SQL语句的各个关键字的解析过程详细总结
由于最近需要做一些sql query性能提升的研究,因此研究了一下sql语句的解决过程。在园子里看了下,大家写了很多相关的文章,大家的侧重点各有不同。本文是我在看了各种资料后手机总结的,会详细的,一步一步的讲述一个sql语句的各个关键字的解析过程,欢迎大家互相学习。
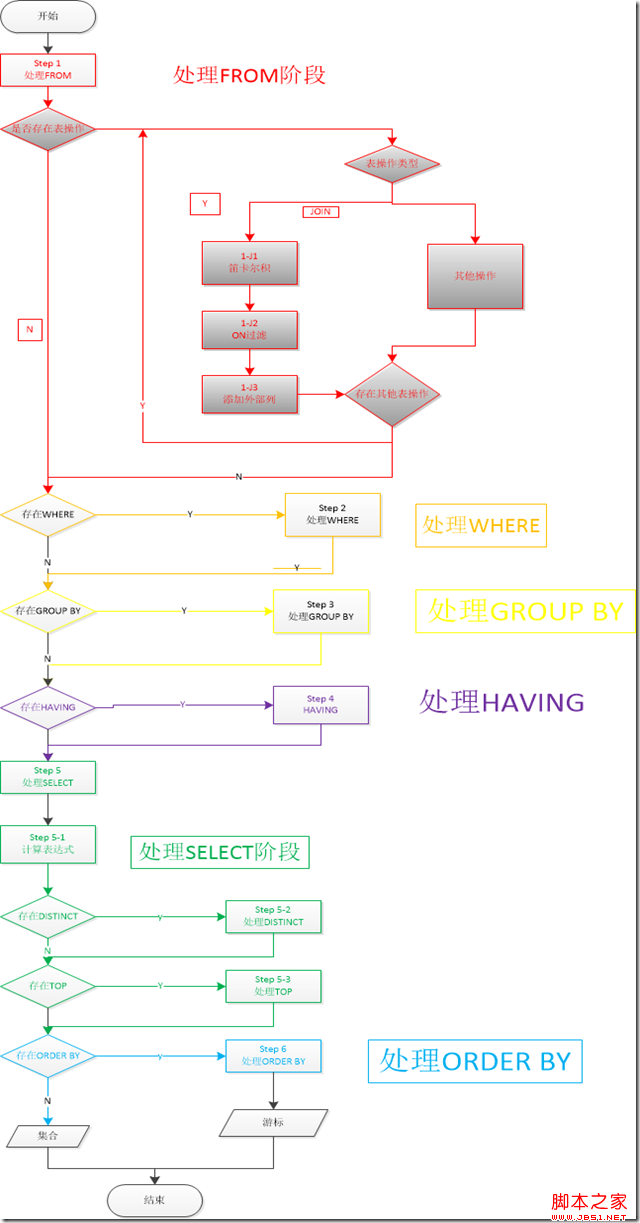
SQL语句的解析顺序
简单的说一个sql语句是按照如下的顺序解析的:
1. FROM FROM后面的表标识了这条语句要查询的数据源。和一些子句如,(1-J1)笛卡尔积,(1-J2)ON过滤,(1-J3)添加外部列,所要应用的对象。FROM过程之后会生成一个虚拟表VT1。
(1-J1)笛卡尔积 这个步骤会计算两个相关联表的笛卡尔积(CROSS JOIN) ,生成虚拟表VT1-J1。
(1-J2)ON过滤 这个步骤基于虚拟表VT1-J1这一个虚拟表进行过滤,过滤出所有满足ON 谓词条件的列,生成虚拟表VT1-J2。
(1-J3)添加外部行 如果使用了外连接,保留表中的不符合ON条件的列也会被加入到VT1-J2中,作为外部行,生成虚拟表VT1-J3。
2. WHERE 对VT1过程中生成的临时表进行过滤,满足where子句的列被插入到VT2表中。
3. GROUP BY 这个子句会把VT2中生成的表按照GROUP BY中的列进行分组。生成VT3表。
4. HAVING 这个子句对VT3表中的不同的组进行过滤,满足HAVING条件的子句被加入到VT4表中。
5. SELECT 这个子句对SELECT子句中的元素进行处理,生成VT5表。
(5-1)计算表达式 计算SELECT 子句中的表达式,生成VT5-1
(5-2)DISTINCT 寻找VT5-1中的重复列,并删掉,生成VT5-2
(5-3)TOP 从ORDER BY子句定义的结果中,筛选出符合条件的列。生成VT5-3表
ORDER BY 从VT5-3中的表中,根据ORDER BY 子句的条件对结果进行排序,生成VC6表。
客户,订单的查询例子
首先创建一个Customers表,插入如下数据:
| customerid | city |
| FISSA | Madrid |
| FRNDO | Madrid |
| KRLOS | Madrid |
| MRPHS | Zion |
创建一个Orders表,插入如下数据:
| orderid | customerid |
| 1 | FRNDO |
| 2 | FRNDO |
| 3 | KRLOS |
| 4 | KRLOS |
| 5 | KRLOS |
| 6 | MRPHS |
| 7 | NULL |
假如我们想要查询来自Madrid的,订单数小于3的客户,并把他们的订单数显示出来,结果按照订单数从小到大进行排序。
代码如下:
SELECT C.customerid, COUNT(O.orderid) AS numorders
FROM dbo.Customers AS C
LEFT OUTER JOIN dbo.Orders AS O
ON C.customerid = O.customerid
WHERE C.city = 'Madrid'
GROUP BY C.customerid
HAVING COUNT(O.orderid) < 3
ORDER BY numorders
查询结果为:
| customerid | numorders |
| FISSA | 0 |
| FRNDO | 2 |
下面我们会详细的讲述sql是怎样计算出这个结果的:
FROM子句
FROM子句标识了需要查询的表,如果指定了表操作,会从左到右的处理,每一个基于一个或者两个表的表操作都会返回一个输出表。左边表的输出结果会作为下一个表操作的输入结果。例如,交表相关的操作有 (1-J1)笛卡尔积,(1-J2)ON过滤器,(1-J3)添加外部列。FROM句子生成虚拟表VT1。
Step 1-J1:执行笛卡尔积(CROSS JOIN)
笛卡尔积会把左右两个表每一行所有可能的组合都列出来生成表VT1-J1,如果左表有m列,右表有n列,那么笛卡尔积之后生成的VT1-J1表将会有m×n列。
Step 1-J1这个步骤等价于执行:
SELECT * from Customers C CROSS JOIN Orders O
执行结果为:(共有4×7列)
| C.customerid | C.city | O.orderid | O.customerid |
| FISSA | Madrid | 1 | FRNDO |
| FISSA | Madrid | 2 | FRNDO |
| FISSA | Madrid | 3 | KRLOS |
| FISSA | Madrid | 4 | KRLOS |
| FISSA | Madrid | 5 | KRLOS |
| FISSA | Madrid | 6 | MRPHS |
| FISSA | Madrid | 7 | NULL |
| FRNDO | Madrid | 1 | FRNDO |
| FRNDO | Madrid | 2 | FRNDO |
| FRNDO | Madrid | 3 | KRLOS |
| FRNDO | Madrid | 4 | KRLOS |
| FRNDO | Madrid | 5 | KRLOS |
| FRNDO | Madrid | 6 | MRPHS |
| FRNDO | Madrid | 7 | NULL |
| KRLOS | Madrid | 1 | FRNDO |
| KRLOS | Madrid | 2 | FRNDO |
| KRLOS | Madrid | 3 | KRLOS |
| KRLOS | Madrid | 4 | KRLOS |
| KRLOS | Madrid | 5 | KRLOS |
| KRLOS | Madrid | 6 | MRPHS |
| KRLOS | Madrid | 7 | NULL |
| MRPHS | Zion | 1 | FRNDO |
| MRPHS | Zion | 2 | FRNDO |
| MRPHS | Zion | 3 | KRLOS |
| MRPHS | Zion | 4 | KRLOS |
| MRPHS | Zion | 5 | KRLOS |
| MRPHS | Zion | 6 | MRPHS |
| MRPHS | Zion | 7 | NULL |
ON过滤条件是sql的三个过滤条件(ON,WHERE,HAVING)中最先执行的,ON过滤条件应用于前一步生成的虚拟表(VT1-J1),满足ON过滤条件的行会被加入到虚拟表VT1-J2中。在应用了ON 过滤之后,生成的VT1-J2表如下所示:
| C.customerid | C.city | O.orderid | O.customerid |
| FRNDO | Madrid | 1 | FRNDO |
| FRNDO | Madrid | 2 | FRNDO |
| KRLOS | Madrid | 3 | KRLOS |
| KRLOS | Madrid | 4 | KRLOS |
| KRLOS | Madrid | 5 | KRLOS |
| MRPHS | Zion | 6 | MRPHS |
这个步骤只会出现在使用了外连接的情况。对于外连接(LEFT,RIGHT, or FULL),你可以标记一个或者两个表作为保留表。作为保留表意味着你希望这个表里面的所有列都被返回,即使它里面的数据不满足ON子句的过滤条件。LEFT OUTER JOIN 把左边的表标记为保留表,RIGHTOUTER JOIN把右边的表作为保留表,FULL OUTER JOIN把两个表都标记为保留表.Step 1-J3为根据VT1-J2中的虚拟表,添加了保留表中不满足ON 条件的列,在未保留表中没有对应的列,因此标记为NULL。这个过程生成了虚拟表VT1-J3。
| C.customerid | C.city | O.orderid | O.customerid |
| FISSA | Madrid | NULL | NULL |
| FRNDO | Madrid | 1 | FRNDO |
| FRNDO | Madrid | 2 | FRNDO |
| KRLOS | Madrid | 3 | KRLOS |
| KRLOS | Madrid | 4 | KRLOS |
| KRLOS | Madrid | 5 | KRLOS |
| MRPHS | Zion | 6 | MRPHS |
如果FROM子句中有多个表操作运算,sql会按照从左到右的顺序处理,左边生成的临时表结果作为右边表的输入表。
Step 2 WHERE 子句
WHERE过滤被应用到前一步生成的临时表中,根据WHERE过滤条件生成临时表VT2。
