TensorFlow实现模型断点训练,checkpoint模型载入方式
深度学习中,模型训练一般都需要很长的时间,由于很多原因,导致模型中断训练,下面介绍继续断点训练的方法。
方法一:载入模型时,不必指定迭代次数,一般默认最新
# 保存模型
saver = tf.train.Saver(max_to_keep=1) # 最多保留最新的模型
# 开启会话
with tf.Session() as sess:
# saver.restore(sess, './log/' + "model_savemodel.cpkt-" + str(20000))
sess.run(tf.global_variables_initializer())
ckpt = tf.train.get_checkpoint_state('./log/') # 注意此处是checkpoint存在的目录,千万不要写成‘./log'
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess,ckpt.model_checkpoint_path) # 自动恢复model_checkpoint_path保存模型一般是最新
print("Model restored...")
else:
print('No Model')
方法二:载入时,指定想要载入模型的迭代次数
需要到Log文件夹中,查看当前迭代的次数,如下:此时为111000次。
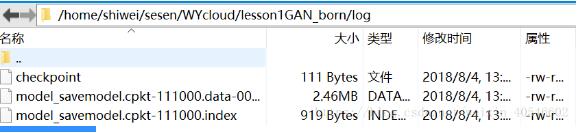
# 保存模型 saver = tf.train.Saver(max_to_keep=1) # 开启会话 with tf.Session() as sess: saver.restore(sess, './log/' + "model_savemodel.cpkt-" + str(111000)) sess.run(tf.global_variables_initializer())
载入模型后,会继续端点处的变量继续训练,那么是否可以减小剩余的需要的迭代次数?
模型断点训练效果展示:
训练到167000次后,载入模型重新训练。设置迭代次数为10000次,(d_step=1000)。原始设置的迭代的次数为1000000,已经训练了167000次。
Model restored... Iter:0, D_loss:0.5139875411987305, G_loss:2.8023970127105713 Iter:1000, D_loss:0.4400891065597534, G_loss:2.781547784805298 Iter:2000, D_loss:0.5169454216957092, G_loss:2.58009934425354 Iter:3000, D_loss:0.4507023096084595, G_loss:2.584151268005371 Iter:4000, D_loss:0.5746167898178101, G_loss:2.5365757942199707 Iter:5000, D_loss:0.5288565158843994, G_loss:2.426676034927368 Iter:6000, D_loss:0.549595057964325, G_loss:2.820535659790039 Iter:7000, D_loss:0.32620012760162354, G_loss:2.540236473083496 Iter:8000, D_loss:0.4363398551940918, G_loss:2.5880446434020996 Iter:9000, D_loss:0.569464921951294, G_loss:2.5133447647094727 done!
保存的图片仍然从头开始编号,会覆盖掉之前的图片。

以前对应编号的采样图片为:

若有朋友有高见,还请不吝赐教。
补充知识:tensorflow加载训练好的模型及参数(读取checkpoint)
checkpoint 保存路径
model_path下存有包含多个迭代次数的模型

