Java面试题冲刺第四天--数据库
目录
- 面试题1:你对数据库优化有哪些了解呀?
- 正经回答:
- 深入追问:
- 追问1:那你对SQL优化方面有哪些技巧呢?
- 追问2:嗯,那你说一下为什么不建议用SELECT * 呢?
- 二、SELECT语句的一些其他优化
- 面试题2:你对分库分表是怎么看的呀?
- 正经回答:
- 1、垂直分表
- 2、水平分表
- 3、垂直分库
- 4、水平分库
- 深入追问:
- 追问1:毫无意义,我真的不想问他MySQL问题了
- 面试题3:MySQL删除数据的方式都有哪些?
- 正经回答:
- 深入追问:
- 追问1:说一下 delete、truncate、drop的区别吧
- 总结
面试题1:你对数据库优化有哪些了解呀?
正经回答:
在高并发环境下,数据库是最敏感的地方,nginx负载均衡、Server集群、MQ消息队列、Redis缓存集群、数据库主从集群所作的一切都是为了减轻数据库访问压力。但是!前提是要有健壮的数据库和底层代码,这样才能使前期准备不再是花架子。
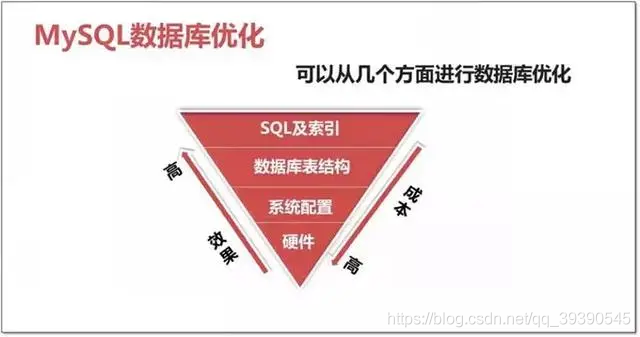
性价比如上图,我们针对数据库的优化优先级大致如下:
- 高:从SQL优化、索引优化入手,优化慢SQL、利用好索引,是重中之重;
- 中:SQL优化之后,是对数据表结构设计、横纵分表分库,对数据量级的处理;
- 低:通过修改数据库系统配置,最大化里用服务器内存等资源;
- 低:通过以上方式还不行,那就是服务器资源瓶颈了,加机器。
优化成本:硬件 > 系统配置 > 数据库表结构 > SQL及索引。优化效果:硬件 < 系统配置 < 数据库表结构 < SQL及索引。
深入追问:
追问1:那你对SQL优化方面有哪些技巧呢?
简单说对于SQL优化,就三点:
- 最大化利用索引;
- 尽可能避免全表扫描;
- 减少无效数据的查询;
首先要清楚SELECT语句 - 执行顺序:
FROM<表名> # 选取表,将多个表数据通过笛卡尔积变成一个表。ON<筛选条件> # 对笛卡尔积的虚表进行筛选JOIN<join, left join, right join…> <join表> # 指定join,用于添加数据到on之后的虚表中,例如left join会将左表的剩余数据添加到虚表中WHERE<where条件> # 对上述虚表进行筛选GROUP BY<分组条件> # 分组 <SUM()等聚合函数> # 用于having子句进行判断,在书写上这类聚合函数是写在having判断里面的HAVING<分组筛选> # 对分组后的结果进行聚合筛选SELECT<返回数据列表> # 返回的单列必须在group by子句中,聚合函数除外DISTINCT#数据除重ORDER BY<排序条件> # 排序LIMIT<行数限制>
SQL优化策略:
声明:以下SQL优化策略适用于数据量较大的场景下,如果数据量较小,没必要以此为准,以免画蛇添足。
一、避免不走索引的场景
1.尽量避免在字段开头模糊查询,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE username LIKE '%陈%'
优化方式:尽量在字段后面使用模糊查询。如下:(原因涉及B+Tree索引最左前缀原则,可以参考《MySQL最左匹配原则,道儿上兄弟都得知道的原则》)
SELECT * FROM t WHERE username LIKE '陈%'
如果需求是要在前面使用模糊查询,
使用MySQL内置函数INSTR(str,substr) 来匹配,作用类似于java中的indexOf(),查询字符串出现的角标位.
使用FullText全文索引,用match against 检索
数据量较大的情况,建议引用ElasticSearch、solr,亿级数据量检索速度秒级
当表数据量较少(几千条儿那种),别整花里胡哨的,直接用like ‘%xx%'。
2.尽量避免使用 or,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE id = 1 OR id = 3
优化方式:可以用union代替or。如下:
SELECT * FROM t WHERE id = 1 UNION SELECT * FROM t WHERE id = 3
尽量避免进行null值的判断,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE score IS NULL
优化方式:可以给字段添加默认值0,对0值进行判断。如下:
SELECT * FROM t WHERE score = 0
4.尽量避免在where条件中等号的左侧进行表达式、函数操作,会导致数据库引擎放弃索引进行全表扫描。
可以将表达式、函数操作移动到等号右侧。如下:
-- 全表扫描 SELECT * FROM T WHERE score/10 = 9 -- 走索引 SELECT * FROM T WHERE score = 10*9
当数据量大时,避免使用where 1=1的条件。通常为了方便拼装查询条件,我们会默认使用该条件,数据库引擎会放弃索引进行全表扫描。如下:
SELECT username, age, sex FROM T WHERE 1=1
优化方式:用代码拼装sql时进行判断,没 where 条件就去掉 where,有where条件就加 and。
6.查询条件不要用 <> 或者 !=
使用索引列作为条件进行查询时,需要避免使用<>或者!=等判断条件。如确实业务需要,使用到不等于符号,需要在重新评估索引建立,避免在此字段上建立索引,改由查询条件中其他索引字段代替。
7.where条件仅包含复合索引非前置列
如下:复合(联合)索引包含key_part1,key_part2,key_part3三列,但SQL语句没有包含索引前置列"key_part1",按照MySQL联合索引的最左匹配原则,不会走联合索引。。
select col1 from table where key_part2=1 and key_part3=2
8.隐式类型转换造成不使用索引
如下SQL语句由于索引对列类型为varchar,但给定的值为数值,涉及隐式类型转换,造成不能正确走索引。
select col1 from table where col_varchar=123;
9.order by 条件要与where中条件一致,否则order by不会利用索引进行排序
-- 不走age索引 SELECT * FROM t order by age; -- 走age索引 SELECT * FROM t where age > 0 order by age; 对于上面的语句,数据库的处理顺序是:
- 第一步:根据where条件和统计信息生成执行计划,得到数据。
- 第二步:将得到的数据排序。当执行处理数据(order by)时,数据库会先查看第一步的执行计划,看order by 的字段是否在执行计划中利用了索引。如果是,则可以利用索引顺序而直接取得已经排好序的数据。如果不是,则重新进行排序操作。
- 第三步:返回排序后的数据。
当order by 中的字段出现在where条件中时,才会利用索引而不再二次排序,更准确的说,order by 中的字段在执行计划中利用了索引时,不用排序操作。
这个结论不仅对order by有效,对其他需要排序的操作也有效。比如group by 、union 、distinct等。

二、SELECT语句的一些其他优化
1.避免出现select *
首先,select * 操作在任何类型数据库中都不是一个好的SQL编写习惯。
使用select * 取出全部列,会让优化器无法完成索引覆盖扫描这类优化,会影响优化器对执行计划的选择,也会增加网络带宽消耗,更会带来额外的I/O,内存和CPU消耗。
建议提出业务实际需要的列数,将指定列名以取代select *。
2.避免出现不确定结果的函数
特定针对主从复制这类业务场景。由于原理上从库复制的是主库执行的语句,使用如now()、rand()、sysdate()、current_user()等不确定结果的函数很容易导致主库与从库相应的数据不一致。另外不确定值的函数,产生的SQL语句无法利用query cache。
3.多表关联查询时,小表在前,大表在后
在MySQL中,执行 from 后的表关联查询是从左往右执行的(Oracle相反),第一张表会涉及到全表扫描,所以将小表放在前面,先扫小表,扫描快效率较高,在扫描后面的大表,或许只扫描大表的前100行就符合返回条件并return了。
例如:表1有50条数据,表2有30亿条数据;如果全表扫描表2,你品,那就先去吃个饭再说吧是吧。
4.使用表的别名
当在SQL语句中连接多个表时,请使用表的别名并把别名前缀于每个列名上。这样就可以减少解析的时间并减少哪些友列名歧义引起的语法错误。
5.用where字句替换HAVING字句
避免使用HAVING字句,因为HAVING只会在检索出所有记录之后才对结果集进行过滤,而where则是在聚合前刷选记录,如果能通过where字句限制记录的数目,那就能减少这方面的开销。HAVING中的条件一般用于聚合函数的过滤,除此之外,应该将条件写在where字句中。
- where和having的区别:where后面不能使用组函数
6.调整Where字句中的连接顺序
MySQL采用从左往右,自上而下的顺序解析where子句。根据这个原理,应将过滤数据多的条件往前放,最快速度缩小结果集。对了,听说5.7版的语法解析器已经实现了where后条件的自动调节工作。查询条件很多的场景,建议不要做这种尝试。
追问2:嗯,那你说一下为什么不建议用SELECT * 呢?
在表查询中,一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写出。
增加查询分析器解析成本。
增减字段容易与 resultMap 配置不一致。
无用字段增加网络 消耗,尤其是 text 类型的字段。
1. 不需要的列会增加数据传输时间和网络开销
用“SELECT * ”数据库需要解析更多的对象、字段、权限、属性等相关内容,在 SQL 语句复杂,硬解析较多的情况下,会对数据库造成沉重的负担。
增大网络开销;* 有时会误带上如log、IconMD5之类的无用且大文本字段,数据传输size会几何增涨。如果DB和应用程序不在同一台机器,这种开销非常明显。
即使 mysql 服务器和客户端是在同一台机器上,使用的协议还是 tcp,通信也是需要额外的时间。
2. 对于无用的大字段,如 varchar、blob、text,会增加 io 操作
准确来说,长度超过 728 字节的时候,会先把超出的数据序列化到另外一个地方,因此读取这条记录会增加一次 io 操作。(MySQL InnoDB)
3. 失去MySQL优化器“覆盖索引”策略优化的可能性
SELECT * 杜绝了覆盖索引的可能性,而基于MySQL优化器的“覆盖索引”策略又是速度极快,效率极高,业界极为推荐的查询优化方式。
面试题2:你对分库分表是怎么看的呀?
正经回答:
- 分库:由单个数据库实例拆分成多个数据库实例,将数据分布到多个数据库实例中。
- 分表:由单张表拆分成多张表,将数据划分到多张表内。
要知道,对于大型互联网项目,数据量级可能不是我们能想到的,每日新增数据量过千万是常有的事儿,想靠单台MySQL服务器是不现实的。你项羽在牛B,也顶不住四个队友挂机啊!!项羽:???
随着业务数据量和网站QPS日益增高,对数据库压力也越来越大,单机版数据库很快会到达存储和并发瓶颈,就需要做数据库性能方面的优化,分库分表采取的是分而治之的策略,分库目的是减轻单台MySQL实例存储压力及可扩展性,而分表是解决单张表数据过大以后查询的瓶颈问题,坦白说,这些问题也是所有关系型数据库的“硬伤”。
常用策略包括:
垂直分表、水平分表、垂直分库、水平分库。
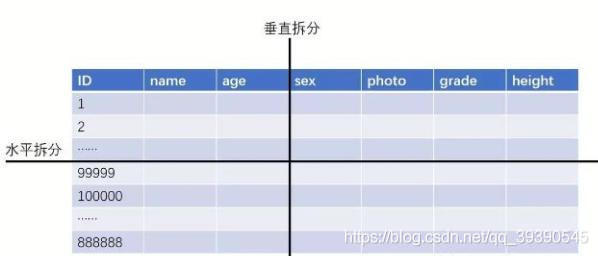
1、垂直分表
垂直分表,或者叫竖着切表,是不是感受到该策略是以字段为依据的!主要按照字段的活跃性、字段长度,将表中字段拆分到不同的表(主表和扩展表)中。
特点:
- 每个表的结构都不一样;
- 每个表的数据也不一样,
- 有一个关联字段,一般是主键或外键,用于关联兄弟表数据;
- 所有兄弟表的并集是该表的全量数据;
场景:
1.有几个字段属于热点字段,更新频率很高,要把这些字段单独切到一张表里,不然innodb行锁很恶心的,锁死你呀~~如用户表里的余额字段?不,我的余额就很稳定,一直是0。。
2.有大字段,如text,存储压力很大,毕竟innodb数据和索引是同一个文件;同时,我又喜欢用SELECT *,你懂得,这磁盘IO消耗的,跟玩儿似的,谁都扛不住的。
