Python实战之单词打卡统计
前言
观前提醒:因为是代码控制统计,所以操作每一个步骤都很重要,否则就会报错。
操作步骤
1.将在线编辑文档导入本地。
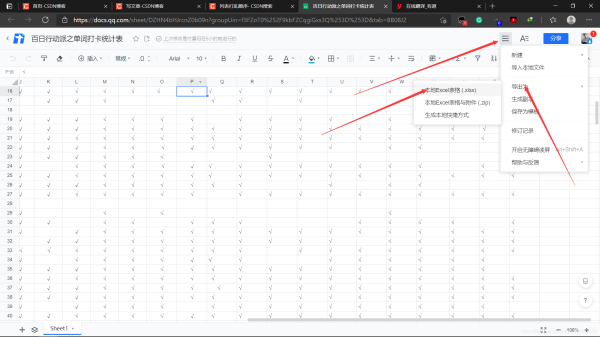
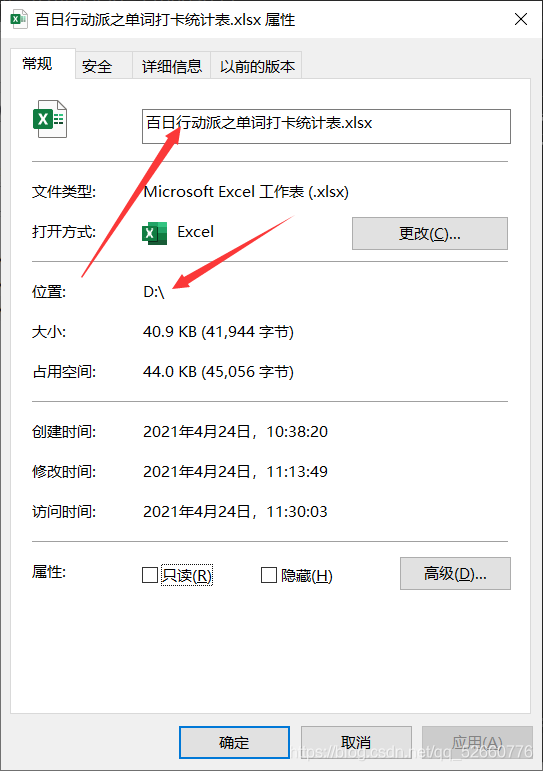
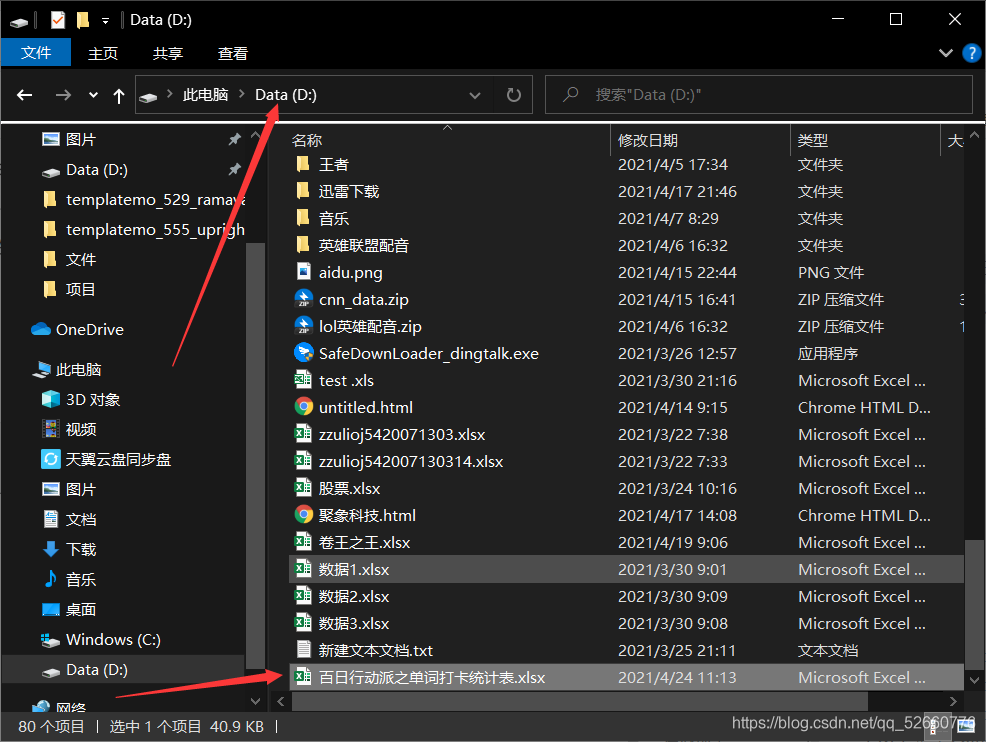
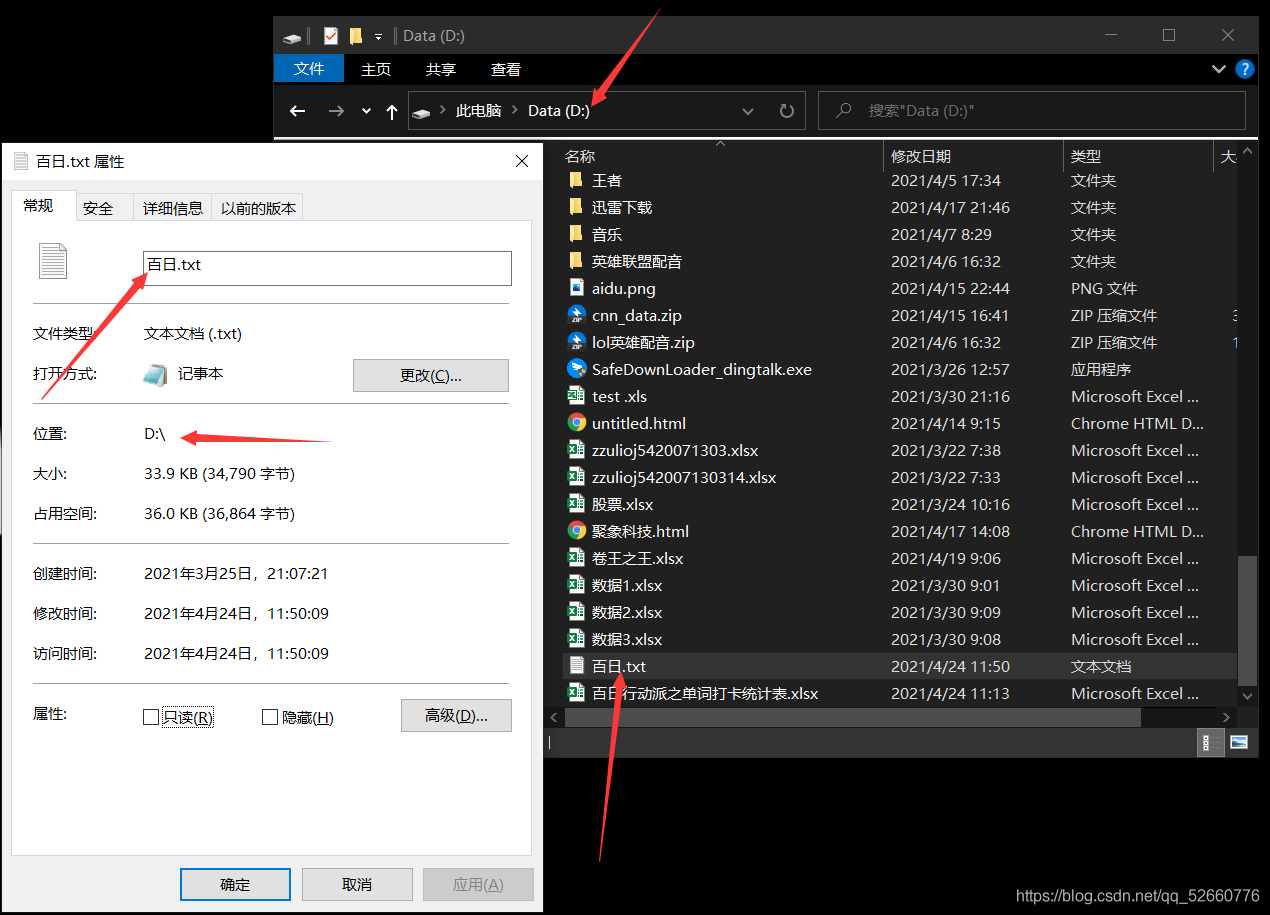
为了方便代码处理,将导出的excel表统一放在D盘直路径下,如果没懂,你可以查看文件属性,文件属性应该是这样:
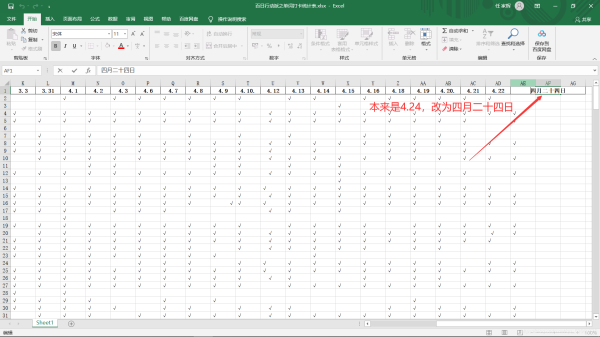
2.打开excel表,将你要统计的那天的日期改为中文(这一步很重要,因为数字索引无法进行定位,所以要改,不改就用不了)
3.因为QQ的安全防范机制做的太好了,爬虫和抓包工具都无法获取QQ信息,所以我只能采用最原始的方法进行数据获取。
你想的没错,就是复制粘贴。用电脑打开百日单词打卡群的相册
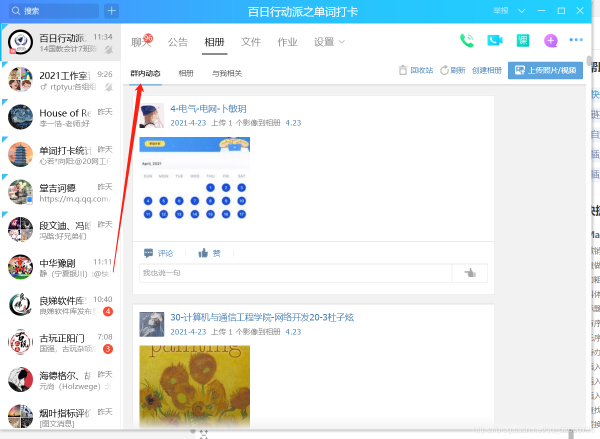
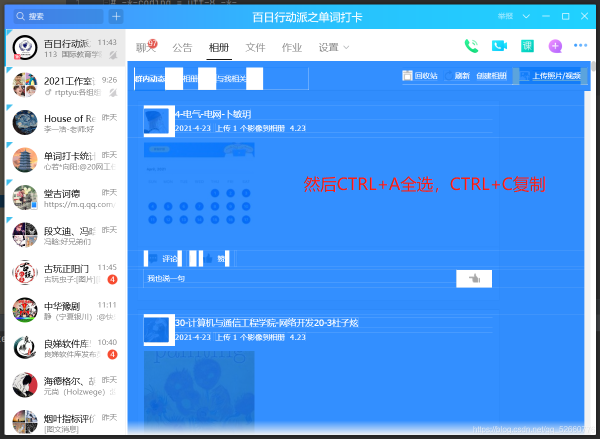
滑动滚轮,加载出统计日的所有上传信息,然后CTRL+A全选,CTRL+C复制。
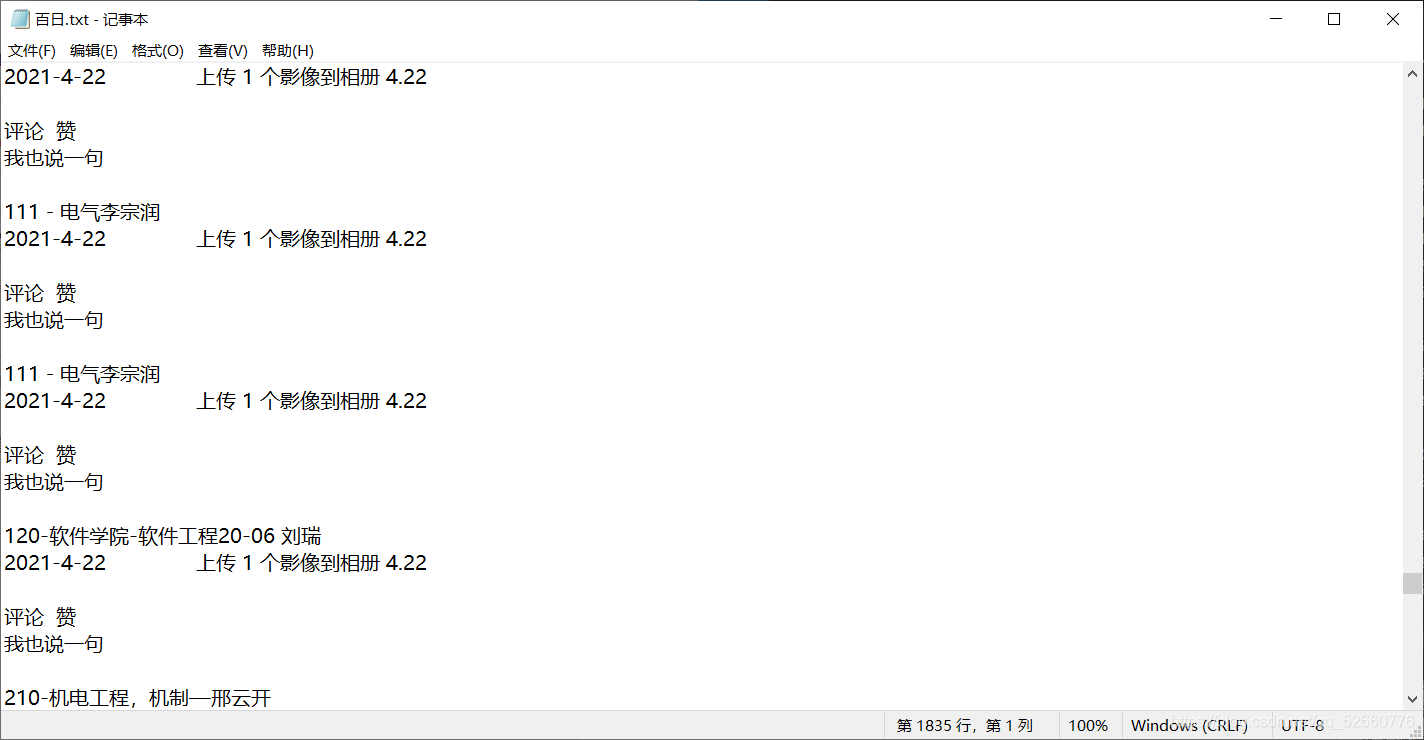
4.在D盘下,新建一个名字为:百日.txt 的文件将刚才复制的内容放进去。
5.运行代码。所有上传过背单词图片的人,就都在excel表里打上”√“了,但是为了防止有人想蒙混过关,我们再去相册里大致浏览一下,找到不合格的然后在excel表里去除”√“,但总的来说这样的情况还是极少数。
6.为了让excel表里的格式保持一致,打开编辑好的excel表,然后将汉语日期再改回4.24格式。
7.将统计好的excel表上传。
8.源代码:
# -*-coding = utf-8 -*-
# @Time:2021/4/24/10:40
# @Author:seven
# @File:自填.py
# @Software:PyCharm
import pandas as pd
import re
day=input("请输入你要统计的日期(例:4.23):")
DAY=input("请输入的更改后的列名(例:四月二十三日):")
findlink=re.compile("赞我也说一句.*?([\u4e00-\u9fa5]{3})2021-.*? 上传 1 个影像到相册 "+day)
with open("D:/百日.txt","r",encoding="utf-8") as fd:
a=fd.readlines()
w=''
for i in a:
i=i.strip()
w+=i
names=re.findall(findlink,w)
path="D:/百日行动派之单词打卡统计表.xlsx"
df=pd.read_excel(path,engine="openpyxl")
name=df.loc[0:,"姓名"]
day=df.loc[0:,DAY]
days=[]
for i in day:
days.append(i)
namelist=[]
for i in name:
namelist.append(i)
list=[]
for i in names:
try:
n=namelist.index(i)
list.append(n)
except:
print(i)
for i in list:
days[i]="√"
df.loc[0:,"四月二十四日"]=days
df.to_excel(path)
w=input("以上同学因备注格式不符未能自动统计,请自行统计")
9.如果你有使用python,可以打开编译器导入相关库后运行代码,如果你没有python,可以使用封装后的程序。
到此这篇关于Python实战之单词打卡统计的文章就介绍到这了,更多相关python单词打卡统计内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python实现自动打卡小程序