注意:由于数据现在还没有被分组,因此现在你不能使用聚合运算-例如:你不能使用这样的句子 WHERE orderdate = MAX(orderdate)。另外你也不能使用SELECT子句中创建的变量别名,因为现在还没有处理SELECT子句-例如你不能写这样的句子:SELECT YEAR(orderdate) AS orderyear . . . WHERE orderyear > 2008.
应用这个过滤
WHERE C.city = 'Madrid'
这时生成的临时表VT2的内容如下:
| C.customerid | C.city | O.orderid | O.customerid |
| FISSA | Madrid | NULL | NULL |
| FRNDO | Madrid | 1 | FRNDO |
| FRNDO | Madrid | 2 | FRNDO |
| KRLOS | Madrid | 3 | KRLOS |
| KRLOS | Madrid | 4 | KRLOS |
| KRLOS | Madrid | 5 | KRLOS |
在这个例子中,你需要在ON子句中使用ON C.customerid = O.customerid过滤,没有订单的客户在1-J2这一步中被过滤掉,但是在1-J3这一步中作为外部列又被加回来。但是,由于你只想返回来自Madrid的客户,因此你需要在WHERE子句中过滤城市(WHERE C.city = ‘Madrid'),如果你放在ON过滤中,不属于Madrid的客户在添加外部列中会被添加回来。
关于ON 和 WHERE 的区别需要在这里说明一下,ON 和WHERE 的主要区别在于 ON 实在添加外部列之前进行过滤,WHERE 是在之后。ON过滤掉的列会在1-J3中添加回来。如果你不需要添加外部列,那么这两个过滤是相同的。
Step 3 GROUP BY子句
这个子句会把前一步中生成的临时表中的数据进行分组,每一行都会分到并且只分到一个组里,生成虚拟表VT3。VT3表中包含了VT2表中所有的数据,和分组标识符。
这是生成的临时表VT3的内容如下:
| Groups C.customerid | C.customerid | C.city | O.orderid | O.customerid |
| FISSA | FISSA | Madrid | NULL | NULL |
| FRNDO | FRNDO | Madrid | 1 | FRNDO |
| FRNDO | Madrid | 2 | FRNDO | |
| KRLOS | Madrid | 3 | KRLOS | |
| KRLOS | KRLOS | Madrid | 4 | KRLOS |
| KRLOS | Madrid | 5 | KRLOS |
sql最终返回的结果中,每一个分组必须只能返回一行(除非被过滤掉),因此当一个sql语句中使用了GROUP BY时,在GROUP BY后面处理的子句,如SELECT,HAVING子句等,只能使用出现在GROUP BY后面的列,对于没有出现GROUP BY后面的列必须使用聚合函数(如 MAX ,MIN,COUNT,AVG等),保证每一个GROUP只返回一行。
Step 4 HAVING子句
HAVING子句用来过滤前一步生成的临时表,并且只作用于分组后的数据,满足HAVING条件的GROUP被添加到虚拟表VT4中。
HAVING COUNT(O.orderid) < 3
之后,生成的VT4表内容如下:
| Groups C.customerid | C.customerid | C.city | O.orderid | O.customerid |
| FISSA | FISSA | Madrid | NULL | NULL |
| FRNDO | FRNDO | Madrid | 1 | FRNDO |
| FRNDO | Madrid | 2 | FRNDO |
需要注意的一点是,这里面使用的是COUNT(O.orderid),而不是COUNT(*),由于这个查询中添加了外部列,COUNT方法会忽略NULL的列,导致出现了你不想要的结果。
Step 5 SELECT 子句
尽管出现在sql语句的最前面,SELECT在第五步的时候才被处理,SELECT子句返回的表会最终返回给调用者。这个子句包含三个子阶段:(5-1)计算表达式,(5-2) 处理DISTINCT,(5-3)应用TOP过滤。
Step 5-1 计算表达式
