Python CSS选择器爬取京东网商品信息过程解析
CSS选择器
目前,除了官方文档之外,市面上及网络详细介绍BeautifulSoup使用的技术书籍和博客软文并不多,而在这仅有的资料中介绍CSS选择器的少之又少。在网络爬虫的页面解析中,CCS选择器实际上是一把效率甚高的利器。虽然资料不多,但官方文档却十分详细,然而美中不足的是需要一定的基础才能看懂,而且没有小而精的演示实例。
京东商品图
首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求。在这里小编仍以关键词“狗粮”作为搜索对象,之后得到后面这一串网址:
https://search.jd.com/Search?keyword=%E7%8B%97%E7%B2%AE&enc=utf-8,其中参数的意思就是我们输入的keyword,在本例中该参数代表“狗粮”,具体详情可以参考Python大神用正则表达式教你搞定京东商品信息。所以,只要输入keyword这个参数之后,将其进行编码,就可以获取到目标URL。之后请求网页,得到响应,尔后利用CSS选择器进行下一步的数据采集。
商品信息在京东官网上的部分网页源码如下图所示:
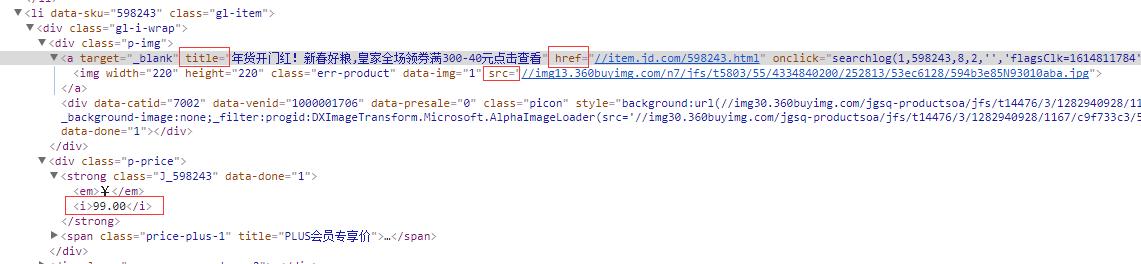
部分网页源码
仔细观察源码,可以发现我们所需的目标信息在红色框框的下面,那么接下来我们就要一层一层的去获取想要的信息。
在Python的urllib库中提供了quote方法,可以实现对URL的字符串进行编码,从而可以进入到对应的网页中去。

CSS选择器在线复制
很多小伙伴都觉得CSS表达式很难写,其实掌握了基本的用法也就不难了。在线复制CSS表达式如上图所示,可以很方便的复制CSS表达式。但是通过该方法得到的CSS表达式放在程序中一般不能用,而且长的没法看。所以CSS表达式一般还是要自己亲自上手。
直接上代码,利用CSS去提取目标信息,如商品的名字、链接、图片和价格,具体的代码如下图所示:

代码实现
如果你想快速的实现功能更强大的网络爬虫,那么BeautifulSoupCSS选择器将是你必备的利器之一。BeautifulSoup整合了CSS选择器的语法和自身方便使用API。在网络爬虫的开发过程中,对于熟悉CSS选择器语法的人,使用CSS选择器是个非常方便的方法。
最后得到的效果图如下所示:
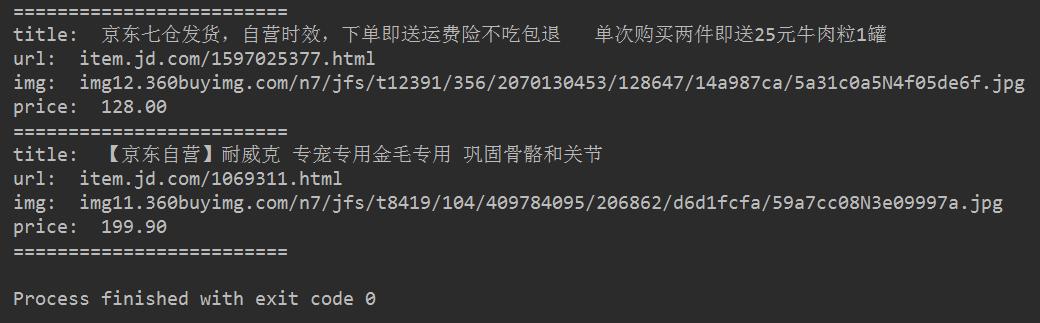
最终效果图
新鲜的狗粮再一次出炉咯~~~

CSS选择器
关于CSS选择器的简单介绍:
BeautifulSoup支持大部分的CSS选择器。其语法为:向tag对象或BeautifulSoup对象的.select()方法中传入字符串参数,选择的结果以列表形式返回,即返回类型为list。
tag.select("string")
BeautifulSoup.select("string")
注意:在取得含有特定CSS属性的元素时,标签名不加任何修饰,如class类名前加点,id名前加 /#。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python利用Xpath选择器爬取京东网商品信息
