java8新特性之stream流中reduce()求和知识总结
1.stream().reduce()单字段求和
(1)普通数字求和
public static void test2(){
List<Integer> list= Arrays.asList(new Integer[]{1,2,3,4,5,6,7,8,9});
Integer sum=list.stream().reduce((x,y)->x+y).get();
System.out.println(sum);
}
2.BigDecimal求和
public static void main(String[] args) {
List<User> list=new ArrayList<>();
User user1=new User();
user1.setNum1(new BigDecimal(123));
user1.setNum2(new BigDecimal(100));
list.add(user1);
User user2=new User();
user2.setNum1(new BigDecimal(100));
user2.setNum2(new BigDecimal(100));
list.add(user2);
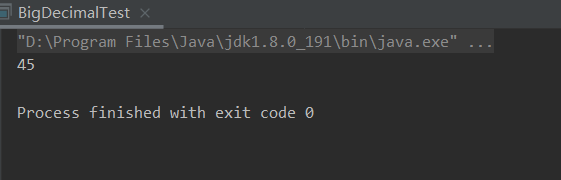
BigDecimal sum=list.stream().map(User::getNum1).reduce(BigDecimal::add).get();
System.out.println(sum);
}
结果:
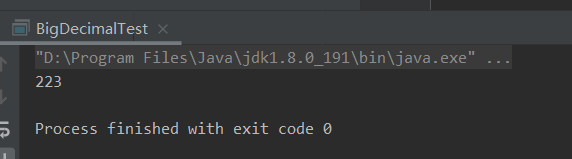
但是如果列表是中没有数据list.size()==0的时候会报错,所以需要将代码修改成如下:
BigDecimal sum=list.stream() .map(User::getNum1) //返回num1的列表 .reduce(BigDecimal.ZERO,BigDecimal::add); //列表字段求和
当list中没有元素的时候就默认返回0;
2.stream().reduce()多字段求和
public static void main(String[] args) {
List<User> list=new ArrayList<>();
User user1=new User();
user1.setNum1(new BigDecimal(123));
user1.setNum2(new BigDecimal(100));
list.add(user1);
User user2=new User();
user2.setNum1(new BigDecimal(100));
user2.setNum2(new BigDecimal(100));
list.add(user2);
User u=list.stream().reduce((x,y)->{
User user=new User();
user.setNum1(x.getNum1().add(y.getNum1()));
user.setNum2(x.getNum2().add(y.getNum2()));
return user;
}).get();
System.out.println(u.getNum1()+"------------"+u.getNum2());
}
结果:
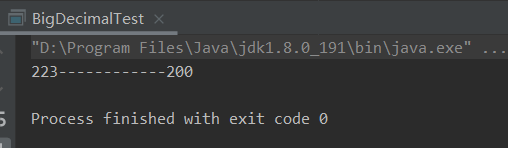
同样,如果list中没有元素,则使用如下方式:
User u=list.stream().reduce(new User(),(x,y)->{
User user=new User();
user.setNum1(x.getNum1().add(y.getNum1()));
user.setNum2(x.getNum2().add(y.getNum2()));
return user;
});
默认给一个User对象,就不会报错。
总结
有三个参数类型,本文只说了前两个
1.一个参数:Optional reduce(BinaryOperator accumulator),传入求和函数式,
2.两个参数:T reduce(T identity, BinaryOperator accumulator),(默认值,求和函数式)
3.三个参数的没怎么用过,暂不说明
到此这篇关于java8新特性之stream流中reduce()求和知识总结的文章就介绍到这了,更多相关java reduce()求和内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
java 矩阵乘法的mapreduce程序实现
java 矩阵乘法的mapreduce程序实现 map函数:对于矩阵M中的每个元素m(ij),产生一系列的key-value对<(i,k),(M,j,m(ij))> 其中k=1,2.....知道矩阵N的总列数;对于矩阵N中的每个元素n(jk),产生一系列的key-value对<(i , k) , (N , j ,n(jk)>, 其中i=1,2.......直到i=1,2.......直到矩阵M的总列数. map package com.cb.matrix; import stati
-
java8 利用reduce实现将列表中的多个元素的属性求和并返回操作
