Python Dataframe常见索引方式详解
创建一个示例数据框:
import pandas as pd
df = pd.DataFrame([['乔峰', '男', 95, '降龙十八掌', '主角'],
['虚竹', '男', 93, '天上六阳掌', '主角'],
['段誉', '男', 92, '六脉神剑', '主角'],
['王语嫣', '女', 95,'熟知武诀', '主角'],
['包不同', '男', 65, '胡搅蛮缠', '配角'],
['康敏', '女', 40, '惑夫妒人', '配角']],
index=list('abcdef'.upper()),
columns=['name', 'gender', 'score', 'skill', 'class'])
df
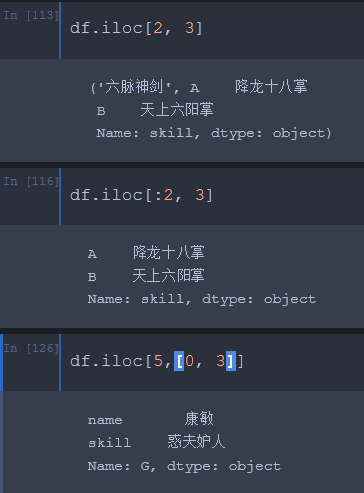
1、iloc[] # 列表取值方式索引器,只接受从 0 开始整数
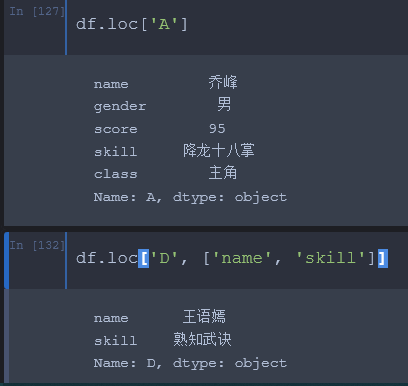
2.loc[] # 字典取值方式的索引器,只接受 index 和 columns 的值
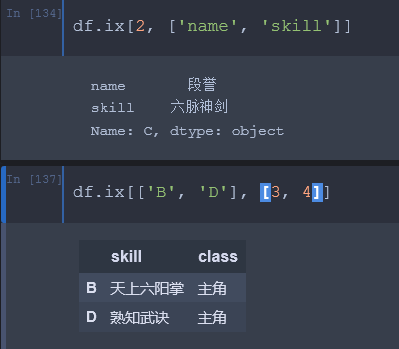
3、ix[] # 混合了 iloc 和 loc 的用法,整数和值都接受
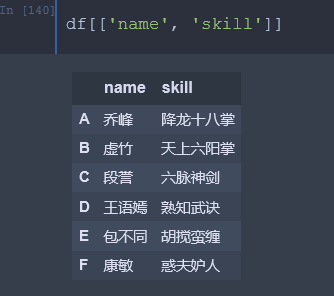
4、[[]] # R语言 中的双中括号索引方式
5、字典形式索引列
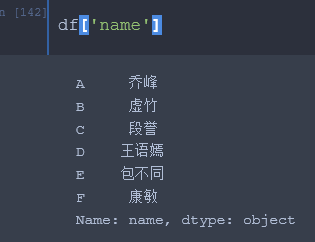
6、属性形式索引列(列名称不是整数)
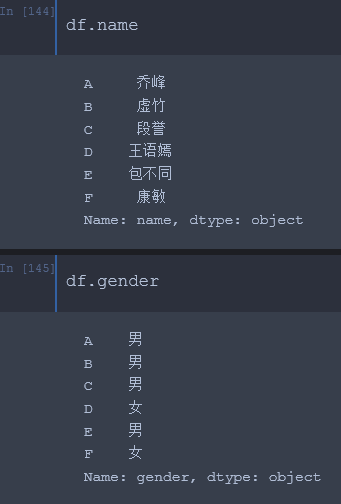
还有些切片、花哨索引、布尔掩码都先对简单,且都能在以上方式中应用,私以为不应单独列出。
pandas 的很多形式跟 R语言很是相似,颇值得玩味!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python DataFrame 设置输出不显示index(索引)值的方法
在输出代码行中,加入"index=False"如下: m_pred_survived.to_csv("clasified.csv",index=False) 以上这篇Python DataFrame 设置输出不显示index(索引)值的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python pandas.DataFrame.loc函数使用详解
官方函数 DataFrame.loc Access a group of rows and columns by label(s) or a boolean array. .loc[] is primarily label based, but may also be used with a boolean array. # 可以使用label值,但是也可以使用布尔值 Allowed inputs are: # 可以接受单个的label,多个label的列表,多个label的切片 A singl
-
python 怎样将dataframe中的字符串日期转化为日期的方法
方法一:也是最简单的 直接使用pd.to_datetime函数实现 data['交易时间'] = pd.to_datetime(data['交易时间']) 方法二: 源自利用python进行数据分析P304 使用python的datetime包中的 strptime函数,datetime.strptime(value,'%Y/%M/%D') strftime函数,datetime.strftime('%Y/%M/%D') 注意使用datetime包中后面的字符串匹配需要和原字符串的格式相同,才能
-
python中pandas.DataFrame的简单操作方法(创建、索引、增添与删除)