1.获取最新保存的模型
即上图中的model-9400
import tensorflow as tf
graph=tf.get_default_graph() # 获取当前图
sess=tf.Session()
sess.run(tf.global_variables_initializer())
checkpoint_file=tf.train.latest_checkpoint(model_path)
saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_file))
saver.restore(sess,checkpoint_file)
2.获取某个迭代次数的模型
比如上图中的model-9200
import tensorflow as tf
graph=tf.get_default_graph() # 获取当前图
sess=tf.Session()
sess.run(tf.global_variables_initializer())
checkpoint_file=os.path.join(model_path,'model-9200')
saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_file))
saver.restore(sess,checkpoint_file)
获取变量值
## 得到当前图中所有变量的名称
tensor_name_list=[tensor.name for tensor in graph.as_graph_def().node]
# 查看所有变量
print(tensor_name_list)
# 获取input_x和input_y的变量值
input_x = graph.get_operation_by_name("input_x").outputs[0]
input_y = graph.get_operation_by_name("input_y").outputs[0]
以上这篇TensorFlow实现模型断点训练,checkpoint模型载入方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
tensorflow从ckpt和从.pb文件读取变量的值方式
最近在学习tensorflow自带的量化工具的相关知识,其中遇到的一个问题是从tensorflow保存好的ckpt文件或者是保存后的.pb文件(这里的pb是把权重和模型保存在一起的pb文件)读取权重,查看量化后的权重是否变成整形. 因此将自己解决这个问题记录下来,为了下一次遇到时,可以有所参考,也希望给有需要的同学一个可能的参考. (1) 从保存的ckpt读取变量的值(以读取保存的第一个权重为例) from tensorflow.python import pywrap_tensorflow i
-
Tensorflow 训练自己的数据集将数据直接导入到内存
制作自己的训练集 下图是我们数据的存放格式,在data目录下有验证集与测试集分别对应iris_test, iris_train 为了向伟大的MNIST致敬,我们采用的数据名称格式和MNIST类似 classification_index.jpg 图像的index都是5的整数倍是因为我们选择测试集的原则是每5个样本,选择一个样本作为测试集,其余的作为训练集和验证集 生成这样数据的过程相对简单,如果有需要python代码的,可以给我发邮件,或者在我的github下载 至此,我们的训练集,测试集,验证
-
tensorflow2.0保存和恢复模型3种方法
方法1:只保存模型的权重和偏置 这种方法不会保存整个网络的结构,只是保存模型的权重和偏置,所以在后期恢复模型之前,必须手动创建和之前模型一模一样的模型,以保证权重和偏置的维度和保存之前的相同. tf.keras.model类中的save_weights方法和load_weights方法,参数解释我就直接搬运官网的内容了. save_weights( filepath, overwrite=True, save_format=None ) Arguments: filepath: String,
-
Keras使用ImageNet上预训练的模型方式
我就废话不多说了,大家还是直接看代码吧! import keras import numpy as np from keras.applications import vgg16, inception_v3, resnet50, mobilenet #Load the VGG model vgg_model = vgg16.VGG16(weights='imagenet') #Load the Inception_V3 model inception_model = inception_v3.I
-
TensorFlow实现模型断点训练,checkpoint模型载入方式
深度学习中,模型训练一般都需要很长的时间,由于很多原因,导致模型中断训练,下面介绍继续断点训练的方法. 方法一:载入模型时,不必指定迭代次数,一般默认最新 # 保存模型 saver = tf.train.Saver(max_to_keep=1) # 最多保留最新的模型 # 开启会话 with tf.Session() as sess: # saver.restore(sess, './log/' + "model_savemodel.cpkt-" + str(20000)) sess.
-
tensorflow模型继续训练 fineturn实例
解决tensoflow如何在已训练模型上继续训练fineturn的问题. 训练代码 任务描述: x = 3.0, y = 100.0, 运算公式 x×W+b = y,求 W和b的最优解. # -*- coding: utf-8 -*-) import tensorflow as tf # 声明占位变量x.y x = tf.placeholder("float", shape=[None, 1]) y = tf.placeholder("float", [None,
-
keras实现theano和tensorflow训练的模型相互转换
我就废话不多说了,大家还是直接看代码吧~ </pre><pre code_snippet_id="1947416" snippet_file_name="blog_20161025_1_3331239" name="code" class="python"> # coding:utf-8 """ If you want to load pre-trained weights
-
tensorflow 2.0模式下训练的模型转成 tf1.x 版本的pb模型实例
升级到tf 2.0后, 训练的模型想转成1.x版本的.pb模型, 但之前提供的通过ckpt转pb模型的方法都不可用(因为保存的ckpt不再有.meta)文件, 尝试了好久, 终于找到了一个方法可以迂回转到1.x版本的pb模型. Note: 本方法首先有些要求需要满足: 可以拿的到模型的网络结构定义源码 网络结构里面的所有操作都是通过tf.keras完成的, 不能出现类似tf.nn 的tensorflow自己的操作符 tf2.0下保存的模型是.h5格式的,并且仅保存了weights, 即通过mod
-

pytorch_pretrained_bert如何将tensorflow模型转化为pytorch模型
pytorch_pretrained_bert将tensorflow模型转化为pytorch模型 BERT仓库里的模型是TensorFlow版本的,需要进行相应的转换才能在pytorch中使用 在Google BERT仓库里下载需要的模型,这里使用的是中文预训练模型(chinese_L-12_H-768_A_12) 下载chinese_L-12_H-768_A-12.zip后解压,里面有5个文件 chinese_L-12_H-768_A-12.zip后解压,里面有5个文件 bert_config
-
Python实现Keras搭建神经网络训练分类模型教程
我就废话不多说了,大家还是直接看代码吧~ 注释讲解版: # Classifier example import numpy as np # for reproducibility np.random.seed(1337) # from keras.datasets import mnist from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense, Act
-
使用Keras建立模型并训练等一系列操作方式
由于Keras是一种建立在已有深度学习框架上的二次框架,其使用起来非常方便,其后端实现有两种方法,theano和tensorflow.由于自己平时用tensorflow,所以选择后端用tensorflow的Keras,代码写起来更加方便. 1.建立模型 Keras分为两种不同的建模方式, Sequential models:这种方法用于实现一些简单的模型.你只需要向一些存在的模型中添加层就行了. Functional API:Keras的API是非常强大的,你可以利用这些API来构造更加复杂的模
-
python神经网络slim常用函数训练保存模型
目录 学习前言 slim是什么 slim常用函数 1.slim = tf.contrib.slim 2.slim.create_global_step 3.slim.dataset.Dataset 4.slim.dataset_data_provider.DatasetDataProvider 5.slim.conv2d 6.slim.max_pool2d 7.slim.fully_connected 8.slim.learning.train 本次博文实现的目标 整体框架构建思路 1.整体框架
-
Tensorflow读取并输出已保存模型的权重数值方式
这篇文章是为了对网络模型的权重输出,可以用来转换成其他框架的模型. import tensorflow as tf from tensorflow.python import pywrap_tensorflow #首先,使用tensorflow自带的python打包库读取模型 model_reader = pywrap_tensorflow.NewCheckpointReader(r"model.ckpt") #然后,使reader变换成类似于dict形式的数据 var_dict =