利用java8流的特性,我们可以实现list中多个元素的 属性求和 并返回. 案例: 有一个借款待还信息列表,其中每一个借款合同包括:本金.手续费: 现在欲将 所有的本金求和.所有的手续费求和. 我们可以使用java8中的函数式编程,获取list的流,再利用reduce遍历递减方式将同属性(本金.手续费)求和赋予给一个新的list中同类型的对象实例,即得到我们需要的结果: A a = list.stream() .reduce( (x , y) -> new A( (x.getPrincipal
-
java连接hdfs ha和调用mapreduce jar示例
Java API 连接 HDFS HA 复制代码 代码如下: public static void main(String[] args) { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://hadoop2cluster"); conf.set("dfs.nameservices", "hadoop2cluster");
-

Java/Web调用Hadoop进行MapReduce示例代码
Hadoop环境搭建详见此文章http://www.jb51.net/article/33649.htm. 我们已经知道Hadoop能够通过Hadoop jar ***.jar input output的形式通过命令行来调用,那么如何将其封装成一个服务,让Java/Web来调用它?使得用户可以用方便的方式上传文件到Hadoop并进行处理,获得结果.首先,***.jar是一个Hadoop任务类的封装,我们可以在没有jar的情况下运行该类的main方法,将必要的参数传递给它.input 和outpu
-
JAVA8 stream中三个参数的reduce方法对List进行分组统计操作
背景 平时在编写前端代码时,习惯使用lodash来编写'野生'的JavaScript; lodash提供来一套完整的API对JS对象(Array,Object,Collection等)进行操作,这其中就包括_.groupBy 和 _.reduce,即分组和'聚合'(reduce不知道该怎么翻译合适). 使用这些'野生'的API能够极大的提高我本人编写JS代码的效率.而JAVA8开始支持stream和lambda表达式,这些和lodash的API有很多类似的功能.因此我在熟悉lodash的前提下尝
-
Java基础之MapReduce框架总结与扩展知识点
一.MapTask工作机制 MapTask就是Map阶段的job,它的数量由切片决定 二.MapTask工作流程: 1.Read阶段:读取文件,此时进行对文件数据进行切片(InputFormat进行切片),通过切片,从而确定MapTask的数量,切片中包含数据和key(偏移量) 2.Map阶段:这个阶段是针对数据进行map方法的计算操作,通过该方法,可以对切片中的key和value进行处理 3.Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputColle
-
java8 Stream API之reduce使用说明
本篇我们只讲reduce. reduce的作用是把stream中的元素给组合起来. 至于怎么组合起来:它需要我们首先提供一个起始种子,然后依照某种运算规则使其与stream的第一个元素发生关系产生一个新的种子,这个新的种子再紧接着与stream的第二个元素发生关系产生又一个新的种子,就这样依次递归执行,最后产生的结果就是reduce的最终产出,这就是reduce的算法最通俗的描述: 那么结合实际的业务场景来说,运用reduce我们可以做sum,min,max,average,所以这些我们称之为针
-
Java 8系列之Stream中万能的reduce用法说明
reduce 操作可以实现从Stream中生成一个值,其生成的值不是随意的,而是根据指定的计算模型.比如,之前提到count.min和max方法,因为常用而被纳入标准库中.事实上,这些方法都是reduce操作. reduce方法有三个override的方法: Optional<T> reduce(BinaryOperator<T> accumulator); T reduce(T identity, BinaryOperator<T> accumulator); <
-
Java函数式编程(七):MapReduce
译注:map(映射)和reduce(归约,化简)是数学上两个很基础的概念,它们很早就出现在各类的函数编程语言里了,直到2003年Google将其发扬光大,运用到分布式系统中进行并行计算后,这个组合的名字才开始在计算机界大放异彩(那些函数式粉可能并不这么认为).本文我们会看到Java 8在摇身一变支持函数式编程后,map和reduce组合的首次亮相(这里只是初步介绍,后续还会有针对它们的专题). 对集合进行归约 现在为止我们已经介绍了几个操作集合的新技巧了:查找匹配元素,查找单个元素,集合转化.这
-
java8新特性之stream流中reduce()求和知识总结
1.stream().reduce()单字段求和 (1)普通数字求和 public static void test2(){ List<Integer> list= Arrays.asList(new Integer[]{1,2,3,4,5,6,7,8,9}); Integer sum=list.stream().reduce((x,y)->x+y).get(); System.out.println(sum); } 2.BigDecimal求和 public static void m
-
深入理解Java8新特性之Stream API的终止操作步骤