SELECT子句中的表达式可以返回或者操作前一步表中返回的基本列。如果这个sql语句是一个聚合查询,在Step 3之后,你只能使用GROUP BY中的列,对不属于GROUP集合中的列必须使用聚合运算。不属于FROM表中基本列的必须为其起一个别名,如YEAR(orderdate) AS orderyear。
注意:在SELECT子句中创建的别名,不能在之前的Step中使用,即使在SELECT子句中也不能。原因是sql的很多操作是同时操作(all at once operation),至于什么是all-at-once operation这里就不再介绍了。因此,SELECT子句中创建的别名只能在后面的子句中使用,如ORDER BY。例如:SELECT YEAR(orderdate) AS orderyear . . . ORDER BY orderyear。
SELECT C.customerid, COUNT(O.orderid) AS numorders
结果会得到一个虚拟表VT5-1:
| C.customerid | numorders |
| FIFSSA | 0 |
| FRNDO | 2 |
Step 5-2:应用DISTINCT子句
如果sql语句中使用了DISTINCT,sql会把重复列去掉,生成虚拟表VT5-2。
Step 5-3:应用TOP选项
TOP选项是T-SQL提供的一个功能,用来表示显示多少行。基于ORDER BY子句定义的顺序,指定个数的列会被查询出来。这个过程生成虚拟表VT5-3。
正如上文提到的,这一步依赖于ORDER BY定义的顺序来决定哪些列应该显示在前面。如果你没有指定结果的ORDER BY顺序,也没有使用WITH TIES子句 ,每一次的返回结果可能会不一致。
在我们的例子中,Step 5-3被省略了,因为我们没有使用TOP关键字。
Step 6:ORDER BY子句
前一步返回的虚拟表在这一步被排序,根据ORDER BY子句指定的顺序,返回游标VC6。ORDER BY子句也是唯一一个可以使用SELECT子句创建的别名的地方。
注意:这一步和之前不同的地方在于,这一步返回的结果是一个游标,而不是表。sql是基于集合理论的,一个集合没有对他的行定义顺序,它只是一个成员的逻辑集合,因此成员的顺序并不重要。带有ORDER BY子句的sql返回一个按照特定序列组织每一行的对象。ANSI 把这样的一个对象叫游标。理解这一点对你了解sql很重要。
上面的步骤如图所示:
本书中主要内容是参照 Inside Microsoft SQL Server 2008:T-SQL Query,中的内容,大家如果想深入了解sql查询相关的知识,可以找这本书看看,我这有英文原版的pdf,需要的可以找我要。
相关推荐
-

SQL语句的各个关键字的解析过程详细总结
由于最近需要做一些sql query性能提升的研究,因此研究了一下sql语句的解决过程.在园子里看了下,大家写了很多相关的文章,大家的侧重点各有不同.本文是我在看了各种资料后手机总结的,会详细的,一步一步的讲述一个sql语句的各个关键字的解析过程,欢迎大家互相学习. SQL语句的解析顺序 简单的说一个sql语句是按照如下的顺序解析的: 1. FROM FROM后面的表标识了这条语句要查询的数据源.和一些子句如,(1-J1)笛卡尔积,(1-J2)ON过滤,(1-J3)添加外部列,所要应用的对象.F
-
mybatis定义sql语句标签之delete标签解析
目录 mybatis之delete标签 属性说明 简单示例 <delete>标签与delete语句 delete语句 批量删除 mybatis之delete标签 delete标签目前没什么好说的,并且这个标签在实际业务中使用的非常少. 因为对于真实业务来说,所有数据都是有价值的,不允许做硬删除,除非没业务的垃圾数据. 属性说明 id:和其它标签一样是唯一标志 简单示例 <delete id="deleteNodeById"> delete fro
-
iOS开发中使用SQL语句操作数据库的基本用法指南
SQL代码应用示例 一.使用代码的方式批量添加(导入)数据到数据库中 1.执行SQL语句在数据库中添加一条信息 插入一条数据的sql语句: 点击run执行语句之后,刷新数据 2.在ios项目中使用代码批量添加多行数据示例 代码示例: 复制代码 代码如下: // // main.m // 01-为数据库添加多行数据 // // Created by apple on 14-7-26. // Copyright (c) 2014年 wendingding. All rights reserv
