python人工智能tensorflow构建循环神经网络RNN
目录
- 学习前言
- RNN简介
- tensorflow中RNN的相关函数
- tf.nn.rnn_cell.BasicLSTMCell
- tf.nn.dynamic_rnn
- 全部代码
学习前言
在前一段时间已经完成了卷积神经网络的复习,现在要对循环神经网络的结构进行更深层次的明确。
RNN简介
RNN 是当前发展非常火热的神经网络中的一种,它擅长对序列数据进行处理。
什么是序列数据呢?举个例子。
现在假设有四个字,“我” “去” “吃” “饭”。我们可以对它们进行任意的排列组合。
“我去吃饭”,表示的就是我要去吃饭了。
“饭去吃我”,表示的就是饭成精了。
“我吃去饭”,表示的我要去吃‘去饭’了。
不同的排列顺序会导致不同的语意,序列数据表示的就是按照一定顺序排列的序列,这种排列一般存在一定的意义。。
所以我们知道了RNN有顺序存储的这个抽象概念,但是RNN如何学习这个概念呢?
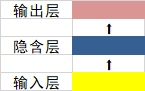
那么,让我们来看一个传统的神经网络,也称为前馈神经网络。它有输入层,隐藏层和输出层。就像这样
对于RNN来讲,其结构示意图是这样的:
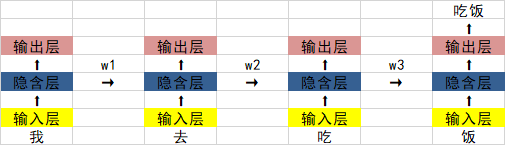
一句话可以分为N个part,比如“我去吃饭”可以分为四个字,“我” “去” “吃” “饭”,分别可以传入四个隐含层,前一个隐含层会有一个输出按照一定的比率传给后一个隐含层,比如第一个“我”输入隐含层后,有一个输出按照w1的比率输入给下一个隐含层,当第二个“去”进入隐含层时,隐含层同样要接收“我”传过来的信息。
以此类推,在到达最后一个“饭”时,最后的输出便得到了前面全部的信息。
其伪代码形式为:
rnn = RNN() ff = FeedForwardNN() hidden_state = [0,0,0] for word in input: output,hidden_state = rnn(word,hidden_state) prediction = ff(output)
tensorflow中RNN的相关函数
tf.nn.rnn_cell.BasicLSTMCell
tf.nn.rnn_cell.BasicRNNCell( num_units, activation=None, reuse=None, name=None, dtype=None, **kwargs)
- num_units:RNN单元中的神经元数量,即输出神经元数量。
- activation:激活函数。
- reuse:描述是否在现有范围中重用变量。如果不为True,并且现有范围已经具有给定变量,则会引发错误。
- name:层的名称。
- dtype:该层的数据类型。
- kwargs:常见层属性的关键字命名属性,如trainable,当从get_config()创建cell 。
在使用时,可以定义为:
RNN_cell = tf.nn.rnn_cell.BasicRNNCell(n_hidden_units,activation=tf.nn.tanh)
在定义完成后,可以进行状态初始化:
_init_state = RNN_cell.zero_state(batch_size,tf.float32)
tf.nn.dynamic_rnn
tf.nn.dynamic_rnn(
cell,
inputs,
sequence_length=None,
initial_state=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
)
- cell:上文所定义的lstm_cell。
- inputs:RNN输入。如果time_major==false(默认),则必须是如下shape的tensor:[batch_size,max_time,…]或此类元素的嵌套元组。如果time_major==true,则必须是如下形状的tensor:[max_time,batch_size,…]或此类元素的嵌套元组。
- sequence_length:Int32/Int64矢量大小。用于在超过批处理元素的序列长度时复制通过状态和零输出。因此,它更多的是为了性能而不是正确性。
- initial_state:上文所定义的_init_state。
- dtype:数据类型。
- parallel_iterations:并行运行的迭代次数。那些不具有任何时间依赖性并且可以并行运行的操作将是。这个参数用时间来交换空间。值>>1使用更多的内存,但花费的时间更少,而较小的值使用更少的内存,但计算需要更长的时间。
- time_major:输入和输出tensor的形状格式。如果为真,这些张量的形状必须是[max_time,batch_size,depth]。如果为假,这些张量的形状必须是[batch_size,max_time,depth]。使用time_major=true会更有效率,因为它可以避免在RNN计算的开始和结束时进行换位。但是,大多数TensorFlow数据都是批处理主数据,因此默认情况下,此函数为False。
- scope:创建的子图的可变作用域;默认为“RNN”。
在RNN的最后,需要用该函数得出结果。
outputs,states = tf.nn.dynamic_rnn(RNN_cell,X_in,initial_state = _init_state,time_major = False)
返回的是一个元组 (outputs, state):
outputs:RNN的最后一层的输出,是一个tensor。如果为time_major== False,则它的shape为[batch_size,max_time,cell.output_size]。如果为time_major== True,则它的shape为[max_time,batch_size,cell.output_size]。
states:states是一个tensor。state是最终的状态,也就是序列中最后一个cell输出的状态。一般情况下states的形状为 [batch_size, cell.output_size],但当输入的cell为BasicLSTMCell时,states的形状为[2,batch_size, cell.output_size ],其中2也对应着LSTM中的cell state和hidden state。
整个RNN的定义过程为:
def RNN(X,weights,biases):
#X最开始的形状为(128 batch,28 steps,28 inputs)
#转化为(128 batch*28 steps,128 hidden)
X = tf.reshape(X,[-1,n_inputs])
#经过乘法后结果为(128 batch*28 steps,256 hidden)
X_in = tf.matmul(X,weights['in'])+biases['in']
#再次转化为(128 batch,28 steps,256 hidden)
X_in = tf.reshape(X_in,[-1,n_steps,n_hidden_units])
RNN_cell = tf.nn.rnn_cell.BasicRNNCell(n_hidden_units,activation=tf.nn.tanh)
_init_state = RNN_cell.zero_state(batch_size,tf.float32)
outputs,states = tf.nn.dynamic_rnn(RNN_cell,X_in,initial_state = _init_state,time_major = False)
results = tf.matmul(states,weights['out'])+biases['out']
return results
全部代码
该例子为手写体识别例子,将手写体的28行分别作为每一个step的输入,输入维度均为28列。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data",one_hot = "true")
lr = 0.001 #学习率
training_iters = 1000000 #学习世代数
batch_size = 128 #每一轮进入训练的训练量
n_inputs = 28 #输入每一个隐含层的inputs维度
n_steps = 28 #一共分为28次输入
n_hidden_units = 128 #每一个隐含层的神经元个数
n_classes = 10 #输出共有10个
x = tf.placeholder(tf.float32,[None,n_steps,n_inputs])
y = tf.placeholder(tf.float32,[None,n_classes])
weights = {
'in':tf.Variable(tf.random_normal([n_inputs,n_hidden_units])),
'out':tf.Variable(tf.random_normal([n_hidden_units,n_classes]))
}
biases = {
'in':tf.Variable(tf.constant(0.1,shape=[n_hidden_units])),
'out':tf.Variable(tf.constant(0.1,shape=[n_classes]))
}
def RNN(X,weights,biases):
#X最开始的形状为(128 batch,28 steps,28 inputs)
#转化为(128 batch*28 steps,128 hidden)
X = tf.reshape(X,[-1,n_inputs])
#经过乘法后结果为(128 batch*28 steps,256 hidden)
X_in = tf.matmul(X,weights['in'])+biases['in']
#再次转化为(128 batch,28 steps,256 hidden)
X_in = tf.reshape(X_in,[-1,n_steps,n_hidden_units])
RNN_cell = tf.nn.rnn_cell.BasicRNNCell(n_hidden_units,activation=tf.nn.tanh)
_init_state = RNN_cell.zero_state(batch_size,tf.float32)
outputs,states = tf.nn.dynamic_rnn(RNN_cell,X_in,initial_state = _init_state,time_major = False)
results = tf.matmul(states,weights['out'])+biases['out']
return results
pre = RNN(x,weights,biases)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = pre,labels = y))
train_op = tf.train.AdamOptimizer(lr).minimize(cost)
correct_pre = tf.equal(tf.argmax(y,1),tf.argmax(pre,1))
accuracy = tf.reduce_mean(tf.cast(correct_pre,tf.float32))
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
step = 0
while step*batch_size <training_iters:
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape([batch_size,n_steps,n_inputs])
sess.run(train_op,feed_dict = {
x:batch_xs,
y:batch_ys
})
if step%20 == 0:
print(sess.run(accuracy,feed_dict = {
x:batch_xs,
y:batch_ys
}))
step += 1
以上就是python人工智能tensorflow构建循环神经网络RNN的详细内容,更多关于tensorflow构建循环神经网络RNN的资料请关注我们其它相关文章!
