished conversion. Creating image object")
img = Image.frombytes("RGB", (1280,720), bytes(rgb_bytes))
print("Image object created. Starting to save")
img.save(dest, "JPEG")
img.close()
print("Save completed")
testConversion("./test/4.yuv", "4.jpg")
以上这篇基于YUV 数据格式详解及python实现方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python 读取 YUV(NV12) 视频文件实例
一.YUV 简介 YUV:是一种颜色编码方法,常使用在各个视频处理组件中 Y'UV, YCbCr, YPbPr等专有名词都可以称为 YUV,彼此有重叠 Y表示明亮度(单取此通道即可得灰度图),U和V则是色度.浓度 主流的采样方式有三种,YUV4:4:4,YUV4:2:2,YUV4:2:0 可以根据其采样格式来从码流中还原每个像素点的 YUV 值,进而通过 YUV 与 RGB 的转换公式提取出每个像素点的 RGB 值,然后显示出来 YUV4:2:0 数据在内存中的长度是 3 / 2 * heigt
-
基于YUV 数据格式详解及python实现方式
YUV 数据格式概览 YUV 的原理是把亮度与色度分离,使用 Y.U.V 分别表示亮度,以及蓝色通道与亮度的差值和红色通道与亮度的差值.其中 Y 信号分量除了表示亮度 (luma) 信号外,还含有较多的绿色通道量,单纯的 Y 分量可以显示出完整的黑白图像.U.V 分量分别表示蓝 (blue).红 (red) 分量信号,它们只含有色彩 (chrominance/color) 信息,所以 YUV 也称为 YCbCr,C 意思可以理解为 (component 或者 color). 维基百科上的 RGB
-
基于JSON数据格式详解
JSON是行业内使用最为广泛的数据交换格式,在很多场景都有广泛的应用.JSON适用于进行数据交互的场景,典型的是Ajax中实现异步加载:为了支持跨平台.数据安全等的Web Service也可以使用(API接口返回值). JSON(JavaScript Object Notation)是一种完全独立于语言的.轻量级的数据交换格式.它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一个子
-
详解用Python进行时间序列预测的7种方法
数据准备 数据集(JetRail高铁的乘客数量)下载. 假设要解决一个时序问题:根据过往两年的数据(2012 年 8 月至 2014 年 8月),需要用这些数据预测接下来 7 个月的乘客数量. import pandas as pd import numpy as np import matplotlib.pyplot as plt df = pd.read_csv('train.csv') df.head() df.shape 依照上面的代码,我们获得了 2012-2014 年两年每个小时的乘
-

详解在Python中使用OpenCV进行直线检测
目录 1.引言 2.霍夫变换 3.举个栗子 3.1读入图像进行灰度化 3.2执行边缘检测 3.3进行霍夫变换 补充 1. 引言 在图像处理中,直线检测是一种常见的算法,它通常获取n个边缘点的集合,并找到通过这些边缘点的直线.其中用于直线检测,最为流行的检测器是基于霍夫变换的直线检测技术. 2. 霍夫变换 霍夫变换是图像处理中的一种特征提取方法,可以识别图像中的几何形状.它将在参数空间内进行投票来决定其物体形状,通过检测累计结果找到一极大值所对应的解,利用此解即可得到一个符合特定形状的参数. 在使
-
详解使用python的logging模块在stdout输出的两种方法
详解使用python的logging模块在stdout输出 前言: 使用python的logging模块时,除了想将日志记录在文件中外,还希望在前台执行python脚本时,可以将日志直接输出到标准输出std.out中. 实现 logging模块可以有两种方法实现该功能: 方案一:basicconfig import sys import logging logging.basicConfig(stream=sys.stdout, level=logging.DEBUG) 方案二:handler
-
详解用Python爬虫获取百度企业信用中企业基本信息
一.背景 希望根据企业名称查询其经纬度,所在的省份.城市等信息.直接将企业名称传给百度地图提供的API,得到的经纬度是非常不准确的,因此希望获取企业完整的地理位置,这样传给API后结果会更加准确. 百度企业信用提供了企业基本信息查询的功能.希望通过Python爬虫获取企业基本信息.目前已基本实现了这一需求. 本文最后会提供具体的代码.代码仅供学习参考,希望不要恶意爬取数据! 二.分析 以苏宁为例.输入"江苏苏宁"后,查询结果如下: 经过分析,这里列示的企业信息是用JavaScript动
-
阿里云OSS基于java使用详解
近几年,云图片服务器五花八门,越来越多,有腾讯云,阿里云,又拍云,华为云等等,但是使用了这么多年,我还是感觉阿里云图片服务器oss比较稳定,访问速度也比较快,因此我在这里手把手教给你如何使用阿里云oss服务: 一.使用之前,我们还是先来搞清楚阿里云oss使用的原理吧: 其实调用方式也就两种,一种是直接客户端调用阿里云提供的服务器进行上传,一种是通过服务器间接上传,我们来分析以下优缺点吧: 上传方式优点缺点直接调用上传速度快,能直接快速上传到阿里云服务器,不需要中转可能会不安全,暴露核心配置信息间
-
详解在Python中使用Torchmoji将文本转换为表情符号
很难找到关于如何使用Python使用DeepMoji的教程.我已经尝试了几次,后来又出现了几次错误,于是决定使用替代版本:torchMoji. TorchMoji是DeepMoji的pyTorch实现,可以在这里找到:https://github.com/huggingface/torchMoji 事实上,我还没有找到一个关于如何将文本转换为表情符号的教程.如果你也没找到,那么本文就是一个了. 安装 这些代码并不完全是我的写的,源代码可以在这个链接上找到. pip3 install torch=
-
详解用Python调用百度地图正/逆地理编码API
一.背景 (正)地理编码指的是:将地理位置名称转换成经纬度: 逆地理编码指的是:将经纬度转换成地理位置信息,如地名.所在的省份或城市等 百度地图提供了相应的API,可以方便调用.相应的说明文档如下: 正地理编码 逆地理编码 具体API的参数可以查看相应的"服务文档": 不过首次使用时需要申请,具体在控制台.申请AK的方式可参见其他文章. 二.源码 废话不多说,直接放源码.这里提供了Python调用这两个API的方法. #!/usr/bin/env python # -*- coding
-
详解使用Python写一个向数据库填充数据的小工具(推荐)
一. 背景 公司又要做一个新项目,是一个合作型项目,我们公司出web展示服务,合作伙伴线下提供展示数据. 而且本次项目是数据统计展示为主要功能,并没有研发对应的数据接入接口,所有展示数据源均来自数据库查询, 所以验证数据没有别的入口,只能通过在数据库写入数据来进行验证. 二. 工具 Python+mysql 三.前期准备 前置:当然是要先准备好测试方案和测试用例,在准备好这些后才能目标明确将要开发自动化小工具都要有哪些功能,避免走弯路 3.1 跟开发沟通 1)确认数据库连接方式,库名 : 2)测