使用darknet框架的imagenet数据分类预训练操作
最近一段时间一直在研究yolo物体检测,基于网络上很少有yolo的分类预训练和yolo9000的联合数据的训练方法,经过本人的真实实验,对这两个部分做一个整理(本篇介绍yolo的分类预训练)
1、数据准备
1000类的Imagenet图片数据
因为Imagenet不同的类别数据都是单独放在一个文件夹中,并且有特定的命名,如‘n00020287',所以在做分类时我们不需要去制作特定的标签,只要训练的图片的path中包含自身的类别标签,而不含有其他类的标签即可。
制作用于训练的数据列表*classf_list.txt
2、分类标签制作
制作所有类别的标签列表new_label.txt和标签对应的类别名称的列表new_name.txt
new_label.txt

new_name.txt(训练时不需要,但是测试时可以显示出具体的类别)
3、修改cfg/.data配置文件(*classf.data)
classes=1000 train =/home/research/disk2/wangshun/yolo1700/darknet/coco/filelist/classf_list.txt labels=data/new_label.txt names=data/new_name.txt backup=backup top=5
修改网络配置文件(classf.cfg)
[net] #Training batch=64 subdivisions=1 width=416 height=416 channels=3 momentum=0.9 decay=0.0005 angle=0 saturation = 1.5 exposure = 1.5 hue=.1 max_crop = 512 learning_rate=0.001 burn_in=1000 max_batches = 1000000000 policy=steps steps=350000,500000,750000,1200000 scales=.1,.1,.1,.1 [convolutional] batch_normalize=1 filters=16 size=3 stride=1 pad=1 activation=leaky [maxpool] size=2 stride=2 [convolutional] batch_normalize=1 filters=32 size=3 stride=1 pad=1 activation=leaky [maxpool] size=2 stride=2 [convolutional] batch_normalize=1 filters=64 size=3 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=32 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=64 size=3 stride=1 pad=1 activation=leaky [maxpool] size=2 stride=2 [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=leaky [maxpool] size=2 stride=2 [convolutional] batch_normalize=1 filters=64 size=3 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [maxpool] size=2 stride=2 [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky ####### [convolutional] batch_normalize=1 size=1 stride=1 pad=1 filters=128 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=256 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=256 activation=leaky [convolutional] filters=1000 size=1 stride=1 pad=1 activation=leaky [avgpool] [softmax] groups = 1 [cost] type=sse
当然中间的网络层是我自己修改的网络。
5. 训练
./darknet classifier train cfg/classf.data cfg/classf.cfg -gpus 0,3(选择自己机器的gpu)
6 . 测试
./darknet classifier predict cfg/classf.data cfg/classf.cfg backup/classf.weights data/eagle.jpg
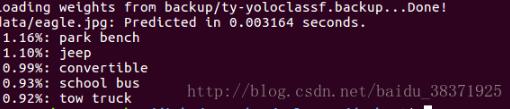
当然这只是刚刚训练了2000次测试的结果,只是测试,还需要继续训练。
以上这篇使用darknet框架的imagenet数据分类预训练操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
keras实现VGG16方式(预测一张图片)
我就废话不多说了,大家还是直接看代码吧~ from keras.applications.vgg16 import VGG16#直接导入已经训练好的VGG16网络 from keras.preprocessing.image import load_img#load_image作用是载入图片 from keras.preprocessing.image import img_to_array from keras.applications.vgg16 import preprocess_inpu
-
Keras构建神经网络踩坑(解决model.predict预测值全为0.0的问题)
终于构建出了第一个神经网络,Keras真的很方便. 之前不知道Keras这么方便,在构建神经网络的过程中绕了很多弯路,最开始学的TensorFlow,后来才知道Keras. TensorFlow和Keras的关系,就像c语言和python的关系,所以Keras是真的好用. 搞不清楚数据的标准化和归一化的关系,想对原始数据做归一化,却误把数据做了标准化,导致用model.predict预测出来的值全是0.0,在网上搜了好久但是没搜到答案,后来自己又把程序读了一遍,突然灵光一现好像是数据归一化出了问