目录 1.写在前面 2.终止操作 2.1 终止操作之查找与匹配 2.2 终止操作之归约与收集 1.写在前面 承接了上一篇文章(说完了Stream API的创建方式及中间操作):深入理解Java8新特性之Stream API的创建方式和中间操作步骤. 我们都知道Stream API完成的操作是需要三步的:创建Stream → 中间操作 → 终止操作.那么这篇文章就来说一下终止操作. 2.终止操作 终端操作会从流的流水线生成结果.其结果可以是任何不是流的值,例如:List.Integer,甚至是 v
-
java8新特性之stream的collect实战教程
1.list转换成list 不带return方式 List<Long> ids=wrongTmpList.stream().map(c->c.getId()).collect(Collectors.toList()); 带return方式 // spu集合转化成spubo集合//java8的新特性 List<SpuBo> spuBos=spuList.stream().map(spu -> { SpuBo spuBo = new SpuBo(); BeanUtils.c
-
深入理解Java8新特性之Stream API的创建方式和中间操作步骤
目录 1.什么是StreamAPI? 2.Stream API操作的三个步骤 2.1 创建Stream 2.2 中间操作 2.2.1 中间操作之筛选与切片 2.2.2 中间操作之映射 2.2.3 中间操作之排序 1.什么是StreamAPI? Java8中有两大最为重要的改变.第一个是 Lambda 表达式:另外一个则是 m Stream API (java.util.stream.*) . Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复
-
熟练掌握Java8新特性之Stream API的全面应用
1.写在前面 关于Stream API的内容,已经基本上说完了.大家可以参考我的这两篇文章: 深入理解Java8新特性之Stream API的创建方式和中间操作步骤.深入理解Java8新特性之Stream API的终止操作步骤 那么这篇文章主要就是说一个Stream API的简单应用练习题. 2.应用举例 首先,我们需要创建一个交易员类.交易类.存储这两个类对象的List集合. package com.szh.java8.exer; import lombok.AllArgsConstructo
-
Java8新特性之Stream API详解
一.前言 StreamAPI在Java8版本中使用,关注的是对数据的筛选.查找.存储等 它可以做的事情有:过滤.排序.映射.归约 二.使用流程 Stream实例化中间操作(过滤.排序.映射.规约)终止操作(匹配查找.归约.收集) 三.案例演示 public class EmployeeData { public static List<Employee> getEmployees(){ List<Employee> list = new ArrayList<>(); l
-
Java关于JDK1.8新特性的Stream流
目录 Java 的Stream流 一.定义 二.操作的特征 三.代码示例 1.生成流 2.forEach 迭代 3.limit方法用于获取指定数量的流 4.map 5.sorted 6.并行(parallel)程序 7.Collectors 8.转化(将枚举类转成map) Java 的Stream流 一.定义 JDK1.8 中增加了Stream流,Stream流是一个来自数据源的元素队列并支持聚合操作.元素是特定类型的对象,形成一个队列,Java中的Stream并不会存储元素,而是按需计算数据源
-
Java8新特性Stream流实例详解
什么是Stream流? Stream流是数据渠道,用于操作数据源(集合.数组等)所生成的元素序列. Stream的优点:声明性,可复合,可并行.这三个特性使得stream操作更简洁,更灵活,更高效. Stream的操作有两个特点:可以多个操作链接起来运行,内部迭代. Stream可分为并行流与串行流,Stream API 可以声明性地通过 parallel() 与sequential() 在并行流与顺序流之间进行切换.串行流就不必再细说了,并行流主要是为了为了适应目前多核机器的时代,提高系统CP
-
java8新特性 stream流的方式遍历集合和数组操作
前言: 在没有接触java8的时候,我们遍历一个集合都是用循环的方式,从第一条数据遍历到最后一条数据,现在思考一个问题,为什么要使用循环,因为要进行遍历,但是遍历不是唯一的方式,遍历是指每一个元素逐一进行处理(目的),而并不是从第一个到最后一个顺次处理的循环,前者是目的,后者是方式. 所以为了让遍历的方式更加优雅,出现了流(stream)! 1.流的目的在于强掉做什么 假设一个案例:将集合A根据条件1过滤为子集B,然后根据条件2过滤为子集C 在没有引入流之前我们的做法可能为: public cl
-
Java8新特性Stream的完全使用指南
什么是Stream Stream是Java 1.8版本开始提供的一个接口,主要提供对数据集合使用流的方式进行操作,流中的元素不可变且只会被消费一次,所有方法都设计成支持链式调用.使用Stream API可以极大生产力,写出高效率.干净.简洁的代码. 如何获得Stream实例 Stream提供了静态构建方法,可以基于不同的参数创建返回Stream实例 使用Collection的子类实例调用stream()或者parallelStream()方法也可以得到Stream实例,两个方法的区别在于后续执行