C语言深入探究冒泡排序与堆排序使用案例讲解
目录
- 一.冒泡排序
- 1.1冒泡排序引入
- 1.2冒泡排序的核心思想与算法分析
- 1.3实例说明
- 1.4优化
- 1.5代码实现
- 1.6性能分析
- 二.堆排序
- 2.1堆的基础知识
- 2.1.1堆是什么
- 2.1.2堆的性质
- 2.2堆排序的核心思想与基本步骤
- 2.3实例说明与分析
- 2.4代码实现
- 2.5性能分析
一.冒泡排序
1.1冒泡排序引入
对于任何编程语言,当我们学到循环和数组的时候,都会介绍一种排序算法:冒泡排序;深入学习更多排序算法后和在实际使用情况中,冒泡排序的使用还是极少的。它适合数据规模很小的时候,而且它的效率也比较低,但是作为入门的排序算法,还是值得学习的。
1.2冒泡排序的核心思想与算法分析
核心思想:相邻的元素两两比较,较大的数下沉,较小的数冒起来,这样一趟比较下来,最大(小)值就会排列在一端。
因为较大的数会下沉,所以我们也可以将冒泡排序称作沉石排序。
算法分析:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个;
- 每趟从第一对相邻元素开始,对每一对相邻元素作同样的工作,直到最后一对;
- 针对所有的元素重复以上的步骤,除了已排序过的元素(每趟排序后的最后一个元素),直到没有任何一对数字需要比较。
1.3实例说明
以3,2,5,6,1,11为例子,排序过程:
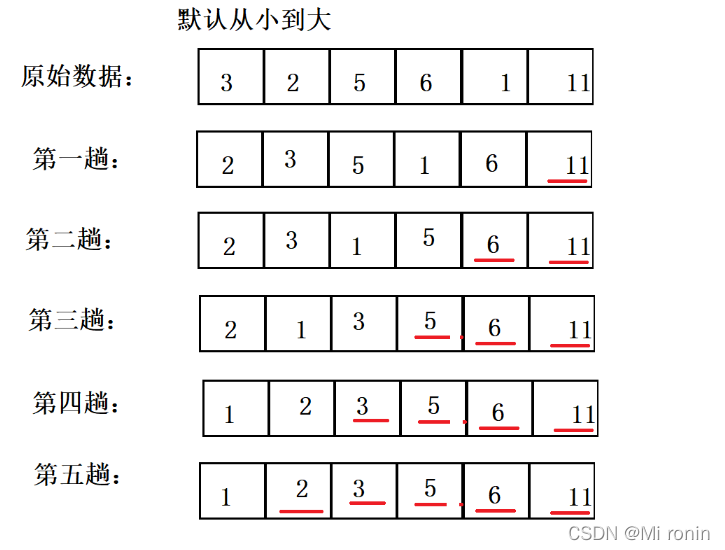
- 底部画线的为已确定的数据
- 有n个数据,需要跑n-1趟即可
1.4优化
上面的排序过程在第四趟处理完时,就已经完全有序了(肉眼观察的),理应直接退出循环即可,第五趟顺序完全可以省略,那么我们就会有一个问题:
怎样判断数据完全有序?
从先到后遍历一遍,发现数据两两比较都是前面小于后面(没有交换操作),这个时候,就可以判定数据已经完全有序。
1.5代码实现
void BubbleSort(int* arr, int len)
{
int count = 0;
bool tag = true;//标记 首先赋初值为真
//从头到尾遍历一般,没有交换操作,则可以认定完全有序
//反过来说:只要有一次交换操作,则不能认定完全有序
for (int i = 0; i < len - 1; i++)//需要多少趟
{
tag = true;//注意:不要忘,每一趟开始的时候,记得将tag重新置为true
for (int j = 0; j + 1 < len - i; j++)//控制两两比较 j指向两两比较的开始位置
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
tag = false;
}
}
count++;
if (tag)//如果一趟跑完之后,发现tag没有变,还是真,则代表没有前面大于后面的情况发生,则已经完全有序
{
break;
}
}
printf("%d\n", count);
}
1.6性能分析
- 时间复杂度:o(n^2);
- 空间复杂度:o(1);
- 稳定性:稳定
二.堆排序
2.1堆的基础知识
2.1.1堆是什么
堆是一种数据结构,一种叫做完全二叉树的数据结构。
2.1.2堆的性质
这里我们用到两种堆,其实也算是一种。
大顶堆:每个节点的值都大于或者等于它的左右子节点的值。
小顶堆:每个节点的值都小于或者等于它的左右子节点的值。
查找数组中某个数的父结点和左右孩子结点,比如已知索引为i的数,那么
1.父结点索引:(i-1)/2(这里计算机中的除以2,省略掉小数)
2.左孩子索引:2*i+1
3.右孩子索引:2*i+2
如下图所示:
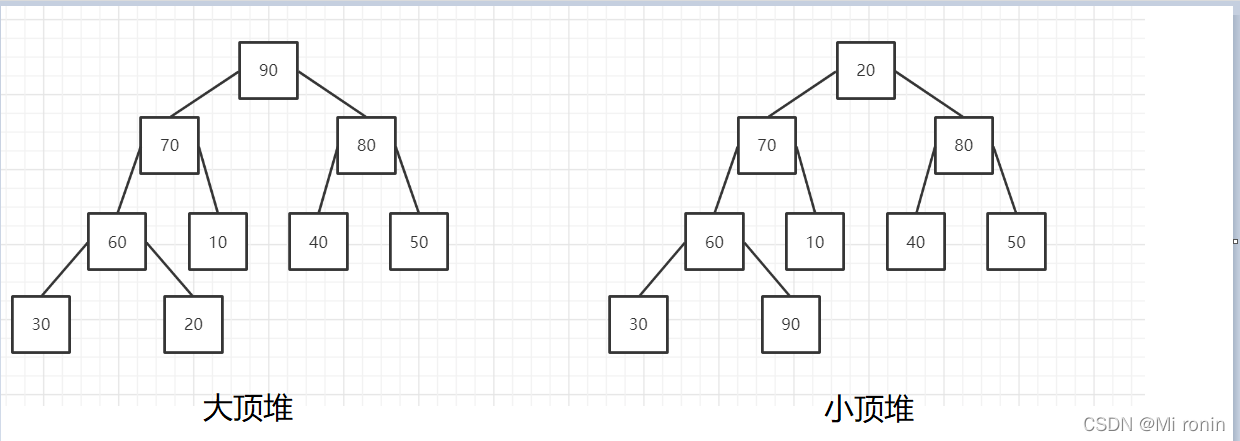
两种堆就是如上图所示。
如果我们把这种逻辑结构映射到数组中,如下所示:
大顶堆:

小顶堆:

从这里我们可以得出以下性质:
对于大顶堆:arr[i] >= arr[2i + 1] && arr[i] >= arr[2i + 2]
对于小顶堆:arr[i] <= arr[2i + 1] && arr[i] <= arr[2i + 2]
2.2堆排序的核心思想与基本步骤
核心思想:将无序数组构造成一个大顶堆,固定一个最大值,将剩余的数重新构造成一个大顶堆,重复这样的过程构造堆。
基本步骤:
- 将带排序的序列构造成一个大顶堆,根据大顶堆的性质,当前堆的根节点(堆顶)就是序列中最大的元素;
- 将堆顶元素和最后一个元素交换,然后将剩下的节点重新构造成一个大顶堆;
- 重复步骤2,如此反复,从第一次构建大顶堆开始,每一次构建,我们都能获得一个序列的最大值,然后把它放到大顶堆的尾部;
- 最后,就得到一个有序的序列了。
2.3实例说明与分析
以4,5,8,2,3,9,7,1为例,按照上面的基本步骤进行排序,过程如下:
1.将无序序列构造为一个大顶堆

2.现在我们需要找到最后一个非叶子节点的位置,也就是索引值。
对于一个完全二叉树,在填满的情况下,每一层的元素个数是上一层的二倍,根节点数量是1,所以最后一层的节点数量,一定是之前所有层节点总数+1,所以,我们能找到最后一层的第一个节点的索引,即节点总数/2(根节点索引为0),这也就是第一个叶子节点,所以第一个非叶子节点的索引就是第一个叶子结点的索引-1。
那么对于填不满的二叉树呢?这个计算方式仍然适用,当我们从上往下,从左往右填充二叉树的过程中,第一个叶子节点,一定是序列长度/2,所以第一个非叶子节点的索引就是(数组长度/ 2 -1)。
现在找到了最后一个非叶子节点,即元素值为2的节点,比较它的左右节点的值,是否比他大,如果大就换位置。这里因为1<2,所以,不需要任何操作,继续比较下一个,即元素值为8的节点,它的左节点值为9比它本身大,所以交换。

3.因为元素8没有子节点,所以继续比较下一个非叶子节点,元素值为5的节点,它的两个子节点值都比本身小,不需要调整;然后是元素值为4的节点,也就是根节点,因为9>4,所以需要调整位置
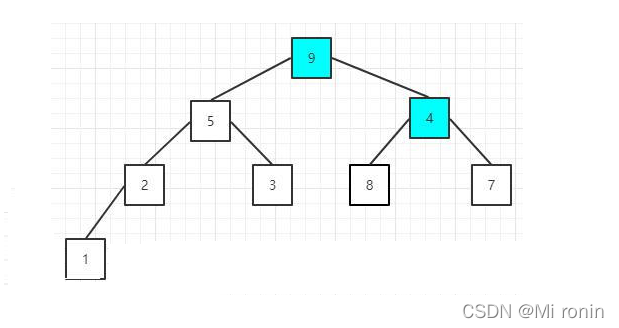
4.原来元素值为9的节点值变成4了,而且它本身有两个子节点,所以,这时需要再次调整该节点
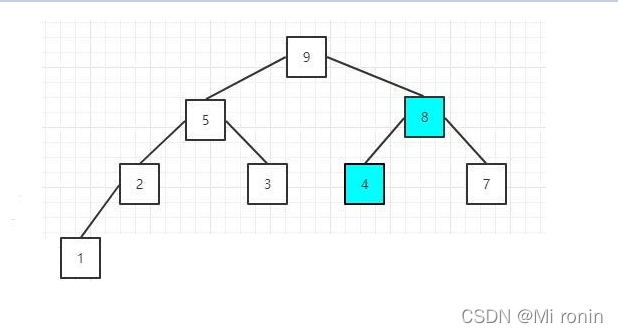
5.排序序列,将堆顶的元素值和尾部的元素交换

6.将剩余的元素重新构建大顶堆,其实就是调整根节点以及其调整后影响的子节点,因为其他节点之前已经满足大顶堆性质
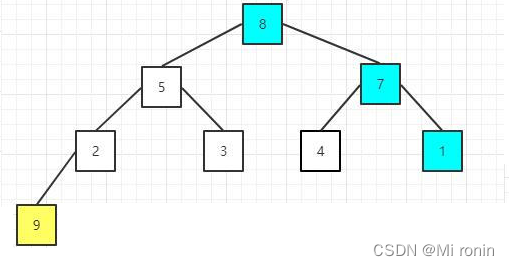
7.继续交换,堆顶节点元素值为8与当前尾部节点元素值为1的进行交换

