详解SQL中Group By的使用教程
1、概述
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
2、原始表
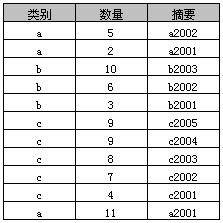
3、简单Group By示例1
select 类别, sum(数量) as 数量之和from Agroup by 类别
返回结果如下表,实际上就是分类汇总。
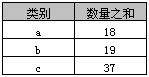
4、Group By 和 Order By示例2
select 类别, sum(数量) AS 数量之和from Agroup by 类别order by sum(数量) desc
返回结果如下表
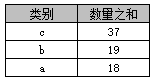
在Access中不可以使用“order by 数量之和 desc”,但在SQL Server中则可以。
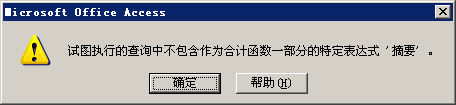
5、Group By中Select指定的字段限制示例3
select 类别, sum(数量) as 数量之和, 摘要from Agroup by 类别order by 类别 desc
示例3执行后会提示下错误,如下图。这就是需要注意的一点,在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。
6、Group By All示例4
select 类别, 摘要, sum(数量) as 数量之和from Agroup by all 类别, 摘要
示例4中则可以指定“摘要”字段,其原因在于“多列分组”中包含了“摘要字段”,其执行结果如下表
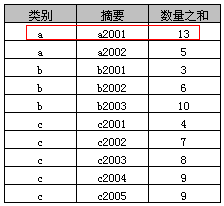
“多列分组”实际上就是就是按照多列(类别+摘要)合并后的值进行分组,示例4中可以看到“a, a2001, 13”为“a, a2001, 11”和“a, a2001, 2”两条记录的合并。
SQL Server中虽然支持“group by all”,但Microsoft SQL Server 的未来版本中将删除 GROUP BY ALL,避免在新的开发工作中使用 GROUP BY ALL。Access中是不支持“Group By All”的,但Access中同样支持多列分组,上述SQL Server中的SQL在Access可以写成
select 类别, 摘要, sum(数量) AS 数量之和from Agroup by 类别, 摘要
7、Group By与聚合函数
在示例3中提到group by语句中select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中,常见的聚合函数如下表:
| 函数 | 作用 | 支持性 |
|---|---|---|
| sum(列名) | 求和 | |
| max(列名) | 最大值 | |
| min(列名) | 最小值 | |
| avg(列名) | 平均值 | |
| first(列名) | 第一条记录 | 仅Access支持 |
| last(列名) | 最后一条记录 | 仅Access支持 |
| count(列名) | 统计记录数 | 注意和count(*)的区别 |
示例5:求各组平均值
select 类别, avg(数量) AS 平均值 from A group by 类别;
示例6:求各组记录数目
select 类别, count(*) AS 记录数 from A group by 类别;
示例7:求各组记录数目
8、Having与Where的区别
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
示例8
select 类别, sum(数量) as 数量之和 from Agroup by 类别having sum(数量) > 18
示例9:Having和Where的联合使用方法
select 类别, SUM(数量)from Awhere 数量 gt;8group by 类别having SUM(数量) gt; 10
9、Compute 和 Compute By
select * from A where 数量 > 8
执行结果:
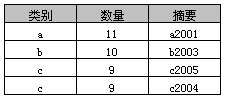
示例10:Compute
select *from Awhere 数量>8compute max(数量),min(数量),avg(数量)
执行结果如下:
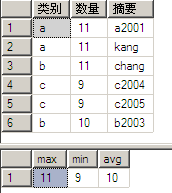
compute子句能够观察“查询结果”的数据细节或统计各列数据(如例10中max、min和avg),返回结果由select列表和compute统计结果组成。
示例11:Compute By
select *from Awhere 数量>8order by 类别compute max(数量),min(数量),avg(数量) by 类别
执行结果如下:
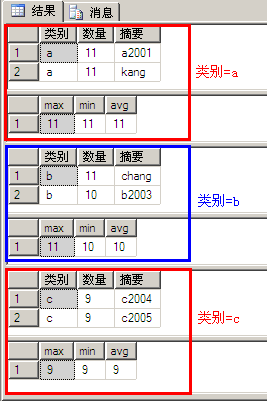
示例11与示例10相比多了“order by 类别”和“... by 类别”,示例10的执行结果实际是按照分组(a、b、c)进行了显示,每组都是由改组数据列表和改组数统计结果组成,另外:
- compute子句必须与order by子句用一起使用
- compute...by与group by相比,group by 只能得到各组数据的统计结果,而不能看到各组数据
在实际开发中compute与compute by的作用并不是很大,SQL Server支持compute和compute by,而Access并不支持
总结
以上所述是小编给大家介绍的详解SQL中Group By的使用教程,希望对大家有所帮助!