3.有明显的业务区分,或表结构设计时字段冗余;有些小伙伴看到第一点时,就发现陈哈哈是个菜鸡,用户表怎么会有余额字段?明显有问题啊!赶紧先到评论区喷陈哈哈一波~~然后笑嘻嘻的发现原来是个小尾巴,真不要脸是吧。。是的,因此不同业务我们要把具体字段拆开,这样才有利于业务后续扩展哦。
2、水平分表
水平分表,也叫“横着切”。。以行数据为依据进行切分,一般按照某列的自容进行切分。
如手机号表,我们可以通过前两位或前三位进行切分,如131、132、133 → phone_131、phone_132、phone_133,手机号有11位(100亿),量大是很正常的事儿,这年头谁家老头老太太每个手机呢是吧。这样切就把一张大表切成了好几十张小表,数据量不就下来了。有同学就问了那我怎么知道我这手机号查哪个表呢?一看你就没认真看前两行标红的点,为啥标红嘞?比如我查13100001111,那我截取前三位,动态拼接到查询的表名上,就行了。
特点:
- 每个表的结构都一样;
- 每个表的数据都不一样,没有交集;
- 所有表的并集是该表的全量数据;
场景:单表的数据量过大或增长速度很快,已经影响或即将会影响SQL查询效率,加重了CPU负担,提前到达瓶颈。记得水平分表越早越好,别问我为什么。。
分库
需要你注意的是,传统的分库和我们熟悉的集群、主从复制可不是一个事儿;多节点集群是将一个库复制成N个库,从而通过读写分离实现多个MySQL服务的负载均衡,实际是围绕一个库来搞的,这个库称为Master主库。而分库就不同了,分库是将这个主库一分为N,比如一分为二,然后针对这两个主库,再配置2N个从库节点。
3、垂直分库
纵向切库,太经典的切分方式,基于表进行切分,通常是把新的业务模块或集成公共模块拆分出去,比如我们最熟悉的单点登录、鉴权模块。熟悉的味道,记得有一次我把一些没用的表切到一个性能很好的服务器中,这服务器我专门用来学习,后来也不知被哪个狗腿子告密了~ 我**你个**,有种站出来,你个**东西
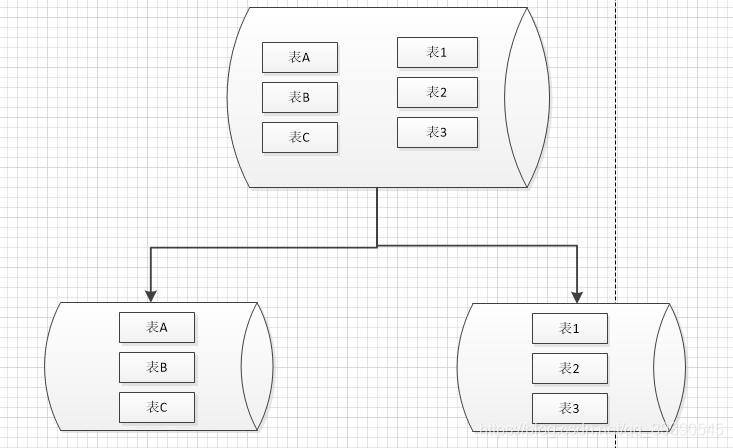
特点:
- 每个库的表都不一样;
- 表不一样,数据就更不一样了~ 没有任何交集;
- 每个库相对独立,模块化
场景:可以抽象出单独的业务模块时,可以抽象出公共区时(如字典、公共时间、公共配置等),或者想有一台属于自己的服务器时?
4、水平分库
以行数据为依据,将一个库中的数据拆分到多个库中。大型分表体验一下?坦白说这种策略并不实用,因为会对后台开发很不友好,有很多坑,不建议采用,理解即可。
特点:
- 每个库的结构都一样;
- 每个库的数据都不一样,没有交集;
- 所有库的并集是全量数据;
场景:系统绝对并发量上来了,CPU内存压力大。分表难以根本上解决量的问题,并且还没有明显的业务归属来垂直分库,主库磁盘接近饱和。
其实,在实际工作中,我们在选择分库分表策略前,想到的应该是从缓存、读写分离、SQL优化等方面,因为这些能够更直接、代价更小的解决问题。要记住动表就是动根本,你永远不知道这张表后面会连带多少历史遗留问题,如果是个很大型的项目,遇到些问题你就跟经理提议要分库分表,小心被呼死~
深入追问:
追问1:毫无意义,我真的不想问他MySQL问题了
面试题3:MySQL删除数据的方式都有哪些?
