Postgresql 查询表引用或被引用的外键操作
今天更新两个SQL。是用来查询PG中,主表被子表引用的外键,或子表引用了哪个主表的主键。
废话不多说,直接上实验!
CentOS 7 + PG 10
创建两个实验表,test01为主表,test02为子表,test02引用test01中的id列。
test=# create table test01( test(# id int primary key, test(# col1 varchar(20) test(# ); CREATE TABLE test=# create table test02( test(# id int primary key, test(# test01_id int references test01(id), test(# col1 varchar(20) test(# ); CREATE TABLE
插入数据
test=# insert into test01 values (1, 'a'); INSERT 0 1 test=# insert into test01 values (2, 'b'); INSERT 0 1 test=# insert into test01 values (3, 'c'); INSERT 0 1 test=# insert into test02 values (1, 1, 'a'); INSERT 0 1 test=# insert into test02 values (2, 1, 'a'); INSERT 0 1 test=# insert into test02 values (3, 1, 'a'); INSERT 0 1 test=# insert into test02 values (4, 2, 'b'); INSERT 0 1 test=# insert into test02 values (5, 2, 'b'); INSERT 0 1 test=# insert into test02 values (6, 11, 'b'); ERROR: insert or update on table "test02" violates foreign key constraint "test02_test01_id_fkey" DETAIL: Key (test01_id)=(11) is not present in table "test01".
查询主表被哪个子表引用。如果结果为空,说明没有任何子表引用的该表。
test=# SELECT tc.constraint_name, tc.table_name, # 子表 kcu.column_name, ccu.table_name AS foreign_table_name, # 主表 ccu.column_name AS foreign_column_name, tc.is_deferrable, tc.initially_deferred FROM information_schema.table_constraints AS tc JOIN information_schema.key_column_usage AS kcu ON tc.constraint_name = kcu.constraint_name JOIN information_schema.constraint_column_usage AS ccu ON ccu.constraint_name = tc.constraint_name where constraint_type = 'FOREIGN KEY' AND ccu.table_name='test01'; # 输入主表 constraint_name | table_name | column_name | foreign_table_name | foreign_column_name | is_deferrable | initially_deferred -----------------------+------------+-------------+--------------------+---------------------+---------------+-------------------- test02_test01_id_fkey | test02 | test01_id | test01 | id | NO | NO (1 row)
查询子表引用的哪个主表。如果结果为空,说明没有任何引用主表。
test=# SELECT tc.constraint_name, tc.table_name, # 子表 kcu.column_name, ccu.table_name AS foreign_table_name, ccu.column_name AS foreign_column_name, # 主表 tc.is_deferrable, tc.initially_deferred FROM information_schema.table_constraints AS tc JOIN information_schema.key_column_usage AS kcu ON tc.constraint_name = kcu.constraint_name JOIN information_schema.constraint_column_usage AS ccu ON ccu.constraint_name = tc.constraint_name WHERE constraint_type = 'FOREIGN KEY' AND tc.table_name='test02'; # 输入子表 constraint_name | table_name | column_name | foreign_table_name | foreign_column_name | is_deferrable | initially_deferred -----------------------+------------+-------------+--------------------+---------------------+---------------+-------------------- test02_test01_id_fkey | test02 | test01_id | test01 | id | NO | NO (1 row)
