浅析Python实现DFA算法
一、概述
计算机操作系统中的进程状态与切换可以作为 DFA 算法的一种近似理解。如下图所示,其中椭圆表示状态,状态之间的连线表示事件,进程的状态以及事件都是可确定的,且都可以穷举。
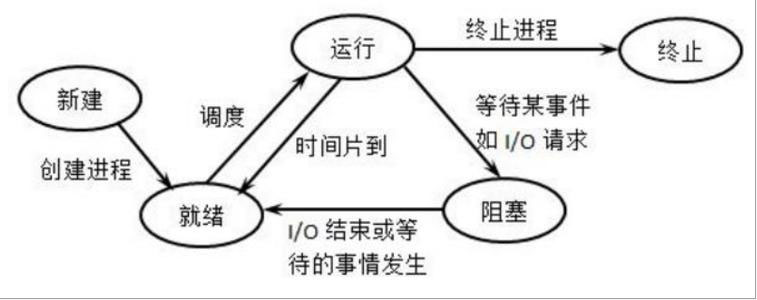
DFA 算法具有多种应用,在此先介绍在匹配关键词领域的应用。
二、匹配关键词
我们可以将每个文本片段作为状态,例如“匹配关键词”可拆分为“匹”、“匹配”、“匹配关”、“匹配关键”和“匹配关键词”五个文本片段。

【过程】:
- 初始状态为空,当触发事件“匹”时转换到状态“匹”;
- 触发事件“配”,转换到状态“匹配”;
- 依次类推,直到转换为最后一个状态“匹配关键词”。
再让我们考虑多个关键词的情况,例如“匹配算法”、“匹配关键词”以及“信息抽取”。
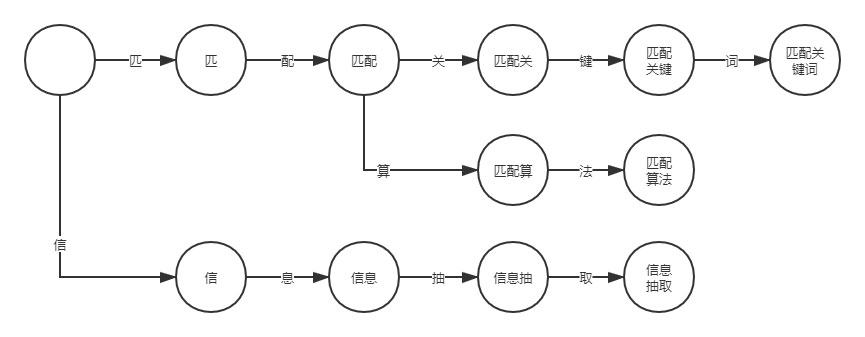
可以看到上图的状态图类似树形结构,也正是因为这个结构,使得 DFA 算法在关键词匹配方面要快于关键词迭代方法(for 循环)。经常刷 LeetCode 的读者应该清楚树形结构的时间复杂度要小于 for 循环的时间复杂度。
for 循环:
keyword_list = []
for keyword in ["匹配算法", "匹配关键词", "信息抽取"]:
if keyword in "DFA 算法匹配关键词":
keyword_list.append(keyword)
for 循环需要遍历一遍关键词表,随着关键词表的扩充,所需的时间也会越来越长。
DFA 算法:找到“匹”时,只会按照事件走向特定的序列,例如“匹配关键词”,而不会走向“匹配算法”,因此遍历的次数要小于 for 循环。具体的实现放在下文中。
【问】:那么如何构建状态图所示的结构呢?
【答】:在 Python 中我们可以使用 dict 数据结构。
state_event_dict = {
"匹": {
"配": {
"算": {
"法": {
"is_end": True
},
"is_end": False
},
"关": {
"键": {
"词": {
"is_end": True
},
"is_end": False
},
"is_end": False
},
"is_end": False
},
"is_end": False
},
"信": {
"息": {
"抽": {
"取": {
"is_end": True
},
"is_end": False
},
"is_end": False
},
"is_end": False
}
}
用嵌套字典来作为树形结构,key 作为事件,通过 is_end 字段来判断状态是否为最后一个状态,如果是最后一个状态,则停止状态转换,获取匹配的关键词。
【问】:如果关键词存在包含关系,例如“匹配关键词”和“匹配”,那么该如何处理呢?