HTML文件其实就是由一组尖括号构成的标签组织起来的,每一对尖括号形式一个标签,标签之间存在上下关系,形成标签树:XPath 使用路径表达式在 XML 文档中选取节点.节点是通过沿着路径或者 step 来选取的. 首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求.在这里小编仍以关键词"狗粮"作为搜索对象,之后得到后面这一串网址: https://search.jd.com/Search?keyword=%E7%8B%97%E7%B2%AE&enc=utf-8,其中参
-
Python格式化css文件的方法
本文实例讲述了Python格式化css文件的方法.分享给大家供大家参考.具体实现方法如下: import string, sys import re, StringIO TAB=4 def format(ss): f = open (ss, "r") data = f.read() f.close() dlen = len(data) i = 0 buf = StringIO.StringIO() start = 0 while i < dlen: if data[i] == '
-
python2.7的flask框架之引用js&css等静态文件的实现方法
动态 web 应用也会需要静态文件,通常是 CSS 和 JavaScript 文件.理想状况下, 我们已经配置好 Web 服务器来提供静态文件,但是在开发中,Flask 也可以做到. 只要在我们的包中或是模块的所在目录中创建一个名为 static 的文件夹,在应用中使用 /static 即可访问.我们要给静态文件生成 URL ,需要使用特殊的 'static' 端点名: url_for('static', filename='style.css') 这个css文件应该存储在文件系统上的 stat
-
Python网络爬虫四大选择器用法原理总结
前几天小编连续写了四篇关于Python选择器的文章,分别用正则表达式.BeautifulSoup.Xpath.CSS选择器分别抓取京东网的商品信息.今天小编来给大家总结一下这四个选择器,让大家更加深刻的理解和熟悉Python选择器. 一.正则表达式 正则表达式为我们提供了抓取数据的快捷方式.虽然该正则表达式更容易适应未来变化,但又存在难以构造.可读性差的问题.当在爬京东网的时候,正则表达式如下图所示: 利用正则表达式实现对目标信息的精准采集 此外 ,我们都知道,网页时常会产生变更,导致网页中会发
-
Python脚本实现格式化css文件
最近研究研究了css,少不了去网上分析一下别人的网页, 但很多网站的css文件都是要么写在一行,要么一个换行都没有,看起来极其痛苦,所以写一个脚本转换一下,转换为比较有可读性的格式.下面就是这个脚本: import string, sys import re, StringIO TAB=4 def format(ss): f = open (ss, "r") data = f.read() f.close() dlen = len(data) i = 0 buf = StringIO.