8.重新构建大顶堆

9.重复交换

10.重新构建大顶堆
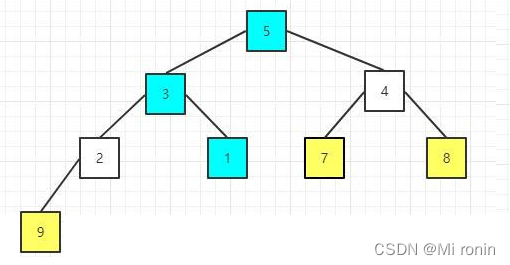
11.重复交换

12.重新构建大顶堆
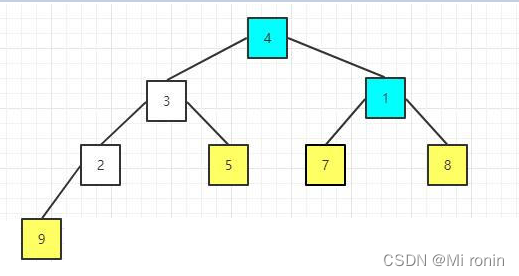
13.重复交换
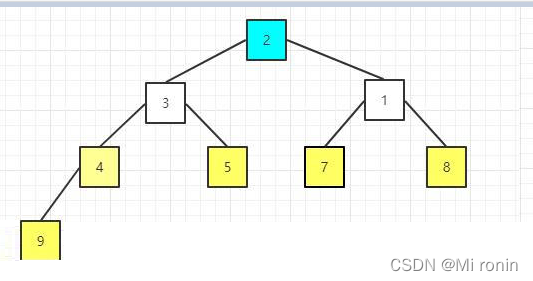
14.重新构建大顶堆