正经回答:
咱们常用的三种删除方式:通过 delete、truncate、drop 关键字进行删除;这三种都可以用来删除数据,但用于的场景不同。
深入追问:
追问1:说一下 delete、truncate、drop的区别吧
一、从执行速度上来说
drop > truncate >> DELETE
二、从原理上讲
DELETE
DELETE from TABLE_NAME where xxx
1.DELETE属于数据库DML操作语言,只删除数据不删除表的结构,会走事务,执行时会触发trigger;
2.在 InnoDB 中,DELETE其实并不会真的把数据删除,mysql 实际上只是给删除的数据打了个标记为已删除,因此 delete 删除表中的数据时,表文件在磁盘上所占空间不会变小,存储空间不会被释放,只是把删除的数据行设置为不可见。虽然未释放磁盘空间,但是下次插入数据的时候,仍然可以重用这部分空间(重用 → 覆盖)。
3.DELETE执行时,会先将所删除数据缓存到rollback segement中,事务commit之后生效;
4.delete from table_name删除表的全部数据,对于MyISAM 会立刻释放磁盘空间,InnoDB 不会释放磁盘空间;
5.对于delete from table_name where xxx 带条件的删除, 不管是InnoDB还是MyISAM都不会释放磁盘空间;
6.delete操作以后使用 optimize table table_name 会立刻释放磁盘空间。不管是InnoDB还是MyISAM 。所以要想达到释放磁盘空间的目的,delete以后执行optimize table 操作。
7.delete 操作是一行一行执行删除的,并且同时将该行的的删除操作日志记录在redo和undo表空间中以便进行回滚(rollback)和重做操作,生成的大量日志也会占用磁盘空间。
- truncate
Truncate table TABLE_NAME
1.truncate:属于数据库DDL定义语言,不走事务,原数据不放到 rollback segment 中,操作不触发 trigger。
执行后立即生效,无法找回
执行后立即生效,无法找回
执行后立即生效,无法找回
2.truncate table table_name 立刻释放磁盘空间 ,不管是 InnoDB和MyISAM 。truncate table其实有点类似于drop table 然后creat,只不过这个create table 的过程做了优化,比如表结构文件之前已经有了等等。所以速度上应该是接近drop table的速度;
3.truncate能够快速清空一个表。并且重置auto_increment的值。
但对于不同的类型存储引擎需要注意的地方是: 对于MyISAM,truncate会重置auto_increment(自增序列)的值为1。
而delete后表仍然保持auto_increment。对于InnoDB,truncate会重置auto_increment的值为1。delete后表仍然保持auto_increment。但是
在做delete整个表之后重启MySQL的话,则重启后的auto_increment会被置为1。
也就是说,InnoDB的表本身是无法持久保存auto_increment。delete表之后auto_increment仍然保存在内存,但是重启后就丢失了,只能从1开始。实质上重启后的auto_increment会从 SELECT 1+MAX(ai_col) FROM t 开始。
4.小心使用 truncate,尤其没有备份的时候,如果误删除线上的表,记得及时联系中国民航,订票电话:400-806-9553
- drop
Drop table Tablename
1.drop:属于数据库DDL定义语言,同Truncate;
执行后立即生效,无法找回
执行后立即生效,无法找回
执行后立即生效,无法找回
2.drop table table_name 立刻释放磁盘空间 ,不管是 InnoDB 和 MyISAM; drop 语句将删除表的结构被依赖的约束(constrain)、触发器(trigger)、索引(index); 依赖于该表的存储过程/函数将保留,但是变为 invalid 状态。
3.小心使用 drop ,要删表跑路的兄弟,请在订票成功后在执行操作!订票电话:400-806-9553
可以这么理解,一本书,delete是把目录撕了,truncate是把书的内容撕下来烧了,drop是把书烧了