本文实例为大家分享了python实现自动打卡小程序的具体代码,供大家参考,具体内容如下 """ 湖南大学疫情防控每日自动打卡程序v1.0 author: Liu time:2021/3/16 """ from selenium import webdriver from selenium.webdriver.chrome.options import Options from PIL import Image from bs4 import Be
-
python实现自动打卡的示例代码
自己也百度了一下,然后写的,分为了三个部分,见三段代码 代码:主程序代码 import timefrom selenium import webdriverfrom private_info import * import send_mail def signin_and_email(): #谷歌浏览器驱动的位置 driver=webdriver.Chrome("D:/...../chromedriver") driver.get('http://****.edu.cn/login.p
-
Python + selenium + crontab实现每日定时自动打卡功能
前言 近几日迫于被辅导员三番五次的提醒每日一报打卡,就想着去写个脚本挂在服务器上定时执行.经过我不懈的努力,最终选择了seleniumseleniumselenium,因为简单( 安装selenium库 $ sudo pip install selenium 安装chromdriver 因为我有代理所以直接在官网下载的,那这里你可以选择用淘宝镜像源. 这里为了方便,我直接放命令了.Chromedriver版本我这里选择的是80.0.3987.16(注意要和一会儿下载的Chrome版本一致). 下
-
Python实现i人事自动打卡的示例代码
