Python 分布式缓存之Reids数据类型操作详解
1、Redis API
1.安装redis模块
$ pip3.8 install redis
2.使用redis模块
import redis # 连接redis的ip地址/主机名,port,password=None r = redis.Redis(host="127.0.0.1",port=6379,password="gs123456")
3.redis连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
总之,当程序创建数据源实例时,系统会一次性创建多个数据库连接,并把这些数据库连接保存在连接池中,当程序需要进行数据库访问时,无需重新新建数据库连接,而是从连接池中取出一个空闲的数据库连接
import redis # 创建连接池,将连接保存在连接池中 pool = redis.ConnectionPool(host="127.0.0.1",port=6379,password="gs123456",max_connections=10) # 创建一个redis实例,并使用连接池"pool" r = redis.Redis(connection_pool=pool)
2、String 操作
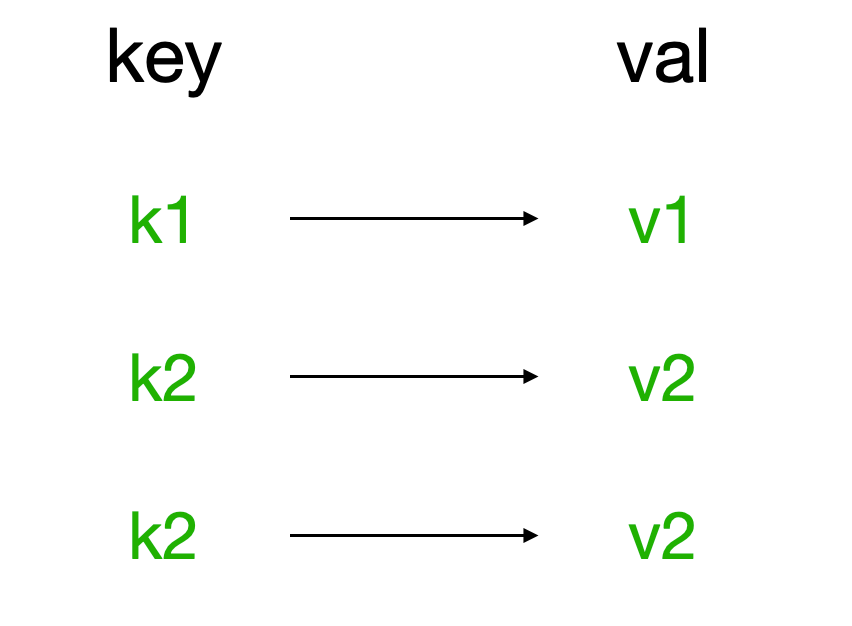
redis中的String在内存中按照一个name对应一个value来存储。如图:
1. set 为name设置值
# 在Redis中设置值,默认,不存在则创建,存在则修改 set(name, value, ex=None, px=None, nx=False, xx=False, keepttl=False) name:设置键 value:设置值 ex:设置过期时间(秒级) px:设置过期时间(毫秒) nx:如果设置为True,则只有name不存在时,当前set操作才执行,同setnx(name, value) xx:如果设置为True,则只有name存在时,当前set操作才执行
set用法:
r.set("name1","jack",ex=3600)
r.set("name2","xander",xx=36000)
setnx用法:
# 设置值,只有name不存在时,执行设置操作(添加) setnx(name, value)
setex用法:
# 设置值,参数:time -->过期时间(数字秒 或 timedelta对象) setex(name, value, time)
psetex用法:
# 设置值,参数:time_ms,过期时间(数字毫秒 或 timedelta对象) psetex(name, time_ms, value)
2. get 获取name的值
# 根据key获取值
get(name)
r.get("foo")
3. mset 批量设置name的值:
mset(mapping)
data = {
"k1":"v1",
"k2":"v2",
}
r.mset(data)
4. Mget 批量获取name的值
# 批量获取值,根据多key获取多个值
mgets(mapping)
# 方法一
r.mget("k1","k2")
# 方法二
data = ["k1","k2"]
r.mget(data)
# 方法三
data = ("k1","k2")
r.mget(data)
5. getset 设置新值并获取原来的值
getset(name, value)
r.set("foo", "xoo")
ret = r.getset("foo", "yoo")
print(ret) # b'xoo'
6. append 为name原有值后追加内容
# key对应值的后面追加内容
append(key, value)
r.set("name","jack")
r.append("name","-m")
ret = r.get("name")
print(ret) # b'jack-m'
7. strlen 返回name的值字节长度:
# 返回字符串的长度,当name不存在时返回0
strlen(name)
r.set("name","jack-")
ret = r.strlen("name")
print(ret) # 5
8. incr 为name整数累加值