补充:PostgreSQL 外键引用查询
根据一个表名,查询所有外键引用它的表,以及那些外键的列名
key_column_usage(系统列信息表),
pg_constraint(系统所有约束表)
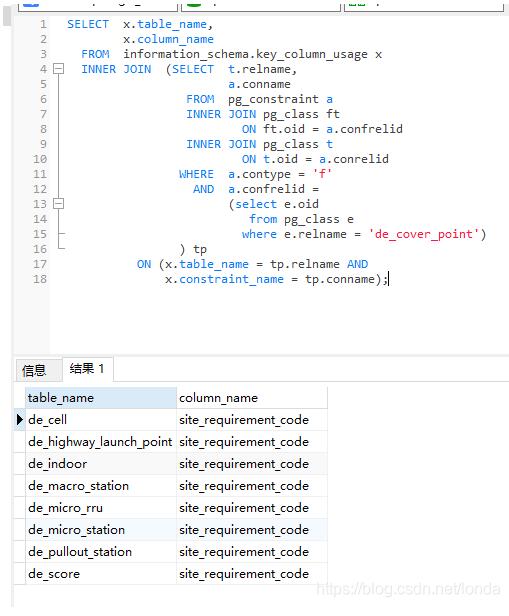
SELECT x.table_name,
x.column_name
FROM information_schema.key_column_usage x
INNER JOIN (SELECT t.relname,
a.conname
FROM pg_constraint a
INNER JOIN pg_class ft
ON ft.oid = a.confrelid
INNER JOIN pg_class t
ON t.oid = a.conrelid
WHERE a.contype = 'f'
AND a.confrelid =
(select e.oid
from pg_class e
where e.relname = 'xxx_table')
) tp
ON (x.table_name = tp.relname AND
x.constraint_name = tp.conname)
示例:
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

PostgreSql 的hash_code函数的用法说明
PostgreSql 实现的hash_code 函数与java hash_code方法一致 CREATE FUNCTION hash_code(text) RETURNS integer LANGUAGE plpgsql AS $$ DECLARE i integer := 0; DECLARE h bigint := 0; BEGIN FOR i IN 1..length($1) LOOP h = (h * 31 + ascii(substring($1, i, 1))) & 42949672
-
PostgreSql 重建索引的操作
PostgreSql数据库的重建索引时通过REINDEX命令来实现的,如reindexindex_name: 其语法是: REINDEX { INDEX | TABLE | DATABASE | SYSTEM } name [ FORCE ]; 下面解释下说明情况下需要: 1.当由于软件bug或者硬件原因导致的索引不再可用,索引的数据不再可用: 2.当索引包含许多空的或者近似于空的页,这个在b-tree索引会发生.Reindex会腾出空间释放哪些无用的页(页就是存放数据的一个单位,类似于bloc
-
PostgreSQL之INDEX 索引详解
之前总结了PostgreSQL的序列相关知识,今天总结下索引. 我们都知道,数据库索引最主要的作用是可以提高检索数据的速度,但是索引也不是越多越好.因为索引会增加数据库的存储空间,查询数据是要花较多的时间. 1.创建索引 SQL语句如下: CREATE INDEX idx_commodity ON commodity //表名 USING btree //用B树实现 (commodity_id); //作用的具体列 2.删除索引 DROP index idx_commodity; 3.增加索引的
-
PostgreSQL Sequence序列的使用详解
PostgreSQL是一种关系型数据库,和Oracle.MySQL一样被广泛使用.平时工作主要使用的是PostgreSQL,所以有必要对其相关知识做一下总结和掌握,先总结下序列. 一. Sequence序列 Sequence是一种自动增加的数字序列,一般作为行或者表的唯一标识,用作代理主键. 1.Sequence的创建 例子:创建一个seq_commodity,最小值为1,最大值为9223372036854775807,从1开始,增量的步长为1,缓存为1的循环排序Sequence. SQL语句如
-
postgresql 索引之 hash的使用详解
os: ubuntu 16.04 postgresql: 9.6.8 ip 规划 192.168.56.102 node2 postgresql help create index postgres=# \h create index Command: CREATE INDEX Description: define a new index Syntax: CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] name ] ON
-
Postgresql 查询表引用或被引用的外键操作
今天更新两个SQL.是用来查询PG中,主表被子表引用的外键,或子表引用了哪个主表的主键. 废话不多说,直接上实验! CentOS 7 + PG 10 创建两个实验表,test01为主表,test02为子表,test02引用test01中的id列. test=# create table test01( test(# id int primary key, test(# col1 varchar(20) test(# ); CREATE TABLE test=# create table test
