SQL SERVER使用表分区优化性能
目录
- 1.简介
- 2.表分区
- 2.1分区范围
- 2.2分区键
- 2.3索引分区
- 3.创建表分区
- 3.1创建文件组
- 3.2指定文件组存放路径
- 3.3创建分区函数
- 3.4创建分区方案
- 3.5创建分区表
- 3.6创建分区索引
- 4.表分区的优缺点
1.简介
当一个表数据量很大时候,很自然我们就会想到将表拆分成很多小表,在执行查询时候就到各个小表去查,最后汇总数据集返回给调用者加快查询速度。比如电商平台订单表,库存表,由于长年累月读写较多,积累数据都是异常庞大的,这时候,我们可以想到表分区这个做法,降低运维和维护成本,提高读写性能。比如将前半年订单放一个历史分区表,不活跃库存放一个历史分区表。截止到SQL Server 2016,一张表或一个索引最多可以有15000个分区。
2.表分区
2.1分区范围
分区范围是指在要分区的表中,根据业务选择表中的关键字段做为分区边界条件,分区后,数据所在的具体位置至关重要,这样才能在需要时只访问相应的分区。注意分区是指数据的逻辑分离,不是数据在磁盘上的物理位置,数据的位置由文件组来决定,所以一般建议一个分区对应一个文件组。
2.2分区键
分区表中的字段可以作为分区键,比如库存表中供应商ID。对表和索引进行分区的第一步就是定义分区的关键数据。
2.3索引分区
除了对表的数据集进行分区之外,还可以对索引进行分区,使用相同的函数对表及其索引进行分区通常可以优化性能。
3.创建表分区
3.1创建文件组
在这里演示示例当中,我根据业务场景在TestDB数据库新增三个文件组,而三个文件组分别对应三个分区。而多个文件组好处是可以按照不同业务场景将数据放在对应文件组当中,优化性能同时好维护数据。文件组数量由硬件决定,最好是一个文件组对应一个分区,好维护。而通常文件组都处于不同磁盘上的,但是由于是演示,我只在一个磁盘中存放。
--创建四个文件组 ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup1 ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup2 ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup3
3.2指定文件组存放路径
在创建文件组之后,指定文件组存放磁盘位置,文件大小。
--创建四个ndf文件,对应到各文件组中,FILENAME文件存储路径 ALTER DATABASE [TestDB] ADD FILE( NAME='SupIDGroupFile1', FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile1.ndf', SIZE=10MB, FILEGROWTH=10MB) TO FILEGROUP SupIDGroup1 ALTER DATABASE [TestDB] ADD FILE( NAME='SupIDGroupFile2', FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile2.ndf', SIZE=10MB, FILEGROWTH=10MB) TO FILEGROUP SupIDGroup2 ALTER DATABASE [TestDB] ADD FILE( NAME='SupIDGroupFile3', FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile3.ndf', SIZE=10MB, FILEGROWTH=10MB) TO FILEGROUP SupIDGroup3
注(附上删除文件组T-SQL):
ALTER DATABASE [TestDB] REMOVE FILE SupIDGroupFile3

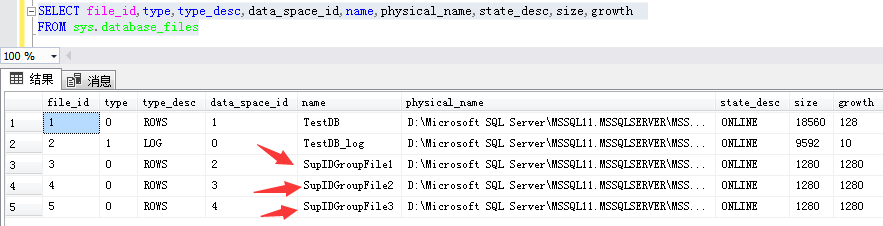
可以通过以下T-SQL语句查看文件组存放相关信息:
SELECT file_id,type,type_desc,data_space_id,name,physical_name,state_desc,size,growth FROM sys.database_files
3.3创建分区函数
如何创建表分区边界值,我们肯定要根据业务场景来决定。比如我测试库库存表有36万左右数据,而有些供应商的库存数据远远比其他供应商大,那么我可以考虑使用供应商ID字段作为边界值分区。例如:根据T-SQL统计,18080供应商库存数据最大,那么我可以根据18080供应商上下分为三个区。

第一个分区范围记录:供应商ID小于等于13570的39097条库存数据。

第二个分区范围记录:供应商ID大于13570和小于等于18079的45962条库存数据。

第三个分区范围记录:供应商ID大于18079小于等于18080的164937条库存数据。

第四个分区范围记录:供应商ID大于18080的111116条库存数据。

根据上述分区范围记录,我们可以将供应商ID作为边界值设置,执行以下T-SQL语句设置边界值:
--设置边界值 CREATE PARTITION FUNCTION PF_SupplierID(int) AS RANGE LEFT FOR VALUES (13570,18079,18080)
执行完毕后如图所示:

3.4创建分区方案
执行以下T-SQL语句创建分区方案:
--创建分区方案 CREATE PARTITION SCHEME PS_SupplierID AS PARTITION PF_SupplierID TO ([PRIMARY], [SupIDGroup1],[SupIDGroup2],[SupIDGroup3])
执行完毕后如图所示:

3.5创建分区表
上面那些分区步骤都是为了接下来创建分区表这一步骤而准备的。废话不多说,现在我们来看看如何创建分区表。右键需要分区的表->储存->创建分区,具体步骤如下图所示:






3.6创建分区索引
--创建分区索引
CREATE NONCLUSTERED INDEX [NCI_SupplierID] ON dbo.Stock
(
SupplierID ASC
)
INCLUDE ( [Model],[Brand],[Encapsulation]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO
或者

执行完毕后如图所示:

创建好索引之后,我们来看看分区情况:
--查看各分区有多少行数据 SELECT * FROM ( SELECT $PARTITION.PF_SupplierID([SupplierID]) AS Patition,COUNT(*) AS CountRows FROM dbo.Stock GROUP BY $PARTITION.PF_SupplierID([SupplierID]) )TB ORDER BY Patition

最后我们来看看加了索引之后表数据查询情况:

4.表分区的优缺点
优点:
- 改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
- 增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用。
- 维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可。
- 均衡I/O:可以把不同的分区映射到不同磁盘以平衡I/O,改善整个系统性能。
缺点:
分区表相关:已经存在的表没有方法可以直接转化为分区表。
到此这篇关于SQL SERVER使用表分区优化性能的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