我司使用的打卡软件是 i 人事,不过我这记性,经常漏了打卡签退,定了闹钟都会忘,今天又被老大屌了.于是准备抓一下签到接口,利用 crontab 来实现自动签到签退. 环境配置 这里使用的是 Fiddler 进行抓包,Fiddler 是一个 HTTP 调试代理工具,以代理服务器的形式实现对网络数据流的监听.之所以没有用 Wireshark,一是因为我不是很熟悉 wireshark 的筛选器,二是因为本文使用模拟器(手机应用后台流量多,不便于分析)来抓包,代理服务器方式更方便. 安装Fiddler
-
使用Python实现企业微信的自动打卡功能
上下班打卡是程序员最讨厌的东西,更讨厌的是设置了连上指定wifi打卡. 手机上有一些定时机器人之类的app,经过实际测试,全军覆没,没一个可以活着走到启动企业微信的这一步,所以还是靠自己吧. 下面就通过Python程序来实现自动打卡,原理很简单,用Python设置定时任务,然后通过adb操作手机,完成打卡. 1.准备工作 a.安装了Python,ADB驱动(安装方式及下载地址见之前文章)的电脑一台:常驻在公司的测试机一台:数据线一条. b.将手机通过数据线连接电脑,打开开发者选项中的允许USB调
-
python获取微信企业号打卡数据并生成windows计划任务
由于公司的系统用的是Java版本,开通了企业号打卡之后又没有预算让供应商做数据对接,所以只能自己捣鼓这个,以下是个人设置的一些内容,仅供大家参考 安装python python的安装,这里就不详细写了,大家可自行度娘或google. 安装第三方库 python安装好之后别忘记配置环境变量!另外,所以的内容都是安装在服务器上的,且服务器需要能够上外网,否则,只能配置在本地,因为需要外网连接微信企业号的接口.这里需要用到几个第三方库: python的pip命令,一般python安装好之后都会默认有,
-

基于python+selenium自动健康打卡的实现代码
每天都要记得健康打卡 尊敬的老师,我忘了这次的健康打卡,反思的时候我想了很多东西,反省了很多事情,自己也很懊悔,触犯了学校的规定,深刻认识到自己所犯错误的严重性- 卡!那是小学生才有的检讨.作为一个有点懒的人,对于每次的健康打卡,都是做着重复性的填写,这让本人很是头疼,那就找找止疼药吧 使用的工具 需要有一定的python,html基础,和实践能力(毕竟实践出真知,实践能力强,你可以忽略前两个,你是最棒的!): Pycharm ,在pycharm官网里面下载社区版或专业版(没其他的用途推荐用社区