【答】:我们仍然可以用 is_end 字段来表示关键词的结尾,同时添加一个新的字段,例如 is_continue 来表明仍可继续进行匹配。除此之外,也可以通过寻找除 is_end 字段外是否还有其他的字段来判断是否继续进行匹配。例如下面代码中的“配”,除了 is_end 字段外还有“关”,因此还需要继续进行匹配。
state_event_dict = {
"匹": {
"配": {
"关": {
"键": {
"词": {
"is_end": True
},
"is_end": False
},
"is_end": False
},
"is_end": True
},
"is_end": False
}
}
接下来,我们来实现这个算法。
三、算法实现
使用 Python 3.6 版本实现,当然 Python 3.X 都能运行。
3.1、构建存储结构
def _generate_state_event_dict(keyword_list: list) -> dict:
state_event_dict = {}
# 遍历每一个关键词
for keyword in keyword_list:
current_dict = state_event_dict
length = len(keyword)
for index, char in enumerate(keyword):
if char not in current_dict:
next_dict = {"is_end": False}
current_dict[char] = next_dict
current_dict = next_dict
else:
next_dict = current_dict[char]
current_dict = next_dict
if index == length - 1:
current_dict["is_end"] = True
return state_event_dict
关于上述代码仍然有不少可迭代优化的地方,例如先对关键词列表按照字典序进行排序,这样可以让具有相同前缀的关键词集中在一块,从而在构建存储结构时能够减少遍历的次数。
3.2、匹配关键词
def match(state_event_dict: dict, content: str):
match_list = []
state_list = []
temp_match_list = []
for char_pos, char in enumerate(content):
# 首先找到匹配项的起点
if char in state_event_dict:
state_list.append(state_event_dict)
temp_match_list.append({
"start": char_pos,
"match": ""
})
# 可能会同时满足多个匹配项,因此遍历这些匹配项
for index, state in enumerate(state_list):
if char in state:
state_list[index] = state[char]
temp_match_list[index]["match"] += char
# 如果抵达匹配项的结尾,表明匹配关键词完成
if state[char]["is_end"]:
match_list.append(copy.deepcopy(temp_match_list[index]))
# 如果还能继续,则继续进行匹配
if len(state[char].keys()) == 1:
state_list.pop(index)
temp_match_list.pop(index)
# 如果不满足匹配项的要求,则将其移除
else:
state_list.pop(index)
temp_match_list.pop(index)
return match_list
3.3、完整代码
import re
import copy
class DFA:
def __init__(self, keyword_list: list):
self.state_event_dict = self._generate_state_event_dict(keyword_list)
def match(self, content: str):
match_list = []
state_list = []
temp_match_list = []
for char_pos, char in enumerate(content):
if char in self.state_event_dict:
state_list.append(self.state_event_dict)
temp_match_list.append({
"start": char_pos,
"match": ""
})
for index, state in enumerate(state_list):
if char in state:
state_list[index] = state[char]
temp_match_list[index]["match"] += char
if state[char]["is_end"]:
match_list.append(copy.deepcopy(temp_match_list[index]))
if len(state[char].keys()) == 1:
state_list.pop(index)
temp_match_list.pop(index)
else:
state_list.pop(index)
temp_match_list.pop(index)
return match_list
@staticmethod
def _generate_state_event_dict(keyword_list: list) -> dict:
state_event_dict = {}
for keyword in keyword_list:
current_dict = state_event_dict