-
Keras使用ImageNet上预训练的模型方式
我就废话不多说了,大家还是直接看代码吧! import keras import numpy as np from keras.applications import vgg16, inception_v3, resnet50, mobilenet #Load the VGG model vgg_model = vgg16.VGG16(weights='imagenet') #Load the Inception_V3 model inception_model = inception_v3.I
-
Keras预训练的ImageNet模型实现分类操作
本文主要介绍通过预训练的ImageNet模型实现图像分类,主要使用到的网络结构有:VGG16.InceptionV3.ResNet50.MobileNet. 代码: import keras import numpy as np from keras.applications import vgg16, inception_v3, resnet50, mobilenet # 加载模型 vgg_model = vgg16.VGG16(weights='imagenet') inception_mo
-
使用darknet框架的imagenet数据分类预训练操作
最近一段时间一直在研究yolo物体检测,基于网络上很少有yolo的分类预训练和yolo9000的联合数据的训练方法,经过本人的真实实验,对这两个部分做一个整理(本篇介绍yolo的分类预训练) 1.数据准备 1000类的Imagenet图片数据 因为Imagenet不同的类别数据都是单独放在一个文件夹中,并且有特定的命名,如'n00020287',所以在做分类时我们不需要去制作特定的标签,只要训练的图片的path中包含自身的类别标签,而不含有其他类的标签即可. 制作用于训练的数据列表*classf
-
darknet框架中YOLOv3对数据集进行训练和预测详解
目录 1. 下载darknet源码 2. 修改darknet的Makefile文件 3. 准备数据集 4. 修改voc_label.py 5. 下载预训练模型 6. 修改./darknet/cfg/voc.data文件 7. 修改./darknet/data/voc.name文件 8. 修改./darknet/cfg/yolov3-voc.cfg文件 9. 开始训练 10.训练终止后继续训练方法 1. 下载darknet源码 在命令窗口(terminal)中进入你想存放darknet源码的路径,
-
使用Keras预训练好的模型进行目标类别预测详解
前言 最近开始学习深度学习相关的内容,各种书籍.教程下来到目前也有了一些基本的理解.参考Keras的官方文档自己做一个使用application的小例子,能够对图片进行识别,并给出可能性最大的分类. 闲言少叙,开始写代码 环境搭建相关就此省去,网上非常多.我觉得没啥难度 from keras.applications.resnet50 import ResNet50 from keras.preprocessing import image from keras.applications.res
-
PyTorch预训练Bert模型的示例
本文介绍以下内容: 1. 使用transformers框架做预训练的bert-base模型: 2. 开发平台使用Google的Colab平台,白嫖GPU加速: 3. 使用datasets模块下载IMDB影评数据作为训练数据. transformers模块简介 transformers框架为Huggingface开源的深度学习框架,支持几乎所有的Transformer架构的预训练模型.使用非常的方便,本文基于此框架,尝试一下预训练模型的使用,简单易用. 本来打算预训练bert-large模型,发现
-

pytorch fine-tune 预训练的模型操作
之一: torchvision 中包含了很多预训练好的模型,这样就使得 fine-tune 非常容易.本文主要介绍如何 fine-tune torchvision 中预训练好的模型. 安装 pip install torchvision 如何 fine-tune 以 resnet18 为例: from torchvision import models from torch import nn from torch import optim resnet_model = models.resne
-
python PyTorch预训练示例
前言 最近使用PyTorch感觉妙不可言,有种当初使用Keras的快感,而且速度还不慢.各种设计直接简洁,方便研究,比tensorflow的臃肿好多了.今天让我们来谈谈PyTorch的预训练,主要是自己写代码的经验以及论坛PyTorch Forums上的一些回答的总结整理. 直接加载预训练模型 如果我们使用的模型和原模型完全一样,那么我们可以直接加载别人训练好的模型: my_resnet = MyResNet(*args, **kwargs) my_resnet.load_state_dict(
-
pytorch 在网络中添加可训练参数,修改预训练权重文件的方法
实践中,针对不同的任务需求,我们经常会在现成的网络结构上做一定的修改来实现特定的目的. 假如我们现在有一个简单的两层感知机网络: # -*- coding: utf-8 -*- import torch from torch.autograd import Variable import torch.optim as optim x = Variable(torch.FloatTensor([1, 2, 3])).cuda() y = Variable(torch.FloatTensor([4,
-
pytorch 预训练层的使用方法
pytorch 预训练层的使用方法 将其他地方训练好的网络,用到新的网络里面 加载预训练网络 1.原先已经训练好一个网络 AutoEncoder_FC() 2.首先加载该网络,读取其存储的参数 3.设置一个参数集 cnnpre = AutoEncoder_FC() cnnpre.load_state_dict(torch.load('autoencoder_FC.pkl')['state_dict']) cnnpre_dict =cnnpre.state_dict() 加载新网络 1.设置新的网