相关推荐
-

Python通过TensorFLow进行线性模型训练原理与实现方法详解
本文实例讲述了Python通过TensorFLow进行线性模型训练原理与实现方法.分享给大家供大家参考,具体如下: 1.相关概念 例如要从一个线性分布的途中抽象出其y=kx+b的分布规律 特征是输入变量,即简单线性回归中的 x 变量.简单的机器学习项目可能会使用单个特征,而比较复杂的机器学习项目可能会使用数百万个特征. 标签是我们要预测的事物,即简单线性回归中的 y 变量. 样本是指具体的数据实例.有标签样本是指具有{特征,标签}的数据,用于训练模型,总结规律.无标签样本只具有特征的数据x,通过
-
Python神经网络TensorFlow基于CNN卷积识别手写数字
目录 基础理论 一.训练CNN卷积神经网络 1.载入数据 2.改变数据维度 3.归一化 4.独热编码 5.搭建CNN卷积神经网络 5-1.第一层:第一个卷积层 5-2.第二层:第二个卷积层 5-3.扁平化 5-4.第三层:第一个全连接层 5-5.第四层:第二个全连接层(输出层) 6.编译 7.训练 8.保存模型 代码 二.识别自己的手写数字(图像) 1.载入数据 2.载入训练好的模型 3.载入自己写的数字图片并设置大小 4.转灰度图 5.转黑底白字.数据归一化 6.转四维数据 7.预测 8.显示
-
Python通过TensorFlow卷积神经网络实现猫狗识别
这份数据集来源于Kaggle,数据集有12500只猫和12500只狗.在这里简单介绍下整体思路 处理数据 设计神经网络 进行训练测试 1. 数据处理 将图片数据处理为 tf 能够识别的数据格式,并将数据设计批次. 第一步get_files() 方法读取图片,然后根据图片名,添加猫狗 label,然后再将 image和label 放到 数组中,打乱顺序返回 将第一步处理好的图片 和label 数组 转化为 tensorflow 能够识别的格式,然后将图片裁剪和补充进行标准化处理,分批次返回. 新建
-
python进阶TensorFlow神经网络拟合线性及非线性函数
目录 一.拟合线性函数 生成随机坐标 神经网络拟合 代码 二.拟合非线性函数 生成二次随机点 神经网络拟合 代码 一.拟合线性函数 学习率0.03,训练1000次: 学习率0.05,训练1000次: 学习率0.1,训练1000次: 可以发现,学习率为0.05时的训练效果是最好的. 生成随机坐标 1.生成x坐标 2.生成随机干扰 3.计算得到y坐标 4.画点 # 生成随机点 def Produce_Random_Data(): global x_data, y_data # 生成x坐标 x_dat
-
python深度学习TensorFlow神经网络模型的保存和读取
目录 之前的笔记里实现了softmax回归分类.简单的含有一个隐层的神经网络.卷积神经网络等等,但是这些代码在训练完成之后就直接退出了,并没有将训练得到的模型保存下来方便下次直接使用.为了让训练结果可以复用,需要将训练好的神经网络模型持久化,这就是这篇笔记里要写的东西. TensorFlow提供了一个非常简单的API,即tf.train.Saver类来保存和还原一个神经网络模型. 下面代码给出了保存TensorFlow模型的方法: import tensorflow as tf # 声明两个变量
-
python人工智能tensorflow构建循环神经网络RNN
目录 学习前言 RNN简介 tensorflow中RNN的相关函数 tf.nn.rnn_cell.BasicLSTMCell tf.nn.dynamic_rnn 全部代码 学习前言 在前一段时间已经完成了卷积神经网络的复习,现在要对循环神经网络的结构进行更深层次的明确. RNN简介 RNN 是当前发展非常火热的神经网络中的一种,它擅长对序列数据进行处理. 什么是序列数据呢?举个例子. 现在假设有四个字,“我” “去” “吃” “饭”.我们可以对它们进行任意的排列组合. “我去吃饭”,表示的就是我
-
python人工智能tensorflow构建卷积神经网络CNN
目录 简介 隐含层介绍 1.卷积层 2.池化层 3.全连接层 具体实现代码 卷积层.池化层与全连接层实现代码 全部代码 学习神经网络已经有一段时间,从普通的BP神经网络到LSTM长短期记忆网络都有一定的了解,但是从未系统的把整个神经网络的结构记录下来,我相信这些小记录可以帮助我更加深刻的理解神经网络. 简介 卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),
-
python循环神经网络RNN函数tf.nn.dynamic_rnn使用
目录 学习前言 tf.nn.dynamic_rnn的定义 tf.nn.dynamic_rnn的使用举例 单层实验 多层实验 学习前言 已经完成了RNN网络的构建,但是我们对于RNN网络还有许多疑问,特别是tf.nn.dynamic_rnn函数,其具体的应用方式我们并不熟悉,查询了一下资料,我心里的想法是这样的. tf.nn.dynamic_rnn的定义 tf.nn.dynamic_rnn( cell, inputs, sequence_length=None, initial_state=Non
-
基于循环神经网络(RNN)的古诗生成器
基于循环神经网络(RNN)的古诗生成器,具体内容如下 之前在手机百度上看到有个"为你写诗"功能,能够随机生成古诗,当时感觉很酷炫= = 在学习了深度学习后,了解了一下原理,打算自己做个实现练练手,于是,就有了这个项目.文中如有瑕疵纰漏之处,还请路过的诸位大佬不吝赐教,万分感谢! 使用循环神经网络实现的古诗生成器,能够完成古体诗的自动生成.我简单地训练了一下,格式是对上了,至于意境么...emmm,呵呵 举一下模型测试结果例子: 1.生成古体诗 示例1: 树阴飞尽水三依,谩自为能厚景奇.
