解决PyTorch与CUDA版本不匹配的问题
1.CUDA驱动和CUDA Toolkit对应版本
表一:CUDA驱动及CUDA Toolkit最高对应版本
最新可查阅官方文档
注:驱动是向下兼容的,其决定了可安装的CUDA Toolkit的最高版本。
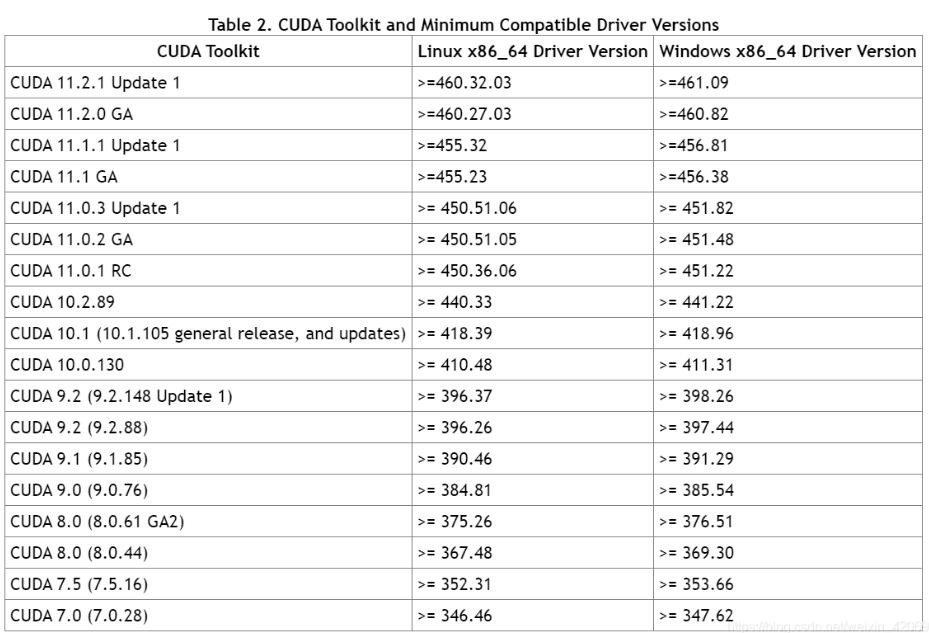
2.CUDA Toolkit版本及其可用PyTorch对应版本(参考官网)
表二:CUDA Toolkit版本及可用PyTorch对应关系
| CUDAToolkit版本 | 可用PyTorch版本 |
|---|---|
| 7.5 | 0.4.1 ,0.3.0, 0.2.0,0.1.12-0.1.6 |
| 8.0 | 1.1.0,1.0.0 ,0.4.1 |
| 9.0 | 1.1.0,1.0.1, 1.0.0,0.4.1 |
| 9.2 | 1.7.1,1.7.0,1.6.0,1.5.1,1.5.0,1.4.0,1.2.0,0.4.1 |
| 10.0 | 1.2.0,1.1.0,1.0.1 ,1.0.0 |
| 10.1 | 1.7.1,1.7.0,1.6.0,1.5.1,1.5.0, 1.4.0,1.3.0 |
| 10.2 | 1.7.1,1.7.0,1.6.0,1.5.1,1.5.0 |
| 11.0 | 1.7.1,1.7.0 |
| 11.1 | 1.8.0 |
注:虽有的卡驱动更新至较新版本,且CUDA Toolkit及PyTorch也可对应更新至新版本。但有的对应安装包无法使用,有可能是由于卡太旧的原因。
3.安装指导
在安装时会同时安装CUDA Toolkit以及PyTorch,这是我们要知道的。
步骤一:
使用nvidia-smi查询驱动版本:

如图中Driver Version所示,该卡目前的驱动版本为384.81。
步骤二:
此处提供三种方法可供选择。
(1)指定CUDA Toolkit版本
根据表一查询到可安装的CUDA Toolkit版本,384.81对应最高的CUDA Toolkit版本为9.0。
运行conda install pytorch cudatoolkit=9.0 -c pytorch即可。
此方法指定CUDA Toolkit版本后,conda会自动匹配到合适版本的PyTorch。
(2)指定PyTorch版本
根据表一查询到可安装的CUDA Toolkit版本,再根据表二查询到合适版本的PyTorch。384.81对应最高的CUDA Toolkit版本为9.0,9.0可安装PyTorch1.1.0版本。
运行conda install pytorch=1.1.0 -c pytorch即可。
此方法指定PyTorch版本后,conda会自动匹配到合适版本的CUDA Toolkit。
(3)同时指定CUDA Toolkit版本和PyTorch(推荐)
根据表一查询到可安装的CUDA Toolkit版本,根据表二查询到合适版本的PyTorch。
运行conda install pytorch=1.1.0 cudatoolkit=9.0 -c pytorch即可。
注:PyTorch1.8.0和1.0.0以前版本使用conda安装时命令有些许不同,具体可查看官网。
4.验证安装是否成功
#使用python运行 import torch print(torch.__version__) print(torch.cuda.is_available())
卸载当前版本PyTorch:
conda uninstall pytorch
补充:查看PyTorch的版本及CUDA和cuDNN版本
检查PyTorch版本
torch.version # PyTorch version torch.version.cuda # Corresponding CUDA version torch.backends.cudnn.version() # Corresponding cuDNN version torch.cuda.get_device_name(0) # GPU type
更新PyTorch
conda update pytorch torchvision -c pytorch
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
pytorch 查看cuda 版本方式
由于pytorch的whl 安装包名字都一样,所以我们很难区分到底是基于cuda 的哪个版本. 有一条指令可以查看 import torch print(torch.version.cuda) 补充知识:pytorch:网络定义参数的时候后面不能加".cuda()" pytorch定义网络__init__()的时候,参数不能加"cuda()", 不然参数不包含在state_dict()中,比如下面这种写法是错误的 self.W1 = nn.Parameter(tor
-
Pytorch 使用不同版本的cuda的方法步骤
由于课题的原因,笔者主要通过 Pytorch 框架进行深度学习相关的学习和实验.在运行和学习网络上的 Pytorch 应用代码的过程中,不少项目会标注作者在运行和实验时所使用的 Pytorch 和 cuda 版本信息.由于 Pytorch 和 cuda 版本的更新较快,可能出现程序的编译和运行需要之前版本的 Pytorch 和 cuda 进行运行环境支持的情况.比如笔者遇到的某个项目中编写了 CUDAExtension 拓展,而其中使用的 cuda 接口函数在新版本的 cuda 中做了修改,使得