-
Python之Django自动实现html代码(下拉框,数据选择)
我就废话不多说了,还是直接看代码吧! #模板 class IndexForm(forms.Form): # 模板,用户提交的name和这里的变量名一定要是一致的.否则不能获取数据 user = forms.CharField(min_length=6, error_messages={'required': '用户名不能为空', 'min_length': '用户名长度不能小于6'}) email = forms.EmailField(error_messages={'required': '邮
-
python3 selenium自动化测试 强大的CSS定位方法
ccs的优点:css相对xpath语法比xpath简洁,定位速度比xpath快 css的缺点:css不支持用逻辑运算符来定位,而xpath支持.css定位语法形式多样,相对xpath比较难记. css定位建议多用,这个定位方式很强大,定位速度快且准确度高.至于难记,用熟了就好了,对勤快的人来说,这不是问题. CSS_selector常用符号: # 表示id . 表示class > 表示子元素,层级 1.通过id属性定位: find_element_by_css_selector("#id的
-

使用Python抓取模板之家的CSS模板
Python版本是2.7.9,在win8上测试成功,就是抓取有点慢,本来想用多线程的,有事就罢了.模板之家的网站上的url参数与页数不匹配,懒得去做分析了,就自己改代码中的url吧.大神勿喷! 复制代码 代码如下: #!/usr/bin/env python # -*- coding: utf-8 -*- # by ustcwq # 2015-03-15 import urllib,urllib2,os,time from bs4 import BeautifulSoup start =
-
Python CSS选择器爬取京东网商品信息过程解析
CSS选择器 目前,除了官方文档之外,市面上及网络详细介绍BeautifulSoup使用的技术书籍和博客软文并不多,而在这仅有的资料中介绍CSS选择器的少之又少.在网络爬虫的页面解析中,CCS选择器实际上是一把效率甚高的利器.虽然资料不多,但官方文档却十分详细,然而美中不足的是需要一定的基础才能看懂,而且没有小而精的演示实例. 京东商品图 首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求.在这里小编仍以关键词"狗粮"作为搜索对象,之后得到后面这一串网址: https://s
-
c#爬虫爬取京东的商品信息
前言 在一个小项目中,需要用到京东的所有商品ID,因此就用c#写了个简单的爬虫. 在解析HTML中没有使用正则表达式,而是借助开源项目HtmlAgilityPack解析HTML. 下面话不多说了,来一起看看详细的介绍吧 一.下载网页HTML 首先我们写一个公共方法用来下载网页的HTML. 在写下载HTML方法之前,我们需要去查看京东网页请求头的相关信息,在发送请求时需要用到. public static string DownloadHtml(string url, Encoding encod
-
Python使用scrapy爬取阳光热线问政平台过程解析
目的:爬取阳光热线问政平台问题反映每个帖子里面的标题.内容.编号和帖子url CrawlSpider版流程如下: 创建爬虫项目dongguang scrapy startproject dongguang 设置items.py文件 # -*- coding: utf-8 -*- import scrapy class NewdongguanItem(scrapy.Item): # define the fields for your item here like: # name = scrapy
-
Python基于BeautifulSoup爬取京东商品信息
今天小编利用美丽的汤来为大家演示一下如何实现京东商品信息的精准匹配~~ HTML文件其实就是由一组尖括号构成的标签组织起来的,每一对尖括号形式一个标签,标签之间存在上下关系,形成标签树:因此可以说Beautiful Soup库是解析.遍历.维护"标签树"的功能库. 如何利用BeautifulSoup抓取京东网商品信息 首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求.在这里小编仍以关键词"狗粮"作为搜索对象,之后得到后面这一串网址: https://se
-
python利用urllib实现爬取京东网站商品图片的爬虫实例
本例程使用urlib实现的,基于python2.7版本,采用beautifulsoup进行网页分析,没有第三方库的应该安装上之后才能运行,我用的IDE是pycharm,闲话少说,直接上代码! # -*- coding: utf-8 -* import re import os import urllib import urllib2 from bs4 import BeautifulSoup def craw(url,page): html1=urllib2.urlopen(url).read(
-
python 爬取京东指定商品评论并进行情感分析
项目地址 https://github.com/DA1YAYUAN/JD-comments-sentiment-analysis 爬取京东商城中指定商品下的用户评论,对数据预处理后基于SnowNLP的sentiment模块对文本进行情感分析. 运行环境 Mac OS X Python3.7 requirements.txt Pycharm 运行方法 数据爬取(jd.comment.py) 启动jd_comment.py,建议修改jd_comment.py中变量user-agent为自己浏览器用户
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
python基于scrapy爬取京东笔记本电脑数据并进行简单处理和分析
一.环境准备 python3.8.3 pycharm 项目所需第三方包 pip install scrapy fake-useragent requests selenium virtualenv -i https://pypi.douban.com/simple 1.1 创建虚拟环境 切换到指定目录创建 virtualenv .venv 创建完记得激活虚拟环境 1.2 创建项目 scrapy startproject 项目名称 1.3 使用pycharm打开项目,将创建的虚拟环境配置到项目中来
-
Python爬虫实现爬取京东手机页面的图片(实例代码)
实例如下所示: __author__ = 'Fred Zhao' import requests from bs4 import BeautifulSoup import os from urllib.request import urlretrieve class Picture(): def __init__(self): self.headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleW