Python 实现自动获取种子磁力链接方式
因为我闲来无事,所以准备找一部电影来看看。 然后我找到了种子搜索网站,可是这类网站的弹窗广告太多,搞得我很烦。所以我就想着自己用python写一个自动获取磁力链接的脚本。
整个大概写了半个小时。
代码如下
import requests
import re
from bs4 import BeautifulSoup
url="*种子的网站*/"
header={
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.8",
"Cache-Control":"max-age=0",
"Connection":"keep-alive",
"Content-Length":"65",
"Content-Type":"application/x-www-form-urlencoded",
"Host":"btkitty.bid",
"Origin":"*种子的网站*",
"Referer":"*种子的网站*/",
"Upgrade-Insecure-Requests":"1",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0.14393; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2950.5 Safari/537.36"
}
while True:
word=input("输入搜索关键词:")
data={
"keyword":word,
"hidden":"true"
}
res=requests.post(url,data=data,headers=header)
bs=BeautifulSoup(res.text,"lxml")
itemInfo=bs.find_all("dd",class_="option")
torrent={}
for item in itemInfo:
magnet=item.find_next("a",href=re.compile("magnet.*")).attrs["href"]
name=item.find_previous("a",href=re.compile("*种子的网站*/.*\.html")).text
size=item.find_next(text=re.compile("\u6587\u4ef6\u5927\u5c0f")).find_next("b").text
time=item.find_next(text=re.compile("\u6536\u5f55\u65f6\u95f4")).find_next("b").text
hot=item.find_next(text=re.compile("\u4eba\u6c14")).find_next("b").text
torrent[name]=[name,time,size,hot,magnet]
for item in torrent:
print("名称:",torrent[item][0])
print("发布时间:",torrent[item][1])
print("大小:",torrent[item][2])
print("热度:",torrent[item][3])
print("磁力链接:",torrent[item][4],'\n')
运行结果如下
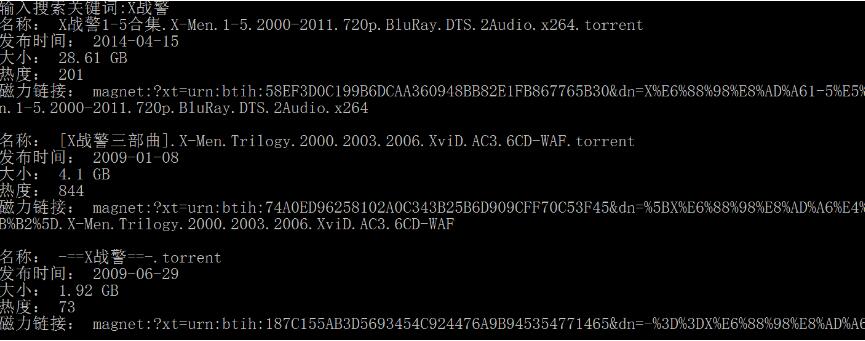
以上这篇Python 实现自动获取种子磁力链接方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Pytorch在dataloader类中设置shuffle的随机数种子方式
如题:Pytorch在dataloader类中设置shuffle的随机数种子方式 虽然实验结果差别不大,但是有时候也悬殊两个百分点 想要复现实验结果 发现用到随机数的地方就是dataloader类中封装的shuffle属性 查了半天没有关于这个的设置,最后在设置随机数种子里面找到了答案 以下方法即可: def setup_seed(seed): torch.manual_seed(seed) torch.cuda.manual_seed_all(seed) np.random.seed(seed
-
Python内置random模块生成随机数的方法
本文我们详细地介绍下两个模块关于生成随机序列的其他使用方法. 随机数参与的应用场景大家一定不会陌生,比如密码加盐时会在原密码上关联一串随机数,蒙特卡洛算法会通过随机数采样等等.Python内置的random模块提供了生成随机数的方法,使用这些方法时需要导入random模块. import random 下面介绍下Python内置的random模块的几种生成随机数的方法. 1.random.random()随机生成 0 到 1 之间的浮点数[0.0, 1.0).注意的是返回的随机数可能会是 0 但
-
Python简单实现区域生长方式
区域生长是一种串行区域分割的图像分割方法.区域生长是指从某个像素出发,按照一定的准则,逐步加入邻近像素,当满足一定的条件时,区域生长终止.区域生长的好坏决定于1.初始点(种子点)的选取.2.生长准则.3.终止条件.区域生长是从某个或者某些像素点出发,最后得到整个区域,进而实现目标的提取. 区域生长的原理: 区域生长的基本思想是将具有相似性质的像素集合起来构成区域.具体先对每个需要分割的区域找一个种子像素作为生长起点,然后将种子像素和周围邻域中与种子像素有相同或相似性质的像素(根据某种事先确定
-
Python 实现自动获取种子磁力链接方式
因为我闲来无事,所以准备找一部电影来看看. 然后我找到了种子搜索网站,可是这类网站的弹窗广告太多,搞得我很烦.所以我就想着自己用python写一个自动获取磁力链接的脚本. 整个大概写了半个小时. 代码如下 import requests import re from bs4 import BeautifulSoup url="*种子的网站*/" header={ "Accept":"text/html,application/xhtml+xml,appli