相关推荐
-
简单讲解sql语句中的group by的使用方法
1.概述 group by 就是依据by 后面的规则对数据分组,所谓的分组就是讲数据集划分成若干个'小组',针对若干个小组做处理. 2.语法规则 SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name 3.举例说明 我们有这样一个订单表: 我们希望统计每一个用户订单的总金额,我们可以借助 group by 来实
-
使用mysql的disctinct group by查询不重复记录
有个需求,一直没有解决,在google上找了半天,给出的方案没有一个能用了,最后鬼使神差搞定了. 是这样的,假设一个表: id f_id value 1 2 a 2 2 b 3 5 c 4 9 c 5 9 a 6 6 d id f_id value 1 2 a 2
-

mysql使用GROUP BY分组实现取前N条记录的方法
本文实例讲述了mysql使用GROUP BY分组实现取前N条记录的方法.分享给大家供大家参考,具体如下: MySQL中GROUP BY分组取前N条记录实现 mysql分组,取记录 GROUP BY之后如何取每组的前两位下面我来讲述mysql中GROUP BY分组取前N条记录实现方法. 这是测试表(也不知道怎么想的,当时表名直接敲了个aa,汗~~~~): 结果: 方法一: 复制代码 代码如下: SELECT a.id,a.SName,a.ClsNo,a.Score FROM aa a LEFT J
-
MySQL高级查询之与Group By集合使用介绍
1 GROUP_CONCAT mysql> SELECT student_name, -> GROUP_CONCAT(test_score) -> FROM student -> GROUP BY student_name; Or: mysql> SELECT student_name, -> GROUP_CONCAT(DISTINCT test_score -> ORDER
-
Mysql中错误使用SQL语句Groupby被兼容的情况
首先创建数据库hncu,建立stud表格. 添加数据: create table stud( sno varchar(30) not null primary key, sname varchar(30) not null, age int, saddress varchar(30) ); INSERT INTO stud VALUES('1001','Tom',22,'湖南益阳'); INSERT INTO stud VALUES('1002','Jack',23,'益阳'); INSERT
-
浅谈sql语句中GROUP BY 和 HAVING的使用方法
在介绍GROUP BY 和 HAVING 子句前,我们必需先讲讲sql语言中一种特殊的函数:聚合函数, 例如SUM, COUNT, MAX, AVG等.这些函数和其它函数的根本区别就是它们一般作用在多条记录上. SELECT SUM(population) FROM bbc 这里的SUM作用在所有返回记录的population字段上,结果就是该查询只返回一个结果,即所有 国家的总人口数. having是分组(group by)后的筛选条件,分组后的数据组内再筛选 where则是在分组前筛选 通过
-
详解SQL中Group By的使用教程
1.概述 "Group By"从字面意义上理解就是根据"By"指定的规则对数据进行分组,所谓的分组就是将一个"数据集"划分成若干个"小区域",然后针对若干个"小区域"进行数据处理. 2.原始表 3.简单Group By示例1 select 类别, sum(数量) as 数量之和from Agroup by 类别 返回结果如下表,实际上就是分类汇总. 4.Group By 和 Order By示例2 sele
-
详解SQL中Group By的用法
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组. 1.概述 "Group By"从字面意义上理解就是根据"By"指定的规则对数据进行分组,所谓的分组就是将一个"数据集"划分成若干个"小区域",然后针对若干个"小区域"进行数据处理. 2.原始表 3.简单Group By 示例1 select 类别, sum(数量) as 数量之和 from A group by 类别 返回结果如下表
-
一文详解SQL 中的三值逻辑