# 自增mount对应的值,当mount不存在时,则创建mount=amount,否则,则自增,amount为自增数(整数)
incr(name, amount=1)
r.incr('mount')
r.incr('mount')
r.incr('mount', amount=3)
ret = r.get('mount')
print(ret) # b'5'
3、Hash 操作
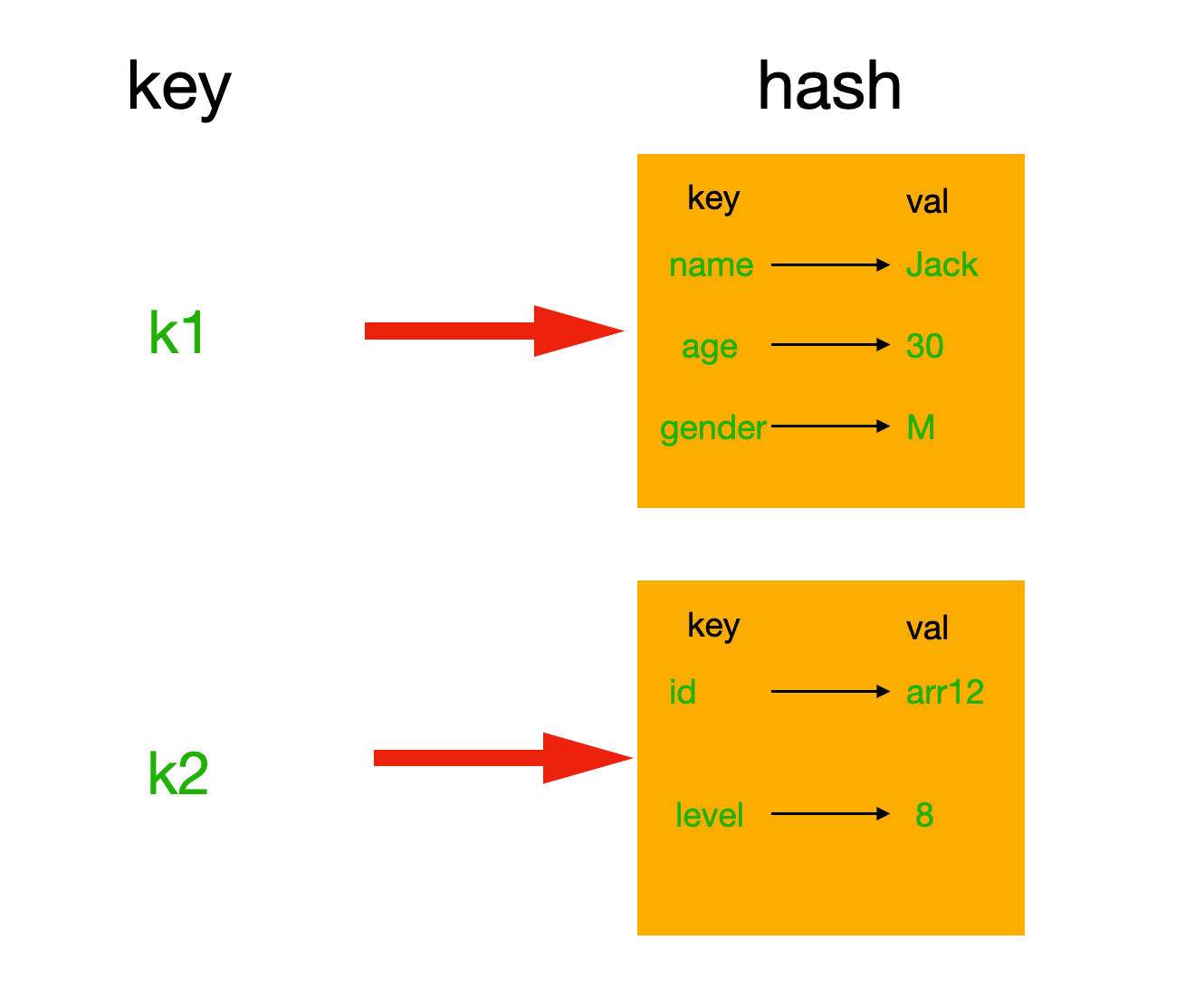
hash表现形式上有些像pyhton中的dict,可以存储一组关联性较强的数据 ,redis中Hash在内存中的存储格式如下图:
1. hset 为name设置单个键值对
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改) hset(name, key, value) name:设置name key:name对应hash中的key(键) value:name对应的hash中的value(值)
hset用法
# 一次只能设置一个键值对
r.hset("student-jack", "name", "Jack")
2 . hget 获取name单个键值对
# 根据name对应的hash中获取根据key获取value
hget(name,key)
ret = r.hget("student-jack", "name")
print(ret) // b'Jack'
3. hmset 为name设置多个键值对
# mapping中传入字典(不存在,则创建;否则,修改)
hmset(name, mapping):
data = {
"name": "Jack",
"age": 20,
"gender": "M",
}
r.hmset("student-jack", mapping=data)
4. hmget 获取name多个键值对
# 根据name对应的hash中获取多个key的值
hmget(name, keys, *args)
name:指定name
keys:要获取key集合,如:['k1', 'k2', 'k3']
*args:要获取的key,如:k1,k2,k3
# 直接传入需要获取的键
ret = r.hmget("student-jack", "name", "age")
print(ret) # [b'Jack', b'20']
# 列表中指定需要获取的键
data = ["name", "age"]
ret = r.hmget("student-jack", data)
print(ret) # [b'Jack', b'20']
5. hgetall 获取name的键值对
# 根据name获取hash的所有值
hgetall(name)
ret = r.hgetall("student-jack")
print(ret) # {b'name': b'Jack', b'age': b'20', b'gender': b'M'}
6、hlen 获取name中的键值对个数
# 根据name获取hash中键值对的总个数
hlen(name)
ret = r.hlen("student-jack")
print(ret) # 3 , 3个键值对
7. hkeys 获取name中键值对所有key
# 获取name里键值对的key
hkeys(name)
ret = r.hkeys('student-jack')
print(ret) # [b'name', b'age', b'gender']
8. hvals 获取name中键值对所有value
# 获取name里键值对的value
hvals(name)
ret = r.hvals('student-jack')
print(ret) # [b'Jack', b'20', b'M']
9. hkeys 检查name里的键值对是否有对应的key
# 根据name检查对应的hash是否存在当前传入的key
hexists(name, key)
# 返回布尔值
ret = r.hexists('student-jack', 'name')
print(ret) # True
10. hincrby 从name里的键值对设置自增值
1.整数自增:
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