-
Python如何自动获取目标网站最新通知
不管是一名学生,亦或是一名员工,我们都需要时刻注意学校或公司网站的通知,尽量做到即时获取最新消息. 大部分博客或数据资源网站都会有自己的RSS提示系统,便于将网站的最新信息及时推送给需要的用户,而用户也可以通过RSS阅读器来即时地获取到目标网站的最新内容. 由于学校或公司网站服务对象的特殊性和局限性,一般不会建立自己的RSS系统. 作为优秀的人儿,我们可以建立自己的RSS提示系统. 这里介绍了如何使用Python和常用的计算机小程序来构建一个RSS提示系统,做到定时自动检测目标网站发布的通知,并
-

Python之自动获取公网IP的实例讲解
0.预备知识 0.1 SQL基础 ubuntu.Debian系列安装: root@raspberrypi:~/python-script# apt-get install mysql-server Redhat.Centos 系列安装: [root@localhost ~]# yum install mysql-server 登录数据库 pi@raspberrypi:~ $ mysql -uroot -p -hlocalhost Enter password: Welcome to the Ma
-
使用Python实现BT种子和磁力链接的相互转换
bt种子文件转换为磁力链接 BT种子文件相对磁力链来说存储不方便,而且在网站上存放BT文件容易引起版权纠纷,而磁力链相对来说则风险小一些.而且很多论坛或者网站限制了文件上传的类型,分享一个BT种子还需要改文件后缀或者压缩一次,其他人需要下载时候还要额外多一步下载种子的操作. 所以将BT种子转换为占用空间更小,分享更方便的磁力链还是有挺大好处的. 首先一个方案是使用bencode这个插件,通过pip方式安装或者自行下载源文件https://pypi.python.org/pypi/bencode/
-
python实现自动获取IP并发送到邮箱
树莓派没有显示器,而不想设置固定IP,因为要随身携带外出,每个网络环境可能网段不一样.因此想用python写个脚本,让树莓派开机后自动获取本机ip,并且自动发送到我指定邮箱.(完整源码) 1.获取所有连接的网络接口,比如有线.wifi等接口 def get_ip_address(): #先获取所有网络接口 SIOCGIFCONF = 0x8912 SIOCGIFADDR = 0x8915 BYTES = 4096 sck = socket.socket(socket.AF_INET, socke
-
C++获取文件哈希值(hash)和获取torrent(bt种子)磁力链接哈希值
复制代码 代码如下: // CHash.h : header file #pragma once#include "sha1.h" #define SIZE_OF_BUFFER 16000 class CHash{// Constructionpublic: CString SHA1Hash(CString strHashFile);}; 复制代码 代码如下: // CHash.cpp : implementation file//#include
-
python获取文件真实链接的方法,针对于302返回码
使用模块requests 方式代码如下: import requests url_string="https://******" r = requests.head(url_string, stream=True) print r.headers['Location'] 扩展: 设置属性:allow_redirects = True ,则head方式会自动解析重定向链接,requests.get()方法的allow_redirects默认为True,head方法默认为False url
-
python爬虫_自动获取seebug的poc实例
简单的写了一个爬取www.seebug.org上poc的小玩意儿~ 首先我们进行一定的抓包分析 我们遇到的第一个问题就是seebug需要登录才能进行下载,这个很好处理,只需要抓取返回值200的页面,将我们的headers信息复制下来就行了 (这里我就不放上我的headers信息了,不过headers里需要修改和注意的内容会在下文讲清楚) headers = { 'Host':******, 'Connection':'close', 'Accept':******, 'User-Agent':*
-
python网络爬虫之模拟登录 自动获取cookie值 验证码识别的具体实现
目录 1.爬取网页分析 2.验证码识别 3.cookie自动获取 4.程序源代码 chaojiying.py sign in.py 1.爬取网页分析 爬取的目标网址为:https://www.gushiwen.cn/ 在登陆界面需要做的工作有,获取验证码图片,并识别该验证码,才能实现登录. 使用浏览器抓包工具可以看到,登陆界面请求头包括cookie和user-agent,故在发送请求时需要这两个数据.其中user-agent可通过手动添加到请求头中,而cookie值需要自动获取. 分析完毕,实践
-
python自动获取微信公众号最新文章的实现代码
目录 微信公众号获取思路 采集实例 微信公众号获取思路 常用的微信公众号文章获取方法有搜狐.微信公众号主页获取和api接口等多个方法.听说搜狐最近不怎么好用了,之前用的api接口也频繁维护,所以用了微信公众平台来进行数据爬取.首先登陆自己的微信公众平台,没有账号的可以注册一个.进来之后找“图文信息”,就是写公众号的地方 点进去后就是写公众号文章的界面,在界面中找到“超链接” 的字段,在这里就可以对其他的公众号进行检索. 以“python”为例,输入要检索的公众号名称,在显示的公众号中选择要采集的