总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

Java SSH 秘钥连接mysql数据库的方法
当目标数据库不能直连的,需要一个服务器作为中间跳板的时候,我们需要通过SSH通道连接数据库. ps:使用ssh连接,相当于本地开了个端口去连接远程的服务,就是ssh通道,本地起的项目监听本地的端口,就可以使用这个通道进行数据传输. 1.引入依赖 <dependency> <groupId>com.jcraft</groupId> <artifactId>jsch</artifactId> <version>0.1.55</ver
-
如何让java只根据数据库表名自动生成实体类
根据数据库表名生成实体类 公司用的jpa,没有用mybatis.所以也没有用mybatis自动生成.但有些数据库表字段太多,就想着一劳永逸了,连数据库注释都搞上去 第一种 这里使用的是jdbcTemplate+Junit测试生成,方式可变. SpringBoot版本是2.4.4,只需要加上@SpringBootTest就可以了.不用@RunWith pom: <dependency> <groupId>org.springframework.boot</groupId>
-
三道java新手入门面试题,通往自由的道路--锁+Volatile
目录 1. 你知道volatile是如何保证可见性吗? 小结: 2. 悲观锁和乐观锁可以讲下你的理解吗? 3. 你还知道什么其他的锁吗? 总结 1. 你知道volatile是如何保证可见性吗? 我们先看一组代码: public class VolatileVisibleDemo { public static boolean initFlag = false; public static void main(String[] args) { new Thread(new Runnable() {
-
详解Java数据库连接池
一.什么是数据库连接池 就是一个容器持有多个数据库连接,当程序需要操作数据库的时候直接从池中取出连接,使用完之后再还回去,和线程池一个道理. 二.为什么需要连接池,好处是什么? 1.节省资源,如果每次访问数据库都创建新的连接,创建和销毁都浪费系统资源 2.响应性更好,省去了创建的时间,响应性更好. 3.统一管理数据库连接,避免因为业务的膨胀导致数据库连接的无限增多. 4.便于监控. 三.都有哪些连接池方案 数据库连接池的方案有不少,我接触过的连接池方案有: 1.C3p0 这个连接池我很久之前看到
-
Java面试题冲刺第四天--数据库
目录 面试题1:你对数据库优化有哪些了解呀? 正经回答: 深入追问: 追问1:那你对SQL优化方面有哪些技巧呢? 追问2:嗯,那你说一下为什么不建议用SELECT * 呢? 二.SELECT语句的一些其他优化 面试题2:你对分库分表是怎么看的呀? 正经回答: 1.垂直分表 2.水平分表 3.垂直分库 4.水平分库 深入追问: 追问1:毫无意义,我真的不想问他MySQL问题了 面试题3:MySQL删除数据的方式都有哪些? 正经回答: 深入追问: 追问1:说一下 delete.truncate.dr
-
Java面试题冲刺第十九天--数据库(4)
目录 面试题1:说一下你对聚集索引与非聚集索引的理解,以及他们的区别? 1.聚集索引 2.非聚集索引 追问1:为什么聚集索引可以创建在任何一列上,如果此表没有主键约束,即有可能存在重复行数据呢? 追问2:聚集索引一定比非聚集索引性能优么? 面试题2:说一说你对 B树 和 B+树 的理解吧 1.B树(Balanced Tree)多路平衡查找树 多叉 2.B+ Tree (B+树是B树的变体,也是一种多路搜索树) 面试题3:说一下你对最左前缀原则的理解吧 一.最左匹配原则的原理 二.违背最左原则导致
-
Java面试题冲刺第十三天--数据库(3)
目录 面试题1:MySQL有哪些数据类型? 追问1:char 和 varchar 的区别是什么? 1.固定长度 & 可变长度 2.存储方式 3.存储容量 4.思考:既然VARCHAR长度可变,那我要不要定到最大? 5.在SQL中需要注意的点 追问2:varchar(50).char(50)中50的涵义是什么? 追问3:那int(10)中10的涵义呢?int(1)和int(20)有什么不同? 面试题2:MySQL 的内连接.左连接.右连接有什么区别? 面试题3:MySQL的隐式转换问题遇到过么?说