SQLSERVER 表分区操作和设计方法
一 .聚集索引 聚集索引的页级别包含了索引键,还包含数据页,因此,关于 除了键值以外聚集索引的叶级别还存放了什么的答案就是一切,也就是说,每行的所有字段都在叶级别种.另一种说话是:数据本身也是聚集索引的一部分,聚集索引基于键值保持表中的数据有序.SQL SERVER 中,所有的聚集索引都是唯一的,如果在创建聚集索引时没有指定UNIQUE 关键字,SQL SERVER 会在需要时通过往记录中添加一个唯一标识符(Uniqueifier)在内部保证索引的唯一性,该唯一标识符是一个4字节的值,作为附加在
-
SQL Server表分区删除详情
目录 一.引言 二.演示 2.1.数据查询 2.1.1. 查看分区元数据 2.1.2.统计每个分区的数据量 2.2.删除实操 2.2.1.合并原表分区 2.2.2.备份原表所有索引的创建脚本 2.2.3.删除原表所有索引 2.2.4.创建临时表 2.2.5.更改原表数据空间类型 2.2.6.移动原表分区数据到临时表 2.2.7.创建原表所有索引 到临时表 2.2.8.删除原表 2.2.9.删除分区方案和分区函数 2.2.10重命名表名 一.引言 删除分区又称为合并分区,简单地讲就是将多个分区的数
-
SQL server 2005的表分区
下面来说下,在SQL SERVER 2005的表分区里,如何对已经存在的有数据的表进行分区,其实道理和之前在http://www.cnblogs.com/jackyrong/archive/2006/11/13/559354.html说到一样,只不过交换下顺序而已,下面依然用例子说明: 依然在c盘的data2目录下建立4个文件夹,用来做4个文件组,然后建立数据库 use masterIF EXISTS (SELECT name FROM sys.databases WHERE name =
-
SQL Server根据分区表名查找所在的文件及文件组实现脚本
SELECT ps.name AS PSName, dds.destination_idAS PartitionNumber, fg.name AS FileGroupName,fg.name, t.name, f.name as filename FROM (((sys.tables AS t INNER JOIN sys.indexes AS i ON (t.object_id = i.object_id)) INNER JOIN sys.partition_schemes AS ps ON
-
SQL Server 数据库分区分表(水平分表)详细步骤
1. 需求说明 将数据库Demo中的表按照日期字段进行水平分区分表.要求数据文件按一年一个文件存储,且分区的分割点会根据时间的增长自动添加(例如现在是2017年1月1日,将其作为一个分割点,即将2017年1月1日之前的数据存储到数据文件A中,将2017年1月1日的之后的数据存储到数据文件B中:当时间到2018年1月1日时,自动将2018年1月1日添加为一个新的分区分割点,并将2017年1月1日至2018年1月1日的数据存储在数据文件B中,将2018年1月1日之后的数据存储在一个新的数据文件C中,
-
SQL SERVER使用表分区优化性能
目录 1.简介 2.表分区 2.1分区范围 2.2分区键 2.3索引分区 3.创建表分区 3.1创建文件组 3.2指定文件组存放路径 3.3创建分区函数 3.4创建分区方案 3.5创建分区表 3.6创建分区索引 4.表分区的优缺点 1.简介 当一个表数据量很大时候,很自然我们就会想到将表拆分成很多小表,在执行查询时候就到各个小表去查,最后汇总数据集返回给调用者加快查询速度.比如电商平台订单表,库存表,由于长年累月读写较多,积累数据都是异常庞大的,这时候,我们可以想到表分区这个做法,降低运维和维护
-
sql server排查死锁优化性能
一.概述 记得以前客户在使用软件时,有偶发出现死锁问题,因为发生的时间不确定,不好做问题的重现,当时解决问题有点棘手了.现总结下查看死锁的常用二种方式. 1.1 第一种是图形化监听: sqlserver -->工具--> sql server profiler 登录后在跟踪属性中选择如下图: 监听到的死锁图形如下图 这里的描述大致是:有二个进程 一个进程ID是96, 另一个ID是348. 系统自动kill 掉了进程ID:96,保留了进程ID:348 的事务Commit. 上面死锁是由于批量更新
-
SQL Server 2016 查询存储性能优化小结
作为一个DBA,排除SQL Server问题是我们的职责之一,每个月都有很多人给我们带来各种不能解释却要解决的性能问题. 我就多次听到,以前的SQL Server的性能问题都还好且在正常范围内,但现在一切已经改变,SQL Server开始糟糕, 疯狂的事情不能解释.在这个情况下我介入,分析下整个SQL Server的安装,最后用一些神奇的调查方法找出性能问题的根源. 但很多时候问题的根源是一样的:所谓的计划回归(Plan Regression),即特定查询的执行计划已经改变.昨天SQL Serv
-
SQL server 2008 数据库优化常用脚本
--查询某个数据库的连接数 select count(*) from Master.dbo.SysProcesses where dbid=db_id() --前10名其他等待类型 SELECT TOP 10 * from sys.dm_os_wait_stats ORDER BY wait_time_ms DESC SELECT *FROM sys.dm_os_wait_stats WHERE wait_type like 'PAGELATCH%' OR wait_type like 'LAZ
-
sql语句优化之SQL Server(详细整理)
MS SQL Server查询优化方法 查询速度慢的原因很多,常见如下几种 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化. 4.内存不足 5.网络速度慢 6.查询出的数据量过大(可以采用多次查询,其他的方法降低数据量) 7.锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷) 8.sp_lock,sp_who,活动的用户查看,原因是读写竞争资源. 9.返回了不必要的行和列 10.查询语句不好,
-
SQL Server优化50法汇总
查询速度慢的原因很多,常见如下几种:1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)2.I/O吞吐量小,形成了瓶颈效应.3.没有创建计算列导致查询不优化.4.内存不足5.网络速度慢6.查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)7.锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)8.sp_lock, sp_who, 活动的用户查看,原因是读写竞争资源.9.返回了不必要的行和列 10.查询语句不好,没有优化可以通过如下方法来优化查询 :1.把数据.日
-
SQL Server 数据库优化
在开发工具.数据库设计.应用程序的结构.查询设计.接口选择等方面有多种选择,这取决于特定的应用需求以及开发队伍的技能.本文以SQL Server为例,从后台数据库的角度讨论应用程序性能优化技巧,并且给出了一些有益的建议.1 数据库设计 要在良好的SQL Server方案中实现最优的性能,最关键的是要有1个很好的数据库设计方案.在实际工作中,许多SQL Server方案往往是由于数据库设计得不好导致性能很差.所以,要实现良好的数据库设计就必须考虑这些问题. 1.1 逻辑库规范化问题 一般来说,逻辑
-
SQL SERVER 的SQL语句优化方式小结
1.SQL SERVER 2005的性能工具中有SQL Server Profiler和数据库引擎优化顾问,极好的东东,必须熟练使用. 2.查询SQL语句时打开"显示估计的执行计划",分析每个步骤的情况 3.初级做法,在CPU占用率高的时候,打开SQL Server Profiler运行,将跑下来的数据存到文件中,然后打开数据库引擎优化顾问调用那个文件进行分析,由SQL SERVER提供索引优化建议.采纳它的INDEX索引优化部分. 4.但上面的做法经常不会跑出你所需要的,在最近的优化
-
利用 SQL Server 过滤索引提高查询语句的性能分析
大家好,我是只谈技术不剪发的 Tony 老师. Microsoft SQL Server 过滤索引(筛选索引)是指基于满足特定条件的数据行进行索引.与全表索引(默认创建)相比,设计良好的筛选索引可以提高查询性能.减少索引维护开销并可降低索引存储开销.本文就给大家介绍一下 Microsoft SQL Server 中的过滤索引功能. 在创建过滤索引之前,我们需要了解它的适用场景. 在某个字段中只有少量相关值需要查询时,可以针对值的子集创建过滤索引. 例如,当字段中的值大部分为 NULL 并且查询只