hincrby(name, key, amount=1)
name:设置键
key:hash对应的key
amount:自增数(整数)
ret = r.hincrby('student-jack', 'age')
ret = r.hincrby('student-jack', 'age')
print(ret) # 22
2.浮点自增
# 自增name对应的hash中的指定key的值,不存在则创建key=amount hincrbyfloat(name, key, amount=1.0) name:设置键 key:hash对应的key amount:自增数(浮点数)
11. hdel 根据name从键值对中删除指定key
# 根据name将对应hash中指定的key键值对删除
hdel(name,*keys)
r.hdel("info",*("m-k1","m-k2"))
4、List 操作
List操作,redis中的List在内存中按照一个name对应一个List来存储。如图:

1. lpush 为name添加元素,每个新的元素都添加到列表的最左边
# name对应的list中添加元素
lpush(name,values)
# 直接指定多个元素
r.lpush("names", "Jack", "Alex", "Eric")
# 将需要添加的元素添加到元组
data = ("Jack", "Alex", "Eric")
r.rpush("names", *data)
# 将需要添加的元素添加到列表
data = ["Jack", "Alex", "Eric"]
r.rpush("names", *data)
Note:列表类型中的值统称元素
2. rpush 为name添加元素,每个新的元素都添加到列表的最右边
# 同lpush,但每个新的元素都会添加到列表的最右边 rpush(name, values)
3. lpushx 为name添加元素,只有当name已存在时,将元素添加至列表最左边
lpushx(name,value)
4. rpushx 同上,将元素添加至列表最右边
rpushx(name, values)
5. llen 统计name中list的元素个数
# name对应的list元素的个数
llen(name)
ret = r.llen('names')
print(ret) # 3, 该list中有3个元素
6. linsert 为name中list的某一个值或后 插入一个新的值
# 在name对应的列表的某一个值前或后插入一个新值
linsert(name, where, refvalue, value)
name:设置name
where:BEFORE或AFTER
refvalue:标杆值,即:在它前后插入数据
value:要插入的数据
// 在Alex值前插入一个值(BEFORE表示:在...之前)
r.linsert('names', 'BEFORE', 'Jack', 'Jason')
// 在Jack后插入一个值(AFTER表示:在...之后)
r.linsert('names', 'AFTER', 'Jack', 'Xander')
7. lset 为name中list的某一个索引位置的元素重新赋值
# 对name对应的list中的某一个索引位置重新赋值
lset(name, index, value)
name:设置name
index:list的索引位置
value:要设置的值
// 将索引为1的元素修改为Gigi
r.lset('names', 1, 'Gigi')
8. lrem 移除name里对应list的元素
# 在name对应的list中删除指定的值
lrem(name, count, value)
name:设置name
value:要删除的值
count:count=0,删除列表中的指定值;
count=2,从前到后,删除2个;
count=-2,从后向前,删除2个
r.lrem('names', count=2, value='Xander')
9. lpop 从name里的list获取最左侧的第一个元素,并在列表中移除,返回值是则是第一个元素
lpop(name)
ret = r.lpop('names')
print(ret) # b'Jason'