前言 最近在网上搜了许多关于pandas.DataFrame的操作说明,都是一些基础的操作,但是这些操作组合起来还是比较费时间去正确操作DataFrame,花了我挺长时间去调整BUG的.我在这里做一些总结,方便你我他.感兴趣的朋友们一起来看看吧. 一.创建DataFrame的简单操作: 1.根据字典创造: In [1]: import pandas as pd In [3]: aa={'one':[1,2,3],'two':[2,3,4],'three':[3,4,5]} In [4]: bb=
-
在Python中pandas.DataFrame重置索引名称的实例
例子: 创建DataFrame ### 导入模块 import numpy as np import pandas as pd import matplotlib.pyplot as plt test = pd.DataFrame({'a':[11,22,33],'b':[44,55,66]}) """ a b 0 11 44 1 22 55 2 33 66 """ 更改列名方法一:rename test.rename(columns={'a':
-
python DataFrame获取行数、列数、索引及第几行第几列的值方法
1.df=DataFrame([{'A':'11','B':'12'},{'A':'111','B':'121'},{'A':'1111','B':'1211'}]) print df.columns.size#列数 2 print df.iloc[:,0].size#行数 3 print df.ix[[0]].index.values[0]#索引值 0 print df.ix[[0]].values[0][0]#第一行第一列的值 11 print df.ix[[1]].values[0][1]
-
python pandas 对series和dataframe的重置索引reindex方法
reindex更多的不是修改pandas对象的索引,而只是修改索引的顺序,如果修改的索引不存在就会使用默认的None代替此行.且不会修改原数组,要修改需要使用赋值语句. series.reindex() import pandas as pd import numpy as np obj = pd.Series(range(4), index=['d', 'b', 'a', 'c']) print obj d 0 b 1 a 2 c 3 dtype: int64 print obj.reinde
-
Python Dataframe常见索引方式详解
创建一个示例数据框: import pandas as pd df = pd.DataFrame([['乔峰', '男', 95, '降龙十八掌', '主角'], ['虚竹', '男', 93, '天上六阳掌', '主角'], ['段誉', '男', 92, '六脉神剑', '主角'], ['王语嫣', '女', 95,'熟知武诀', '主角'], ['包不同', '男', 65, '胡搅蛮缠', '配角'], ['康敏', '女', 40, '惑夫妒人', '配角']], index=list
-
关于python 跨域处理方式详解
因为浏览器的同源策略限制,不是同源的脚本不能操作其他源下面的资源,想操作另一个源下面的资源就属于跨域了,这里说的跨域是广义跨域,我们常说的代码中请求跨域,是狭义的跨域,即在脚本代码中向非同源域发送http请求 浏览器的同源策略(SOP/same origin policy)是浏览器最核心也最基本的安全功能,如果缺少了同源策略,浏览器很容易受到XSS(跨站脚本攻击 cross site scripting)和CSRF(跨站请求伪造cross-site request forgery)等攻击. (同
-
PHP守护进程的两种常见实现方式详解
本文实例讲述了PHP守护进程的两种常见实现方式.分享给大家供大家参考,具体如下: 第一种方式,借助 nohup 和 & 配合使用. 在命令后面加上 & 符号, 可以让启动的进程转到后台运行,而不占用控制台,控制台还可以再运行其他命令,这里我使用一个while死循环来做演示,代码如下 <?php while(true){ echo time().PHP_EOL; sleep(3); } 用 & 方式来启动该进程 [root@localhost php]# php deadlo