-
MySQL高级进阶sql语句总结大全
目录 SELECT DISTINCT WHERE ANDOR IN BETWEEN 通配符 LIke ORDERBY 函数 city表格 字符串函数 常用函数实例: concat substr trim region replace groupby having 别名 子查询 exists 表链接 使用子查询实现多表查询 createview union 交集值 无交集值 case 空值(null)和无值(’')的区别 正则表达式 存储过程 创建存储过程 存储过程的参数 查看存储过程 删除存储过
-
MySQL一些常用高级SQL语句详解
目录 一.MySQL进阶查询 二.MySQL数据库函数 三.MySQL存储过程 总结 一.MySQL进阶查询 首先先创建两张表 mysql -u root -pXXX #登陆数据库,XXX为密码 create database jiangsu; #新建一个名为jiangsu的数据库 use jiangsu; #使用该数据库 create table location(Region char(20),Store_name char(20)); #创建location表,字段1为Region,数据类
-
MySQL执行SQL语句的流程详解
目录 1.通常sql执行流程 1.1 问题1:MySQL谁去处理网络请求? 1.2 问题2:MySQL如何执行sql语句? 1.3 查询解析器 1.4 查询优化器 1.5 存储引擎 1.6 执行器 2.总结 1.通常sql执行流程 用户发起请求到业务服务器,执行sql语句时,先到连接池中获取连接,然后到mysql服务器执行查询. 1.1 问题1:MySQL谁去处理网络请求? msyql服务器谁负责从这个连接中去监听这个网络请求?谁负责从网络连接里把数据读出来? 其实大家都知道,网络连接必须得分配
-
一些有用的sql语句整理 推荐收藏
1.说明:创建数据库 CREATE DATABASE database-name 2.说明:删除数据库 drop database dbname 3.说明:备份sql server --- 创建 备份数据的 device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat' --- 开始 备份 BACKUP DATABASE pubs TO testBack 4.说明:创建新表 cr
-
c# 剔除sql语句'尾巴'的五种方法
一:背景 1. 讲故事 这几天都在修复bug真的太忙了,期间也遇到了一个挺有趣bug,和大家分享一下,这是一块sql挺复杂的报表相关业务,不知道哪一位大佬在错综复杂的 嵌套 + 平行 if判断中sql拼接在某些UI组合下出问题了,最终的 sql 架构类似这样的. var sql = "select 1 union all select 2 union all select 3 union all"; 这种sql到数据库去肯定是报错的,有些朋友可能想说这还不简单,在相关的 if 判断中不
-
Mybatis超级强大的动态SQL语句大全
目录 1. If 语句 2. Where语句 2.1 和 where 元素等价的自定义 trim 元素 3. Set语句 3.1 与 set 元素等价的自定义 trim 元素 4. Choose语句 5. Foreach语句 6. SQL片段 7. Bind元素 附:MyBatis配置动态SQL语句 总结 1. If 语句 需求:根据作者名字和博客名字来查询博客!如果作者名字为空,那么只根据博客名字查询,反之,则根据作者名来查询 <!--需求1: 根据作者名字和博客名字来查询博客! 如果作者名字
-
SQL语句解析执行的过程及原理
目录 一.sqlSession简单介绍 二.获得sqlSession对象源码分析 三.SQL执行流程,以查询为例 一.sqlSession简单介绍 拿到SqlSessionFactory对象后,会调用SqlSessionFactory的openSesison方法,这个方法会创建一个Sql执行器(Executor),这个Sql执行器会代理你配置的拦截器方法. 获得上面的Sql执行器后,会创建一个SqlSession(默认使用DefaultSqlSession),这个SqlSession中也包含了C