Keras在训练期间可视化训练误差和测试误差实例
详细的解释,读者自行打开这个链接查看,我这里只把最重要的说下
fit() 方法会返回一个训练期间历史数据记录对象,包含 training error, training accuracy, validation error, validation accuracy 字段,如下打印
# list all data in history
print(history.history.keys())
完整代码
# Visualize training history
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
import numpy
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load pima indians dataset
dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# split into input (X) and output (Y) variables
X = dataset[:,0:8]
Y = dataset[:,8]
# create model
model = Sequential()
model.add(Dense(12, input_dim=8, kernel_initializer='uniform', activation='relu'))
model.add(Dense(8, kernel_initializer='uniform', activation='relu'))
model.add(Dense(1, kernel_initializer='uniform', activation='sigmoid'))
# Compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
history = model.fit(X, Y, validation_split=0.33, epochs=150, batch_size=10, verbose=0)
# list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
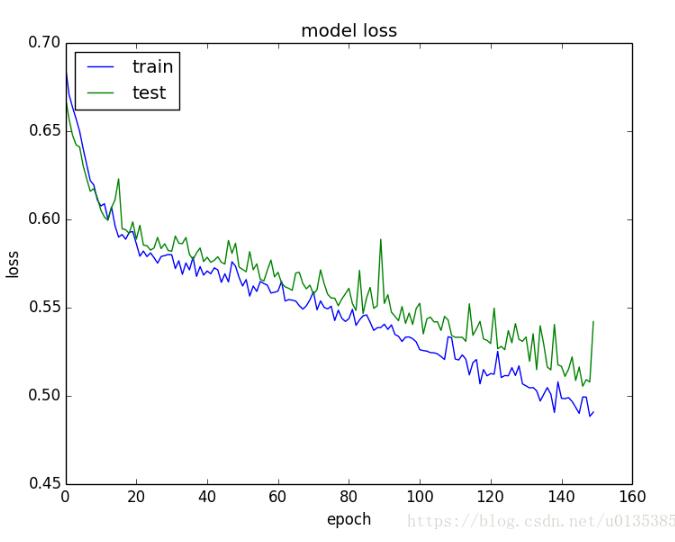
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
补充知识:训练时同时输出实时cost、准确率图
首先定义画图函数:
train_prompt = "Train cost" cost_ploter = Ploter(train_prompt) def event_handler_plot(ploter_title, step, cost): cost_ploter.append(ploter_title, step, cost) cost_ploter.plot()
在训练时如下方式使用:
EPOCH_NUM = 8
# 开始训练
lists = []
step = 0
for epochs in range(EPOCH_NUM):
# 开始训练
for batch_id, train_data in enumerate(train_reader()): #遍历train_reader的迭代器,并为数据加上索引batch_id
train_cost,sult,lab,vgg = exe.run(program=main_program, #运行主程序
feed=feeder.feed(train_data), #喂入一个batch的数据
fetch_list=[avg_cost,predict,label,VGG]) #fetch均方误差和准确率
if step % 10 == 0:
event_handler_plot(train_prompt,step,train_cost[0])
# print(batch_id)
if batch_id % 10 == 0: #每100次batch打印一次训练、进行一次测试
p = [np.sum(pre) for pre in sult]
l = [np.sum(pre) for pre in lab]
print(p,l,np.sum(sult),np.sum(lab))
print('Pass:%d, Batch:%d, Cost:%0.5f' % (epochs, batch_id, train_cost[0]))
step += 1
# 保存模型
if model_save_dir is not None:
fluid.io.save_inference_model(model_save_dir, ['images'], [predict], exe)
print('训练模型保存完成!')