-
基于循环神经网络(RNN)实现影评情感分类
使用循环神经网络(RNN)实现影评情感分类 作为对循环神经网络的实践,我用循环神经网络做了个影评情感的分类,即判断影评的感情色彩是正面的,还是负面的. 选择使用RNN来做情感分类,主要是因为影评是一段文字,是序列的,而RNN对序列的支持比较好,能够"记忆"前文.虽然可以提取特征词向量,然后交给传统机器学习模型或全连接神经网络去做,也能取得很好的效果,但只从端对端的角度来看的话,RNN无疑是最合适的. 以下介绍实现过程. 一.数据预处理 本文中使用的训练数据集为https://www.c
-
python人工智能tensorflow函数tensorboard使用方法
目录 tensorboard相关函数及其常用参数设置 1 with tf.name_scope(layer_name): 2 tf.summary.histogram(layer_name+"/biases",biases) 3 tf.summary.scalar(“loss”,loss) 4 tf.summary.merge_all() 5 tf.summary.FileWriter(“logs/”,sess.graph) 6 write.add_summary(result,i)
-
python 使用Tensorflow训练BP神经网络实现鸢尾花分类
Hello,兄弟们,开始搞深度学习了,今天出第一篇博客,小白一枚,如果发现错误请及时指正,万分感谢. 使用软件 Python 3.8,Tensorflow2.0 问题描述 鸢尾花主要分为狗尾草鸢尾(0).杂色鸢尾(1).弗吉尼亚鸢尾(2). 人们发现通过计算鸢尾花的花萼长.花萼宽.花瓣长.花瓣宽可以将鸢尾花分类. 所以只要给出足够多的鸢尾花花萼.花瓣数据,以及对应种类,使用合适的神经网络训练,就可以实现鸢尾花分类. 搭建神经网络 输入数据是花萼长.花萼宽.花瓣长.花瓣宽,是n行四列的矩阵. 而输
-
python人工智能tensorflow常用激活函数Activation Functions
目录 常见的激活函数种类及其图像 1 sigmoid(logsig)函数 2 tanh函数 3 relu函数 4 softplus函数 tensorflow中损失函数的表达 1 sigmoid(logsig)函数 2 tanh函数 3 relu函数 4 softplus函数 激活函数在机器学习中常常用在神经网络隐含层节点与神经网络的输出层节点上,激活函数的作用是赋予神经网络更多的非线性因素,如果不用激励函数,输出都是输入的线性组合,这种情况与最原始的感知机相当,网络的逼近能力相当有限.如果能够引
-
python人工智能tensorflow函数tf.nn.dropout使用方法
目录 前言 tf.nn.dropout函数介绍 例子 代码 keep_prob = 0.5 keep_prob = 1 前言 神经网络在设置的神经网络足够复杂的情况下,可以无限逼近一段非线性连续函数,但是如果神经网络设置的足够复杂,将会导致过拟合(overfitting)的出现,就好像下图这样. 看到这个蓝色曲线,我就知道: 很明显蓝色曲线是overfitting的结果,尽管它很好的拟合了每一个点的位置,但是曲线是歪歪曲曲扭扭捏捏的,这个的曲线不具有良好的鲁棒性,在实际工程实验中,我们更希望得到
-
python人工智能TensorFlow自定义层及模型保存
目录 一.自定义层和网络 1.自定义层 2.自定义网络 二.模型的保存和加载 1.保存参数 2.保存整个模型 一.自定义层和网络 1.自定义层 ①必须继承自layers.layer ②必须实现两个方法,__init__和call 这个层,实现的就是创建参数,以及一层的前向传播. 添加参数使用self.add_weight,直接调用即可,因为已经在母类中实现. 在call方法中,实现前向传播并返回结果即可. 2.自定义网络 ①必须继承自keras.Model ②必须实现两个方法,__init__和