-
浅谈pytorch、cuda、python的版本对齐问题
在使用深度学习模型训练的过程中,工具的准备也算是一个良好的开端吧.熟话说完事开头难,磨刀不误砍柴工,先把前期的问题搞通了,能为后期节省不少精力. 以pytorch工具为例: pytorch版本为1.0.1,自带python版本为3.6.2 服务器上GPU的CUDA_VERSION=9000 注意:由于GPU上的CUDA_VERSION为9000,所以至少要安装cuda版本>=9.0,虽然cuda=7.0~8.0也能跑,但是一开始可能会遇到各种各样的问题,本人cuda版本为10.0,安装cuda的
-

解决PyTorch与CUDA版本不匹配的问题
1.CUDA驱动和CUDA Toolkit对应版本 表一:CUDA驱动及CUDA Toolkit最高对应版本 最新可查阅官方文档 注:驱动是向下兼容的,其决定了可安装的CUDA Toolkit的最高版本. 2.CUDA Toolkit版本及其可用PyTorch对应版本(参考官网) 表二:CUDA Toolkit版本及可用PyTorch对应关系 CUDAToolkit版本 可用PyTorch版本 7.5 0.4.1 ,0.3.0, 0.2.0,0.1.12-0.1.6 8.0 1.1.0,1.0.
-
解决pytorch 损失函数中输入输出不匹配的问题
一.pytorch 损失函数中输入输出不匹配问题 File "C:\Users\Rain\AppData\Local\Programs\Python\Anaconda.3.5.1\envs\python35\python35\lib\site-packages\torch\nn\modules\module.py", line 491, in __call__ result = self.forward(*input, **kwargs) File "C:\Users\Ra
-
pytorch model.cuda()花费时间很长的解决
解决方法之一: 如果pytorch在进行model.cuda()操作需要花费的时间很长,长到你怀疑GPU的速度了,那就是不正常的. 如果你用的pytorch版本是0.3.0,升级到0.3.1就好了! .cuda()加载时间很长的其他解决方法 方法一: pip install --upgrade --force-reinstall http://download.pytorch.org/whl/cu80/torch-0.2.0.post3-cp27-cp27mu-manylinux1_x86_64
-
.net框架(framework)版本不匹配的解决方法
在已安装了.net framework的计算机上部署用.net开发的程序时,若.net framework的版本不匹配,则提示:" .Net Framework Initialization Error – Unable to find a version of the runtime to run this application". 这时候有个简单的办法是,修改(如果没有则创建)程序xxx.exe所在目录的和xxx.exe同名的config文件--xxx.exe.config,使其
-
解决pytorch下出现multi-target not supported at的一种可能原因
在使用交叉熵损失函数的时候,target的形状应该是和label的形状一致或者是只有batchsize这一个维度的. 如果target是这样的[batchszie,1]就会出现上述的错误. 改一下试试,用squeeze()函数降低纬度, 如果不知道squeeze怎么用的, 可以参考这篇文章.pytorch下的unsqueeze和squeeze用法 这只是一种可能的原因. 补充:pytorch使用中遇到的问题 1. load模型参数文件时,提示torch.cuda.is_available() i
-
解决pytorch GPU 计算过程中出现内存耗尽的问题
Pytorch GPU运算过程中会出现:"cuda runtime error(2): out of memory"这样的错误.通常,这种错误是由于在循环中使用全局变量当做累加器,且累加梯度信息的缘故,用官方的说法就是:"accumulate history across your training loop".在默认情况下,开启梯度计算的Tensor变量是会在GPU保持他的历史数据的,所以在编程或者调试过程中应该尽力避免在循环中累加梯度信息. 下面举个栗子: 上代
-
解决Pytorch 训练与测试时爆显存(out of memory)的问题
Pytorch 训练时有时候会因为加载的东西过多而爆显存,有些时候这种情况还可以使用cuda的清理技术进行修整,当然如果模型实在太大,那也没办法. 使用torch.cuda.empty_cache()删除一些不需要的变量代码示例如下: try: output = model(input) except RuntimeError as exception: if "out of memory" in str(exception): print("WARNING: out of