15.重复交换
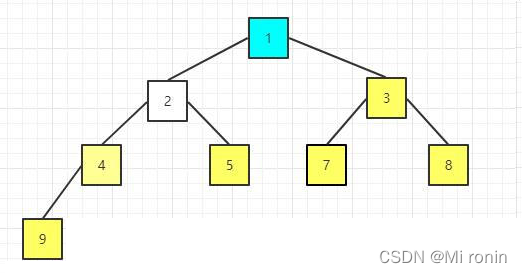
16.重新构建大顶堆

17.重复交换

18.重新构建大顶堆

19.继续交换
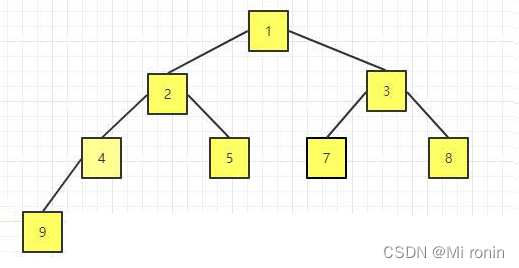
这里我么就交换结束了 得到了最后的结果。
2.4代码实现
void HeapAdjust(int arr[], int start, int end)
{
//assert
int tmp = arr[start];
for (int i = start * 2 + 1; i <= end; i = start * 2 + 1)//start*2+1 相当于是start这个节点的左孩子
{ //i<end 退出for循环 触发的是情况1
if (i<end && arr[i + 1] > arr[i])//i<end 代表存在右孩子,且右孩子的值还大于左孩子
{
i++;//则此时,让i指向右孩子
}
//此时i肯定已经指向较大的那个孩子
if (arr[i] > tmp)//子大于父
{
arr[start] = arr[i];
start = i;
}
else
{
break;//退出for循环,触发情况2
}
}
arr[start] = tmp;
}
void HeapSort(int* arr, int len)
{
//1.整体从最后一个非叶子节点开始由内到外调整一次
//首先需要知道最后一个非叶子节点的下标
for (int i = (len - 1 - 1) / 2; i >= 0; i--)//因为最后一个非叶子节点肯定是 最后一个叶子节点的父节点
{
HeapAdjust(arr, i, len - 1);//调用我们一次调整函数 //这里第三个值比较特殊,没有规律可言,则直接给最大值len-1
}
//此时,已经调整为大顶堆了
//接下来,根节点的值和当前最后一个节点的值进行交换,然后将尾结点剔除掉
for (int i = 0; i < len - 1; i++)
{
int tmp = arr[0];
arr[0] = arr[len - 1 - i];//len-1-i 是我们当前的尾结点下标
arr[len - 1 - i] = tmp;
HeapAdjust(arr, 0, (len - 1 - i) - 1);//len-1-i 是我们当前的尾结点下标,然后再给其-1则相当于将其剔除出我们的循环
}
}
2.5性能分析
- 时间复杂度:最好和最坏的情况时间复杂度都是(n*logn) 。
- 空间复杂度:O(1)。
- 稳定性:不稳定。
到此这篇关于C语言深入探究冒泡排序与堆排序使用案例讲解的文章就介绍到这了,更多相关C语言排序内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C语言对冒泡排序进行升级介绍
目录 一.补充一下关于void*指针的知识,易于我们对下列函数实现的理解 二.实现排序函数中的核心,比较函数 三.实现排序函数 四.转换函数的实现 总结 简单的冒牌排序只能对一中数组的类型进行排序,现在我们用冒泡排序为基础来改造出一个可以对任意数组排序的排序函数! 后面附有实现的源码! 首先我们以qsort函数为例慢慢分析,然后确定我们的排序函数如何增强,第一步我们从它的参数下手,它一共4个参数. 1.第一个参数类型是void*,qsort函数可以用来对任意类型的数组排序,用void *型指针可
-
C语言冒泡排序算法代码详解
今天我们来用C语言实现一下冒泡排序 首先我们来了解一下什么叫做冒泡排序,冒泡顾名思义把质量轻的气体(如二氧化碳一样)浮到水面上(如可乐中的二氧化碳),因此冒泡排序的原理就是N个元素在一个周期中,微观上依次进行两两元素的比较,小的元素就被放在前面,大的元素放在后面,以此来进行N-1个周期,来完成冒泡排序. 上文中的一个周期,即外循环,依次进行比较,即内循环. 文字看着很迷糊?没事儿,上图 如图所示,两两元素依次进行比较,小的元素往前移动,大的元素往后移动,直至元素顺序是升序的形式,即移动了 元素-
-
C语言数据结构之堆排序详解
目录 1.堆的概念及结构 2.堆的实现 2.1堆的向下调整算法 2.2堆的向上调整算法 2.3建堆(数组) 2.4堆排序 2.5堆排序的时间复杂度 1.堆的概念及结构 如果有一个关键码的集合K = {k0,k1, k2,…,kn-1},把它的所有元素按完全二叉树(二叉树具体概念参见——二叉树详解)的顺序存储方式存储在一个一维数组中,并满足:Ki <= K2i+1 且 Ki<= K2i+2 (Ki >= K2i+1 且 Ki >= K2i+2) i = 0,1,2…,则称为小堆(或大