-
Python实现钉钉/企业微信自动打卡的示例代码
每天急匆匆赶地铁上班的时候总会一不小心就会忘记打卡,尤其是软件打卡,那有没有什么办法可以解决忘打卡的问题呢?今天给大家推荐一下一款神器,利用Python实现定时自动打卡. 1 前期工具准备 不用说的Python 一部24小时可以放公司的安卓手机或电脑安装模拟器 ADB工具 2 ADB的安装配置 去下载ADB安装包,安装后在环境变量Path中添加目录 2.1 UIautomator2的安装 # 安装 uiautomator2(PC端) pip3 install -U uiautomator2 3
-
python+selenium 简易地疫情信息自动打卡签到功能的实现代码
由于学校要求我们每天都要在官网打卡签到疫情信息,多多少少得花个1分钟操作,程序员的尊严告诉我们坚决不能手动打卡.正巧最近学了selenium,于是画了个5分钟写了个自动打卡签到地小程序. 测试环境:python3.7 , selenium,chrome浏览器 seleium和chromedriver的配置在这里就不讲了,这里放个连接 首先找到学校信息门户的登录页: http://my.hhu.edu.cn/login.portal #导入selenium中的webdriver from sele
-
Python 实现网课实时监控自动签到、打卡功能
响应国家停课不停学的号召,学生们都开始了网上授课,但由于课程繁多,消息繁杂,经常错过课堂签到,针对这一难题,博客主作为Python爱好者,完全使用Python语言写了本篇博客,希望能够帮助小伙伴们完成上课签到问题(注:只是帮你签到,而不是叫你代签,我的出发点是帮助记性不是很好的同学签到,防止漏签被老师点名),所以希望大家能理解博主的苦心. 话不多说,献上效果图两张 进入正式教程 ①Python环境 Python3.6及以上版本,需要配备的库requests,json,time 代码运行软件:Py