目录 1. 前言 2. 两种 Null 3. 为什么是 is Null 而不是 = Null ? 4. 第三个真值 “unknown” 5. 包含三值逻辑的真值表 6. “排中律” 不再成立 7. CASE 表达式和 NULL 8. NOT IN 和 NOT EXISTS 不是等价的 9. 限定谓词和 NULL 10. 限定谓词和极值函数不是等价的 11. 聚合函数和 Null 1. 前言 大多数编程语言都是基于二值逻辑的,即逻辑真值只有真和假两个.而 SQL 语言则采用一种特别的逻辑体系——三
-
带例子详解Sql中Union和Union ALL的区别
目录 前言 提前准备 测试 Union Union ALL Union Union All union Union All 最后 前言 一段时间没有用Union和Union,再用的时候忘了怎么用了...所以做一篇文章来记录自己学Union和Union的经历. 提前准备 在Sql Server 创建两张表,下面是创建表sql语句. create table Student1( Id varchar(50) not null, Name varchar(50) not null, Age int n
-
详解sql中的参照完整性(一对一,一对多,多对多)
一.参照完整性 参照完整性指的就是多表之间的设计,主要使用外键约束. 多表设计: 一对多.多对多.一对一设计 1.一对多 关联主要语句: constraint cus_ord_fk foreign key (customer_id) REFERENCES customer(id) 创建客户表--订单表 一个客户可以订多份订单,每份订单只能有一个客户. -- 关联(1对N) create table customer( id int PRIMARY KEY auto_increment, name
-
详解SQL中的DQL查询语言
DQL DQL:data Query language 数据查询语言 格式:select[distinct] 字段1,字段2 from 表名 where 控制条件 (distinct: 显示结果时,是否去除重复列 给哪一列去重就在哪一列字段前加入distinct) 学生表 (1)查询表中的所有信息 SELECT * FROM student (2)查询表中的所有学生姓名和对应的英语成绩 SELECT name,english FROM student 注:可显示部分字段,如果显示哪列数据,就直接
-
详解sql中exists和in的语法与区别
exists和in的区别很小,几乎可以等价,但是sql优化中往往会注重效率问题,今天咱们就来说说exists和in的区别. exists语法: select - from table where exists (子查询) 将主查询的结果,放到子查询结果中进行校验,如子查询有数据,则校验成功,那么符合校验,保留数据. create table teacher ( tid int(3), tname varchar(20), tcid int(3) ); insert into teacher va
-
详解Unity中的ShaderGraph入门使用教程
一,ShaderGraph 简介 简介: Unity2018版本之后推出了一个可编程渲染管线工具ShaderGraph,让我们可以通过可视化界面拖拽来实现着色器的创建和编辑. 官方话术: Shader Graph 使您能够直观地构建着色器.您无需编写代码,而是在图形框架中创建和连接节点.Shader Graph 提供反映您的更改的即时反馈,并且对于不熟悉着色器创建的用户来说非常简单. Shader Graph 仅与可编写脚本的渲染管线 (SRP) 兼容,即高清晰度渲染管线 (HDRP) 和通用渲
-
详解Vue3中setup函数的使用教程
目录 vue2 和 vue3 开发的区别 使用 setup 原因 setup 用法 setup 可以接受哪些参数 setup 详解 setup 函数自动执行 setup 函数定义变量 setup 创建方法 动态更新数据 vue2 和 vue3 开发的区别 首先,目前来说 vue3 发布已经有一段时间了,但是呢,由于还处于优化完善阶段,对于 vue3 开发项目的需求不是很高,主要还是以 vue2 开发为主,但是相信,vue3 进行项目开发是大势所趋. vue2 开发项目过程中,会存在代码冗余和结构
-
详解Python3中setuptools、Pip安装教程
1.安装setuptools 命令如下: wget --no-check-certificate https://pypi.python.org/packages/source/s/setuptools/setuptools-19.6.tar.gz#md5=c607dd118eae682c44ed146367a17e26 tar -zxvf setuptools-19.6.tar.gz cd setuptools-19.6 python3 setup.py build python3 setup