-
C语言数据结构中堆排序的分析总结
目录 一.本章重点 二.堆 2.1堆的介绍(三点) 2.2向上调整 2.3向下调整 2.4建堆(两种方式) 三.堆排序 一.本章重点 堆 向上调整 向下调整 堆排序 二.堆 2.1堆的介绍(三点) 1.物理结构是数组 2.逻辑结构是完全二叉树 3.大堆:所有的父亲节点都大于等于孩子节点,小堆:所有的父亲节点都小于等于孩子节点. 2.2向上调整 概念:有一个小/大堆,在数组最后插入一个元素,通过向上调整,使得该堆还是小/大堆. 使用条件:数组前n-1个元素构成一个堆. 以大堆为例: 逻辑实现: 将
-
C语言排序之 堆排序
目录 前言: 完全二叉树在数组中下标换算公式 代码工作流程 整体流程 重建堆函数流程 大小顶堆使用场景 时间复杂度 代码 前言: 堆是具有以下性质的完全二叉树 每个节点大于或等于其左右子节点,此时称为大顶(根)堆 每个节点小于或等于其左右子节点,此时称为小顶(根)堆 完全二叉树在数组中下标换算公式 假设堆根节点从1开始编号(从1开始方便计算,0下标空着)下面以编号为i的非根节点为例,计算其关联节点的下标公式为:其父节点:i/2其左孩子:2i其右孩子:2i+1 注:把这个完全二叉树按层序遍历放入
-
c语言冒泡排序和选择排序的使用代码
目录 1.冒泡排序 2.选择排序 区别 总结 1.冒泡排序 冒泡排序将一个列表中的两个元素进行比较,并将最小的元素交换到顶部.两个元素中较小的会冒到顶部,而较大的会沉到底部,该过程将被重复执行,直到所有元素都被排序. 冒泡排序示意图 以如图所示的冒泡排序为例,每次比较相邻的两个值,值小的交换到前面,每轮结束后值最大的数交换到了最后.第一轮需要比较4次:第二轮需要比较3次:第三轮需要比较2次:第四轮需要比较1次. 那么如何用二重循环将5个数排序呢?5个数存放在一维数组中,外层循环控制比较多少轮,循
-
C语言详解冒泡排序实现
目录 前言 一.冒泡排序是什么 二.具体步骤 1.代码解释 2.读入数据 总结 前言 在排序中,有各种各样的排序方式,今天我们将要来介绍<冒泡排序>.今天会从冒泡排序的具体意义和他的操作来展开. 一.冒泡排序是什么 从左到右,相邻元素进行比较.每次比较一轮,就会找到序列中最大的一个或最小的一个.这个数就会从序列的最右边冒出来. 以从小到大排序为例,第一轮比较后,所有数中最大的那个数就会浮到最右边:第二轮比较后,所有数中第二大的那个数就会浮到倒数第二个位置……就这样一轮一轮地比较,最后实现从小到
-
C语言深入探究选择排序与基数排序使用案例讲解
目录 一.选择排序 1.1 选择排序引入 1.2 选择排序的基本思想与算法分析 1.3 实例说明 1.4 代码实现 1.5 性能分析 二.基数排序 2.1 基数排序基本思想与算法步骤 2.2 实例说明 2.3 代码实现 2.4 性能分析 一.选择排序 1.1 选择排序引入 就像炒股一样,有的人爱炒短线,不断的买进卖出通过差价来盈利,但是频繁的买进卖出,也会因为频繁的手续费和一系列费用获益较少:有的人,不断的进行观察和判断,等到时机一到,果断买进或卖出,这种人交易次数少,而最终收获颇丰:正如我们所
-
C语言八大排序之堆排序
目录 前言 一.堆排序的概念 二.堆排序的实现 第一步:构建堆 第二步:排序 三.完整代码 四.证明建堆的时间复杂度 前言 本章我们来讲解八大排序之堆排序.2022,地球Online新赛季开始了!让我们一起努力内卷吧! 一.堆排序的概念 堆排序(Heapsort):利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种.通过堆来进行选择数据,需要注意的是 排升序要建大堆,排降序建小堆. 堆排序使用堆来选数,效率就高了很多. 时间复杂度: 空间复杂度: 稳定性:不稳定 二.堆排序的实
-
C语言实现冒泡排序算法的示例详解
目录 1. 问题描述 2. 问题分析 3. 算法设计 动图演示 4. 程序设计 设计一 设计二 结论 5. 流程框架 6. 代码实现 7. 问题拓展 1. 问题描述 对N个整数(数据由键盘输入)进行升序排列. 2. 问题分析 对于N个数因其类型相同,我们可利用 数组 进行存储. 冒泡排序是在 两个相邻元素之间进行比较交换的过程将一个无序表变成有序表. 冒泡排序的思想:首先,从表头开始往后扫描数组,在扫描过程中逐对比较相邻两个元素的大小. 若相邻两个元素中,前面的元素大于后面的元素,则将它们互换,