10. rpop 同上,从右侧获取第一个元素
rpop(name)
11. lindex 在name对应的列表 根据索引获取元素
# 在name对应的列表中根据索引获取列表元素
lindex(name, index)
ret = r.lindex('names', 0)
print(ret) # b'Gigi'
12. ltrim 移除列表内没有在该索引之内的值(截断)
# 移除列表内没有在该索引之内的值
ltrim(name, start, end)
r.ltrim("names",0,2)
13. lrange 在name对应的列表 根据索引获取数据
# 在name对应的列表分片获取数据
lrange(name, start, end)
name:设置name
start:索引的起始位置
end:索引结束位置
// 先添加点元素
data = ['Jack', 'Eric', 'Koko', 'Jason', 'Alie']
r.rpush('names', *data)
// 获取列表所有元素
ret = r.lrange('names', 0, -1)
print(ret) # [b'Gigi', b'Alex', b'Jack', b'Eric', b'Koko', b'Jason', b'Alie']
// 获取列表索引2-5的元素(包含2和5,即 2 3 4 5)
ret = r.lrange('names', 2, 5)
print(ret) # [b'Jack', b'Eric', b'Koko', b'Jason']
// 获取列表的最后一个元素
ret = r.lrange('names', -1, -1)
print(ret) # [b'Alie']
到此这篇关于Python 分布式缓存之Reids数据类型操作详解的文章就介绍到这了,更多相关Python Reids数据类型操作内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python中的不可变数据类型与可变数据类型详解
前言 python与C/C++不一样,它的变量使用有自己的特点,当初学python的时候,一定要记住"一切皆为对象,一切皆为对象的引用"这句话,其实这个特点类似于JAVA,所以在python里面大家也不用担心类似于C/C++中的指针的复杂问题, 在python中数据分为可变数据类型,不可变数据类型. 所以在学习python过程中我们一定会遇到不可变数据类型和可变数据类型.下面话不多说了,来一起看看详细的介绍吧 1.名词解释 以下所有的内容都是基于内存地址来说的. 不可变数据类型: 当该
-
浅谈Python数据类型之间的转换
Python数据类型之间的转换 函数 描述 int(x [,base]) 将x转换为一个整数 long(x [,base] ) 将x转换为一个长整数 float(x) 将x转换到一个浮点数 complex(real [,imag]) 创建一个复数 str(x) 将对象 x 转换为字符串 repr(x) 将对象 x 转换为表达式字符串 eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象 tuple(s) 将序列 s 转换为一个元组 list(s) 将序列 s 转换为一个
-
浅谈python数据类型及类型转换
Python中核心的数据类型有哪些? 变量(数字.字符串.元组.列表.字典) 什么是数据的不可变性?哪些数据类型具有不可变性 数据的不可变是指数据不可更改,比如: a = ("abc",123) #定义元组 a[0]=234 #把第一位更改为345 print(a) #打印时会报错 不可变:数字.字符.元组 可变:列表和字典 Python中常见数据类型 赋值 counter = 100 miles = 1000 name = "nan" print(counter,
-
Python基本数据类型详细介绍
1.空(None)表示该值是一个空对象,空值是Python里一个特殊的值,用None表示.None不能理解为0,因为0是有意义的,而None是一个特殊的空值.2.布尔类型(Boolean)在Python中,None.任何数值类型中的0.空字符串"".空元组().空列表[].空字典{}都被当作False,还有自定义类型,如果实现了__nonzero__()或__len__()方法且方法返回0或False,则其实例也被当作False,其他对象均为True布尔值和布尔代数的表示完全一致,一个
