聊聊Pytorch torch.cat与torch.stack的区别
torch.cat()函数可以将多个张量拼接成一个张量。torch.cat()有两个参数,第一个是要拼接的张量的列表或是元组;第二个参数是拼接的维度。
torch.cat()的示例如下图1所示
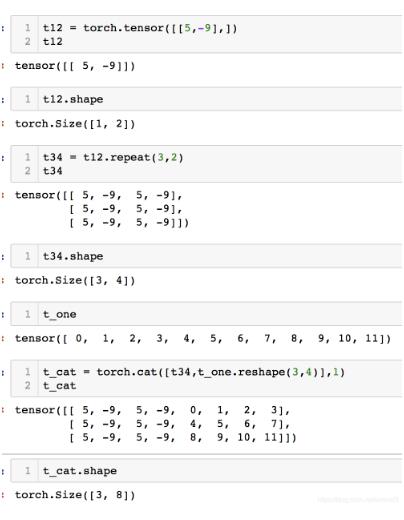
图1 torch.cat()
torch.stack()函数同样有张量列表和维度两个参数。stack与cat的区别在于,torch.stack()函数要求输入张量的大小完全相同,得到的张量的维度会比输入的张量的大小多1,并且多出的那个维度就是拼接的维度,那个维度的大小就是输入张量的个数。
torch.stack()的示例如下图2所示:

图2 torch.stack()
补充:torch.stack()的官方解释,详解以及例子
可以直接看最下面的【3.例子】,再回头看前面的解释
在pytorch中,常见的拼接函数主要是两个,分别是:
1、stack()
2、cat()
实际使用中,这两个函数互相辅助:关于cat()参考torch.cat(),但是本文主要说stack()。
函数的意义:使用stack可以保留两个信息:[1. 序列] 和 [2. 张量矩阵] 信息,属于【扩张再拼接】的函数。
形象的理解:假如数据都是二维矩阵(平面),它可以把这些一个个平面(矩阵)按第三维(例如:时间序列)压成一个三维的立方体,而立方体的长度就是时间序列长度。
该函数常出现在自然语言处理(NLP)和图像卷积神经网络(CV)中。
1. stack()
官方解释:沿着一个新维度对输入张量序列进行连接。 序列中所有的张量都应该为相同形状。
浅显说法:把多个2维的张量凑成一个3维的张量;多个3维的凑成一个4维的张量…以此类推,也就是在增加新的维度进行堆叠。
outputs = torch.stack(inputs, dim=?) → Tensor
参数
inputs : 待连接的张量序列。
注:python的序列数据只有list和tuple。
dim : 新的维度, 必须在0到len(outputs)之间。
注:len(outputs)是生成数据的维度大小,也就是outputs的维度值。
2. 重点
函数中的输入inputs只允许是序列;且序列内部的张量元素,必须shape相等
----举例:[tensor_1, tensor_2,..]或者(tensor_1, tensor_2,..),且必须tensor_1.shape == tensor_2.shape
dim是选择生成的维度,必须满足0<=dim<len(outputs);len(outputs)是输出后的tensor的维度大小
不懂的看例子,再回过头看就懂了。
3. 例子
1.准备2个tensor数据,每个的shape都是[3,3]
# 假设是时间步T1的输出
T1 = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 假设是时间步T2的输出
T2 = torch.tensor([[10, 20, 30],
[40, 50, 60],
[70, 80, 90]])
2.测试stack函数
print(torch.stack((T1,T2),dim=0).shape) print(torch.stack((T1,T2),dim=1).shape) print(torch.stack((T1,T2),dim=2).shape) print(torch.stack((T1,T2),dim=3).shape) # outputs: torch.Size([2, 3, 3]) torch.Size([3, 2, 3]) torch.Size([3, 3, 2]) '选择的dim>len(outputs),所以报错' IndexError: Dimension out of range (expected to be in range of [-3, 2], but got 3)
可以复制代码运行试试:拼接后的tensor形状,会根据不同的dim发生变化。
| dim | shape |
|---|---|
| 0 | [2, 3, 3] |
| 1 | [3, 2, 3] |
| 2 | [3, 3, 2] |
| 3 | 溢出报错 |
4. 总结
1、函数作用:
函数stack()对序列数据内部的张量进行扩维拼接,指定维度由程序员选择、大小是生成后数据的维度区间。
2、存在意义:
在自然语言处理和卷及神经网络中, 通常为了保留–[序列(先后)信息] 和 [张量的矩阵信息] 才会使用stack。
函数存在意义?》》》
手写过RNN的同学,知道在循环神经网络中输出数据是:一个list,该列表插入了seq_len个形状是[batch_size, output_size]的tensor,不利于计算,需要使用stack进行拼接,保留–[1.seq_len这个时间步]和–[2.张量属性[batch_size, output_size]]。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
PyTorch的torch.cat用法
1. 字面理解: torch.cat是将两个张量(tensor)拼接在一起,cat是concatnate的意思,即拼接,联系在一起. 2. 例子理解 >>> import torch >>> A=torch.ones(2,3) #2x3的张量(矩阵) >>> A tensor([[ 1., 1., 1.], [ 1., 1., 1.]]) >>> B=2*torch.ones(4,3)#4x3的张量(矩阵) >>>
-
PyTorch中torch.tensor与torch.Tensor的区别详解
PyTorch最近几年可谓大火.相比于TensorFlow,PyTorch对于Python初学者更为友好,更易上手. 众所周知,numpy作为Python中数据分析的专业第三方库,比Python自带的Math库速度更快.同样的,在PyTorch中,有一个类似于numpy的库,称为Tensor.Tensor自称为神经网络界的numpy. 一.numpy和Tensor二者对比 对比项 numpy Tensor 相同点 可以定义多维数组,进行切片.改变维度.数学运算等 可以定义多维数组,进行切片.改变
-
对PyTorch torch.stack的实例讲解