end = time.time()
print(time.strftime('V100训练用时:%M分%S秒',time.localtime(end-start)))
实时显示准确率用同样的方法
以上这篇Keras在训练期间可视化训练误差和测试误差实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
keras 自定义loss损失函数,sample在loss上的加权和metric详解
首先辨析一下概念: 1. loss是整体网络进行优化的目标, 是需要参与到优化运算,更新权值W的过程的 2. metric只是作为评价网络表现的一种"指标", 比如accuracy,是为了直观地了解算法的效果,充当view的作用,并不参与到优化过程 在keras中实现自定义loss, 可以有两种方式,一种自定义 loss function, 例如: # 方式一 def vae_loss(x, x_decoded_mean): xent_loss = objectives.binary_
-
keras中的loss、optimizer、metrics用法
用keras搭好模型架构之后的下一步,就是执行编译操作.在编译时,经常需要指定三个参数 loss optimizer metrics 这三个参数有两类选择: 使用字符串 使用标识符,如keras.losses,keras.optimizers,metrics包下面的函数 例如: sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss='categorical_crossentropy', opt
-
Keras之自定义损失(loss)函数用法说明
在Keras中可以自定义损失函数,在自定义损失函数的过程中需要注意的一点是,损失函数的参数形式,这一点在Keras中是固定的,须如下形式: def my_loss(y_true, y_pred): # y_true: True labels. TensorFlow/Theano tensor # y_pred: Predictions. TensorFlow/Theano tensor of the same shape as y_true . . . return scalar #返回一个标量
-
Keras在训练期间可视化训练误差和测试误差实例
详细的解释,读者自行打开这个链接查看,我这里只把最重要的说下 fit() 方法会返回一个训练期间历史数据记录对象,包含 training error, training accuracy, validation error, validation accuracy 字段,如下打印 # list all data in history print(history.history.keys()) 完整代码 # Visualize training history from keras.models
-
使用Keras训练好的.h5模型来测试一个实例
环境:python 3.6 +opencv3+Keras 训练集:MNIST 下面划重点:因为MNIST使用的是黑底白字的图片,所以你自己手写数字的时候一定要注意把得到的图片也改成黑底白字的,否则会识别错(至少我得到的结论是这样的 ,之前用白底黑字的图总是识别出错) 注意:需要测试图片需要为与训练模时相同大小的图片,RGB图像需转为gray 代码: import cv2 import numpy as np from keras.models import load_model model =
-
在keras中实现查看其训练loss值
想要查看每次训练模型后的 loss 值变化需要如下操作 loss_value= [ ] self.history = model.fit(state,target_f,epochs=1, batch_size =32) b = abs(float(self.history.history['loss'][0])) loss_value.append(b) print(loss_value) loss_value = np.array( loss_value) x = np.array(range
-
Keras: model实现固定部分layer,训练部分layer操作
需求:Resnet50做调优训练,将最后分类数目由1000改为500. 问题:网上下载了resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5,更改了Resnet50后,由于所有层均参加训练,导致训练速度慢.实际上只需要训练最后3层,前面的层都不需要训练. 解决办法: ①将模型拆分为两个模型,一个为前面的notop部分,一个为最后三层,然后利用model的trainable属性设置只有后一个model训练,最后将两个模型合并起来. ②不用拆分,遍
-
Keras使用ImageNet上预训练的模型方式
我就废话不多说了,大家还是直接看代码吧! import keras import numpy as np from keras.applications import vgg16, inception_v3, resnet50, mobilenet #Load the VGG model vgg_model = vgg16.VGG16(weights='imagenet') #Load the Inception_V3 model inception_model = inception_v3.I
-
keras自定义回调函数查看训练的loss和accuracy方式
前言: keras是一个十分便捷的开发框架,为了更好的追踪网络训练过程中的损失函数loss和准确率accuracy,我们有几种处理方式,第一种是直接通过 history=model.fit(),来返回一个history对象,通过这个对象可以访问到训练过程训练集的loss和accuracy以及验证集的loss和accuracy. 第二种方式就是通过自定义一个回调函数Call backs,来实现这一功能,本文主要讲解第二种方式. 一.如何构建回调函数Callbacks 本文所针对的例子是卷积神经网络
-
keras实现theano和tensorflow训练的模型相互转换
我就废话不多说了,大家还是直接看代码吧~ </pre><pre code_snippet_id="1947416" snippet_file_name="blog_20161025_1_3331239" name="code" class="python"> # coding:utf-8 """ If you want to load pre-trained weights
-

TensorFlow实现随机训练和批量训练的方法
TensorFlow更新模型变量.它能一次操作一个数据点,也可以一次操作大量数据.一个训练例子上的操作可能导致比较"古怪"的学习过程,但使用大批量的训练会造成计算成本昂贵.到底选用哪种训练类型对机器学习算法的收敛非常关键. 为了TensorFlow计算变量梯度来让反向传播工作,我们必须度量一个或者多个样本的损失. 随机训练会一次随机抽样训练数据和目标数据对完成训练.另外一个可选项是,一次大批量训练取平均损失来进行梯度计算,批量训练大小可以一次上扩到整个数据集.这里将显示如何扩展前面的回
-
Tensorflow实现在训练好的模型上进行测试
Tensorflow可以使用训练好的模型对新的数据进行测试,有两种方法:第一种方法是调用模型和训练在同一个py文件中,中情况比较简单:第二种是训练过程和调用模型过程分别在两个py文件中.本文将讲解第二种方法. 模型的保存 tensorflow提供可保存训练模型的接口,使用起来也不是很难,直接上代码讲解: #网络结构 w1 = tf.Variable(tf.truncated_normal([in_units, h1_units], stddev=0.1)) b1 = tf.Variable(tf
-
keras分类模型中的输入数据与标签的维度实例
在<python深度学习>这本书中. 一.21页mnist十分类 导入数据集 from keras.datasets import mnist (train_images, train_labels), (test_images, test_labels) = mnist.load_data() 初始数据维度: >>> train_images.shape (60000, 28, 28) >>> len(train_labels) 60000 >>