-
python基础教程之基本数据类型和变量声明介绍
变量不需要声明 Python的变量不需要声明,你可以直接输入: 复制代码 代码如下: >>>a = 10 那么你的内存里就有了一个变量a, 它的值是10,它的类型是integer (整数). 在此之前你不需要做什么特别的声明,而数据类型是Python自动决定的. 复制代码 代码如下: >>>print a >>>print type(a) 那么会有如下输出: 复制代码 代码如下: 10 <type 'int'> 这里,我们学到一个内置函数t
-
常用python数据类型转换函数总结
1.chr(i)chr()函数返回ASCII码对应的字符串. 复制代码 代码如下: >>> print chr(65)A>>> print chr(66) >>> print chr(65)+chr(66)AB 2.complex(real[,imaginary])complex()函数可把字符串或数字转换为复数. 复制代码 代码如下: >>> complex("2+1j")(2+1j)>>> c
-
Python最基本的数据类型以及对元组的介绍
简单类型 内置到 Python 编程语言中的简单数据类型包括: bool int float complex 支持简单数据类型不是 Python 独有的功能,因为多数现代编程语言都具有完整类型补充.例如 Java? 语言甚至有一组更丰富的原始数据类型: byte short int long float double char boolean 但是,在 Python 中,简单数据类型并不是原始数据类型,而是完善的对象
-
一篇文章弄懂Python中所有数组数据类型
前言 数组类型是各种编程语言中基本的数组结构了,本文来盘点下Python中各种"数组"类型的实现. list tuple array.array str bytes bytearray 其实把以上类型都说成是数组是不准确的.这里把数组当作一个广义的概念,即把列表.序列.数组都当作array-like数据类型来理解. 注意本文所有代码都是在Python3.7中跑的^_^ 0x00 可变的动态列表list list应该是Python最常用到的数组类型了.它的特点是可变的.能动态扩容,可存储
-
Python 分布式缓存之Reids数据类型操作详解
1.Redis API 1.安装redis模块 $ pip3.8 install redis 2.使用redis模块 import redis # 连接redis的ip地址/主机名,port,password=None r = redis.Redis(host="127.0.0.1",port=6379,password="gs123456") 3.redis连接池 redis-py使用connection pool来管理对一个redis server的所有连接,避
-

Python必备技巧之字符数据操作详解
目录 字符串操作 字符串 + 运算符 字符串 * 运算符 字符串 in 运算符 内置字符串函数 字符串索引 字符串切片 字符串切片中的步幅 将变量插入字符串 修改字符串 内置字符串方法 bytes对象 定义文字bytes对象 bytes使用内置bytes()函数定义对象 bytes对象操作,操作参考字符串. bytearray对象,Python 支持的另一种二进制序列类型 字符串操作 字符串 + 运算符 +运算符用于连接字符串,返回一个由连接在一起的操作数组成的字符串. >>> s =
-
Node.js基础入门之缓存区与文件操作详解
目录 缓存区 1. 什么是缓存区? 2. 创建指定长度的缓存区 3. 通过数组创建缓存区 4. 通过字符串创建缓存区 5. 读写缓存区 6. 复制缓存区 文件操作 1. 异步直接读取 2. 同步直接读取 3. 流式读取 4. 写入文件 5. 流式写入文件 6. 读取文件信息 7. 删除文件 8. 管道 9. 链式流 经过前面三天的学习,Node.js的基础知识已逐渐掌握,今天继续学习缓存区和文件操作,并稍加整理加以分享,如有不足之处,还请指正. 缓存区 1. 什么是缓存区? JavaScript