-
PostgreSQL中enable、disable和validate外键约束的实例
我就废话不多说了,大家还是直接看实例吧~ postgres=# create table t1(a int primary key,b text,c date); CREATE TABLE postgres=# create table t2(a int primary key,b int references t1(a),c text); CREATE TABLE postgres=# insert into t1 (a,b,c) values(1,'aa',now()); INSERT 0
-
MySQL数据库外键 foreing key
目录 1.外键操作 1.1.增加外键 1.2.删除外键 1.3.外键的基本要求 2.外键约束 2.1.约束的基本概念 2.2.外键约束的概念 2.3.约束的作用 前言: 外键表示了两个实体之间的联系 外键 foreing key: A表中的一个字段的值指向另B表的主键 B: 主表 A: 从表 主表:主键(主关键字) = 从表:外键(外关键字) 1.外键操作 1.1.增加外键 基本语法: 方式一:创建表的时候增加外键 [constraint `外键名`] foreign key (外键字段) re
-
mysql主键,外键,非空,唯一,默认约束及创建表的方法
目录 一.操作前提 二.mysql创建/新建表 1.首先我们需要创建一个数据库: 2.然后进入这个数据库: 3.创建表: 4.查看表: 三.使用主键约束 1.单字段主键 2.多字段联合主键 四.使用外键约束 1.mysql中外键是什么? 2.什么是主表?什么是从表? 3.如何在mysql中创建外键呢? 五.使用非空约束 六.使用唯一性约束 七.使用默认约束 八.设置表的属性值自动增加 前言: 在数据库中,数据表是数据库中最重要.最基本的操作对象,是数据存储的基本单位.数据表被定义为列的集
-
Mysql添加外键的两种方式详解
目录 Mysql添加外键的几种方式 方法一: 方法二: 补充:MySQL 删除外键操作 总结 Mysql添加外键的几种方式 注意:添加外键是给从表添加(即子表)父表是主表 方法一: 创建表之前: FOREIGN KEY (子表id) REFERENCES 关联表名(外主表id) 例如 create table emp( e_id int auto_increment primary key, ename varchar(50) not null, age int, job varchar(20)
-
Django之Mode的外键自关联和引用未定义的Model方法
Django Model的外键自关联 在django的model定义中,有时需要某个Field引用当前定义的Model,比如一个部门(Department)的Model,它有一个字段是上级部门(super_department),上级部门应该是一个外键并引用Model Department,即: class Department(models.Model): ''' some other filed ''' super_department = models.ForeignKey(Departm
-
PostgreSQL 查看表的主外键等约束关系详解
我就废话不多说了,大家还是直接看代码吧~ SELECT tc.constraint_name, tc.table_name, kcu.column_name, ccu.table_name AS foreign_table_name, ccu.column_name AS foreign_column_name, tc.is_deferrable,tc.initially_deferred FROM information_schema.table_constraints AS tc JOIN
-
解析Android开发优化之:软引用与弱引用的应用
如果一个对象只具有软引用,那么如果内存空间足够,垃圾回收器就不会回收它:如果内存空间不足了,就会回收这些对象的内存.只要垃圾回收器没有回收它,该对象就可以被程序使用.软引用可用来实现内存敏感的高速缓存.软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中. 如果一个对象只具有弱引用,那么在垃圾回收器线程扫描的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存.不过
-
Android 软引用和弱引用详解及实例代码
Android 软引用 和 弱引用 1. SoftReference<T>:软引用-->当虚拟机内存不足时,将会回收它指向的对象:需要获取对象时,可以调用get方法. 2. WeakReference<T>:弱引用-->随时可能会被垃圾回收器回收,不一定要等到虚拟机内存不足时才强制回收.要获取对象时,同样可以调用get方法. 3. WeakReference一般用来防止内存泄漏,要保证内存被虚拟机回收,SoftReference多用作来实现缓存机制(cache
-
Android利用软引用和弱引用避免OOM的方法
想必很多朋友对OOM(OutOfMemory)这个错误不会陌生,而当遇到这种错误如何有效地解决这个问题呢?今天我们就来说一下如何利用软引用和弱引用来有效地解决程序中出现的OOM问题. 一.了解 强引用.软引用.弱引用.虚引用的概念 在Java中,虽然不需要程序员手动去管理对象的生命周期,但是如果希望某些对象具备一定的生命周期的话(比如内存不足时JVM就会自动回收某些对象从而避免OutOfMemory的错误)就需要用到软引用和弱引用了. 从Java SE2开始,就提供了四种类型的引用:强引用.软引