不是concat的意思 import torch a = torch.ones([1,2]) b = torch.ones([1,2]) torch.stack([a,b],1) (0 ,.,.) = 1 1 1 1 [torch.FloatTensor of size 1x2x2] 以上这篇对PyTorch torch.stack的实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
浅谈pytorch中stack和cat的及to_tensor的坑
初入计算机视觉遇到的一些坑 1.pytorch中转tensor x=np.random.randint(10,100,(10,10,10)) x=TF.to_tensor(x) print(x) 这个函数会对输入数据进行自动归一化,比如有时候我们需要将0-255的图片转为numpy类型的数据,则会自动转为0-1之间 2.stack和cat之间的差别 stack x=torch.randn((1,2,3)) y=torch.randn((1,2,3)) z=torch.stack((x,y))#默
-

聊聊Pytorch torch.cat与torch.stack的区别
torch.cat()函数可以将多个张量拼接成一个张量.torch.cat()有两个参数,第一个是要拼接的张量的列表或是元组:第二个参数是拼接的维度. torch.cat()的示例如下图1所示 图1 torch.cat() torch.stack()函数同样有张量列表和维度两个参数.stack与cat的区别在于,torch.stack()函数要求输入张量的大小完全相同,得到的张量的维度会比输入的张量的大小多1,并且多出的那个维度就是拼接的维度,那个维度的大小就是输入张量的个数. torch.st
-
PyTorch中的torch.cat简单介绍
目录 1.toych简单介绍 2.张量Tensors 3.torch.cat 1.toych简单介绍 包torch包含了多维疑是的数据结构及基于其上的多种数学操作. torch包含了多维张量的数据结构以及基于其上的多种数学运算.此外,它也提供了多种实用工具,其中一些可以更有效地对张量和任意类型进行序列化的工具. 它具有CUDA的对应实现,可以在NVIDIA GPU上进行张量运算(计算能力>=3.0) 2. 张量Tensors torch.is_tensor(obj):如果obj是一个pytorc
-
简单聊聊PyTorch里面的torch.nn.Parameter()
在刷官方Tutorial的时候发现了一个用法self.v = torch.nn.Parameter(torch.FloatTensor(hidden_size)),看了官方教程里面的解释也是云里雾里,于是在栈溢网看到了一篇解释,并做了几个实验才算完全理解了这个函数.首先可以把这个函数理解为类型转换函数,将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在
-
pytorch:torch.mm()和torch.matmul()的使用
如下所示: torch.mm(mat1, mat2, out=None) → Tensor torch.matmul(mat1, mat2, out=None) → Tensor 对矩阵mat1和mat2进行相乘. 如果mat1 是一个n×m张量,mat2 是一个 m×p 张量,将会输出一个 n×p 张量out. 参数 : mat1 (Tensor) – 第一个相乘矩阵 mat2 (Tensor) – 第二个相乘矩阵 out (Tensor, optional) – 输出张量 代码示例: imp
-
Pytorch中torch.flatten()和torch.nn.Flatten()实例详解
torch.flatten(x)等于torch.flatten(x,0)默认将张量拉成一维的向量,也就是说从第一维开始平坦化,torch.flatten(x,1)代表从第二维开始平坦化. import torch x=torch.randn(2,4,2) print(x) z=torch.flatten(x) print(z) w=torch.flatten(x,1) print(w) 输出为: tensor([[[-0.9814, 0.8251], [ 0.8197, -1.0426], [-
-
基于PyTorch的permute和reshape/view的区别介绍
二维的情况 先用二维tensor作为例子,方便理解. permute作用为调换Tensor的维度,参数为调换的维度.例如对于一个二维Tensor来说,调用tensor.permute(1,0)意为将1轴(列轴)与0轴(行轴)调换,相当于进行转置. In [20]: a Out[20]: tensor([[0, 1, 2], [3, 4, 5]]) In [21]: a.permute(1,0) Out[21]: tensor([[0, 3], [1, 4], [2, 5]]) 如果使用view(
-
pytorch中的matmul与mm,bmm区别说明
pytorch中matmul和mm和bmm区别 matmulmmbmm结论 先看下官网上对这三个函数的介绍. matmul mm bmm 顾名思义, 就是两个batch矩阵乘法. 结论 从官方文档可以看出 1.mm只能进行矩阵乘法,也就是输入的两个tensor维度只能是( n × m ) (n\times m)(n×m)和( m × p ) (m\times p)(m×p) 2.bmm是两个三维张量相乘, 两个输入tensor维度是( b × n × m ) (b\times n\times m
-
pytorch常用函数之torch.randn()解读
目录 pytorch常用函数torch.randn() pytorch torch.chunk(tensor, chunks, dim) 总结 pytorch常用函数torch.randn() torch.randn(*sizes, out=None) → Tensor 功能:从标准正态分布(均值为0,方差为1)中抽取的一组随机数.返回一个张量 sizes (int…) - 整数序列,定义输出张量的形状 out (Tensor, optinal) - 结果张量 eg: random = torc