-
MySQL操作之JSON数据类型操作详解
上一篇文章我们介绍了mysql数据存储过程参数实例详解,今天我们看看MySQL操作之JSON数据类型的相关内容. 概述 mysql自5.7.8版本开始,就支持了json结构的数据存储和查询,这表明了mysql也在不断的学习和增加nosql数据库的有点.但mysql毕竟是关系型数据库,在处理json这种非结构化的数据时,还是比较别扭的. 创建一个JSON字段的表 首先先创建一个表,这个表包含一个json格式的字段: CREATE TABLE table_name ( id INT NOT NULL
-
对python for 文件指定行读写操作详解
1.os.mknod("test.txt") #创建空文件 2.fp = open("test.txt",w) #直接打开一个文件,如果文件不存在则创建文件 3.关于open 模式: 详情: w:以写方式打开, a:以追加模式打开 (从 EOF 开始, 必要时创建新文件) r+:以读写模式打开 w+:以读写模式打开 (参见 w ) a+:以读写模式打开 (参见 a ) rb:以二进制读模式打开 wb:以二进制写模式打开 (参见 w ) ab:以二进制追加模式打开 (
-
基于Python对数据shape的常见操作详解
这一阵在用python做DRL建模的时候,尤其是在配合使用tensorflow的时候,加上tensorflow是先搭框架再跑数据,所以调试起来很不方便,经常遇到输入数据或者中间数据shape的类型不统一,导致一些op老是报错.而且由于水平菜,所以一些常用的数据shape转换操作也经常百度了还是忘,所以想再整理一下. 一.数据的基本属性 求一组数据的长度 a = [1,2,3,4,5,6,7,8,9,10,11,12] print(len(a)) print(np.size(a)) 求一组数据的s
-
python分布式爬虫中消息队列知识点详解
当排队等待人数过多的时候,我们需要设置一个等待区防止秩序混乱,同时再有新来的想要排队也可以呆在这个地方.那么在python分布式爬虫中,消息队列就相当于这样的一个区域,爬虫要进入这个区域找寻自己想要的资源,当然这个是一定的次序的,不然数据获取就会出现重复.就下来我们就python分布式爬虫中的消息队列进行详细解释,小伙伴们可以进一步了解一下. 实现分布式爬取的关键是消息队列,这个问题以消费端为视角更容易理解.你的爬虫程序部署到很多台机器上,那么他们怎么知道自己要爬什么呢?总要有一个地方存储了他们
-
Python实现日期判断和加减操作详解
python实现日期判断和加减操作 #==================================================== #时间相关 #==================================================== def if_workday(day_str, separator=""): """ if a day is workday :param day_str: string of a day :pa
-
Python+Selenium键盘鼠标模拟事件操作详解
目录 元素的基本操作 鼠标键盘模拟事件操作 利用 Keys 模块模拟键盘操作事件 利用 Action 类模拟鼠标操作事件 当我们定位到具体的一个元素的时候就可以对这个元素进行具体的操作,比如之前章节所执行的 click 操作.这是最简单的操作,webdriver 还有其他的操作.比如元素的基本操作(点击.输入.清除),还有一些高级操作如鼠标键盘模拟事件.弹出框处理.多页面切换等… 这些都是需要我们了解的内容,也是在做自动化测试的时候经常遇到的一些基本场景.今天这一章节,我们就先来学习一下元素的基
-
Python Numpy中数组的集合操作详解
我们知道两个 set 对象之间,可以取交集.并集.差集.对称差集,举个例子: s1 = {1, 2, 3} s2 = {2, 3, 4} """ &: 交集 |: 并集 -: 差集 ^: 对称差集 """ # 以下几种方式是等价的 # 但是一般我们都会使用操作符来进行处理,因为比较方便 print(s1 & s1) print(s1.intersection(s2)) print(set.intersection(s1, s2)