-
Java面试题冲刺第十二天--数据库(2)
目录 面试题2:并发场景下事务会存在哪些数据问题? 正经回答: 深入追问: 追问1:那Innodb是如何解决幻读问题的呢? 面试题3:说一下MySQL中你都知道哪些锁? 正经回答: 深入追问: 追问1:那你来谈一谈你对表锁.行锁的理解吧. 追问2:那全局锁是什么时候用的呢? 追问2:那你再说一下按锁级别划分的那几种锁的使用场景和理解吧? 总结 面试题1:先说一下什么是MySQL事务吧 正经回答: 简单说,事务就是一组原子性的SQL执行单元.如果数据库引擎能够成功地对数据库应 用该组査询的全部语句
-
Java面试题冲刺第十四天--PRC框架
目录 面试题1:说说你对RPC框架的理解? 追问1:RPC框架实现原理是什么样的 1.建立通信 2.服务寻址 3.网络传输 4.服务调用 面试题2:常见的RPC框架有哪些? 面试题3:说说RPC和SOA.SOAP.REST的区别吧 1.REST 2.SOAP 3.SOA 总结 面试题1:说说你对RPC框架的理解? RPC (Remote Procedure Call)即远程过程调用,是分布式系统常见的一种通信方法.它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不
-
Java面试题冲刺第十四天--基础篇3
目录 面试题1:JDK1.8的新特性有哪些? 接口的默认和静态方法: Lambda 表达式: 方法与构造函数引用: 函数式接口: Annotation 注解:支持多重注解: 新的日期时间 API: Base64编码: JavaScript引擎Nashorn: Stream的使用: Optional: 扩展注解的支持: 并行(parallel)数组: 编译器优化: 其他核心 API 的改进 Java IO改进 集合 API 的改进 面试题2:什么是内部类?内部类的作用? 内部类的作用 内部类特点
-
Java面试题冲刺第二十四天--并发编程
目录 面试题1:说一下你对ReentrantLock的理解? CAS: AQS: 追问1:你认为 ReentrantLock 相比 synchronized 都有哪些区别? 面试题2:解释一下公平锁和非公平锁? 面试题3:能详细说一下CAS具体实现原理么? 追问1:那CAS的缺陷有哪些呢? 1.ABA: 2.自旋消耗资源: 3.多变量共享一致性问题: 追问2:讲一下什么是ABA问题?怎么解决? 总结 面试题1:说一下你对ReentrantLock的理解? ReentrantLock是JDK1.5
-
Java面试题冲刺第二十八天--数据库(5)
目录 面试题1:MySQL数据库cpu飙升到500%的话你会怎么处理? 面试题2:什么是存储过程?有哪些优缺点 优点 在数据库中集中业务逻辑 使数据库更安全 较快的执行速度 缺点 不可移植性 复杂存储过程消耗资源多 故障排除难 维护成本高 面试题3:比如有个用户表,身份证号字段唯一,那么基于这个字段建索引的话,从效率上讲,你会有哪些考虑呢? 总结 面试题1:MySQL数据库cpu飙升到500%的话你会怎么处理? 当 cpu 飙升到 500%时,先用操作系统命令 top 命令观察是不是 mysql
-
Java面试题冲刺第三十天--数据库(6)
目录 面试题1:有个需求需要快速删除MySQL表中一亿条数据,表中有2亿数据,能说一下你的思路么? 1.复制表+删除索引 2.分批插入数据 3.drop删除掉老表 4.重命名新表为new_T 面试题2:刚才你提到了逻辑删除,你是怎么看逻辑删除和物理删除的? 面试题3:大型项目中,mysql的主键需要全局唯一怎么办? 总结 面试题1:有个需求需要快速删除MySQL表中一亿条数据,表中有2亿数据,能说一下你的思路么? 我们知道MySQL删除数据的方式有多种比如DELETE.TRUNCATE.DROP
-
Java面试题冲刺第二十五天--实战编程2
目录 面试题2:怎么理解负载均衡的?你处理负载均衡都有哪些途径? 1.[协议层]http重定向 2.[协议层]DNS轮询 3.[协议层]CDN 4.[协议层]反向代理负载均衡 5.[网络层]IP负载均衡 面试题3:你平时是怎样定位线上问题的? 总结 面试题1:当你发现一条SQL很慢,你的处理思路是什么? 发现Bug 确定Bug不是自己造成的,如果无法确定,不要理会步骤1 向组内宣传"程序里有一个未知Bug,错不在我" 谁响应,谁对Bug负责 没人响应,就要求特定人员配合调试 如果不配合