-

Python实现最常见加密方式详解
前言 我们所说的加密方式,都是对二进制编码的格式进行加密的,对应到Python中,则是我们的Bytes. 所以当我们在Python中进行加密操作的时候,要确保我们操作的是Bytes,否则就会报错. 将字符串和Bytes互相转换可以使用encode()和decode()方法.如下所示: # 方法中不传参数则是以默认的utf-8编码进行转换In [1]: '南北'.encode()Out[1]: b'\xe5\x8d\x97\xe5\x8c\x97'In [2]: b'\xe5\x8d\x97\xe
-
Vue2几种常见开局方式详解
在SF问题中看到了一个关于vue-cli中的template问题,问题是这样的: 用vue-cli工具生成的main.js中: import Vue from 'vue' import App from './App' import router from './router' Vue.config.productionTip = false /* eslint-disable no-new */ new Vue({ el: '#app', router, template: '<App/>'
-
python tkinter组件摆放方式详解
1.最小界面组成 # 导入tkinter模块 import tkinter # 创建主窗口对象 root = tkinter.Tk() # 设置窗口大小(最小值:像素) root.minsize(300,300) # 创建一个按钮组件 btn = tkinter.Button(root,text = '屠龙宝刀,点击送') btn.pack() # 加入消息循环 root.mainloop() 设置初始化界面大小 # 设置初始化界面大小 root.geometry('300x400') 2.组件
-
python 代码运行时间获取方式详解
我们知道为了提高代码的运行速度,我们需要对书写的python代码进行性能测试,而代码性能的高低的直接反馈是电脑运行代码所需要的时间.这里将介绍四种常用的测试代码运行速度的方法. 第一种:使用time模块对代码的运行时间进行统计,代码如下: import time class Debug: def mainProgram(self): start_time = time.time() for i in range(100): print(i) end_time = time.time() prin
-
python简单爬虫--get方式详解
目录 环境准备 进行爬虫 参考 总结 简单爬虫可以划分为get.post格式.其中,get是单方面的获取资源,而post存在交互,如翻译中需要文字输入.本文主要描述简单的get爬虫. 环境准备 安装第三方库 pip install requests pip install bs4 pip install lxml 进行爬虫 1.获取网页数据. import requests from bs4 import BeautifulSoup url = "https://cn.bing.com/sear
-
Python OpenCV特征检测之特征匹配方式详解
目录 前言 一.暴力匹配器 二.FLANN匹配器 前言 获得图像的关键点后,可通过计算得到关键点的描述符.关键点描述符可用于图像的特征匹配.通常,在计算图A是否包含图B的特征区域时,将图A称做训练图像,将图B称为查询图像.图A的关键点描述符称为训练描述符,图B的关键点描述符称为查询描述符. 一.暴力匹配器 暴力匹配器使用描述符进行特征比较.在比较时,暴力匹配器首先在查询描述符中取一个关键点的描述符,将其与训练描述符中的所有关键点描述符进行比较,每次比较后会给出一个距离值,距离最小的值对应最佳