length = len(keyword)
for index, char in enumerate(keyword):
if char not in current_dict:
next_dict = {"is_end": False}
current_dict[char] = next_dict
current_dict = next_dict
else:
next_dict = current_dict[char]
current_dict = next_dict
if index == length - 1:
current_dict["is_end"] = True
return state_event_dict
if __name__ == "__main__":
dfa = DFA(["匹配关键词", "匹配算法", "信息抽取", "匹配"])
print(dfa.match("信息抽取之 DFA 算法匹配关键词,匹配算法"))
输出:
[
{
'start': 0,
'match': '信息抽取'
}, {
'start': 12,
'match': '匹配'
}, {
'start': 12,
'match': '匹配关键词'
}, {
'start': 18,
'match': '匹配'
}, {
'start': 18,
'match': '匹配算法'
}
]
四、其他用法
4.1、添加通配符
在敏感词识别时往往会遇到同一种类型的句式,例如“你这个傻X”,其中 X 可以有很多,难道我们需要一个个添加到关键词表中吗?最好能够通过类似正则表达式的方法去进行识别。一个简单的做法就是“*”,匹配任何内容。
添加通配符只需要对匹配关键词过程进行修改:
def match(self, content: str):
match_list = []
state_list = []
temp_match_list = []
for char_pos, char in enumerate(content):
if char in self.state_event_dict:
state_list.append(self.state_event_dict)
temp_match_list.append({
"start": char_pos,
"match": ""
})
for index, state in enumerate(state_list):
is_find = False
state_char = None
# 如果是 * 则匹配所有内容
if "*" in state:
state_list[index] = state["*"]
state_char = state["*"]
is_find = True
if char in state:
state_list[index] = state[char]
state_char = state[char]
is_find = True
if is_find:
temp_match_list[index]["match"] += char
if state_char["is_end"]:
match_list.append(copy.deepcopy(temp_match_list[index]))
if len(state_char.keys()) == 1:
state_list.pop(index)
temp_match_list.pop(index)
else:
state_list.pop(index)
temp_match_list.pop(index)
return match_list
main() 函数。
if __name__ == "__main__":
dfa = DFA(["匹配关键词", "匹配算法", "信息*取", "匹配"])
print(dfa.match("信息抽取之 DFA 算法匹配关键词,匹配算法,信息抓取"))
输出:
[
{
'start': 0,
'match': '信息抽取'
}, {
'start': 12,
'match': '匹配'
}, {
'start': 12,
'match': '匹配关键词'
}, {
'start': 18,
'match': '匹配'
}, {
'start': 18,
'match': '匹配算法'
}, {
'start': 23,
'match': '信息抓取'
}
]
以上就是浅析Python实现DFA算法的详细内容,更多关于Python DFA算法的资料请关注我们其它相关文章!
相关推荐
-

C#词法分析器之转换DFA详解
在上一篇文章中,已经得到了与正则表达式等价的 NFA,本篇文章会说明如何从 NFA 转换为 DFA,以及对 DFA 和字符类进行化简. 一.DFA 的表示 DFA 的表示与 NFA 比较类似,不过要简单的多,只需要一个添加新状态的方法即可.Dfa 类的代码如下所示: 复制代码 代码如下: namespace Cyjb.Compiler.Lexer { class Dfa { // 在当前 DFA 中创建一个新状态. DfaState NewState()
-
基于java实现DFA算法代码实例
DFA简介 DFA全称为:Deterministic Finite Automaton,即确定有穷自动机.(自己百度吧) 直接代码: 敏感词实体类 package com.nopsmile.dfa; public class Keywords { private String pid; private String Content; public Keywords() { } public Keywords(String content) { super(); Content = content
-
Java实现DFA算法对敏感词、广告词过滤功能示例
一.前言 开发中经常要处理用户一些文字的提交,所以涉及到了敏感词过滤的功能,参考资料中DFA有穷状态机算法的实现,创建有向图.完成了对敏感词.广告词的过滤,而且效率较好,所以分享一下. 具体实现: 1.匹配大小写过滤 2.匹配全角半角过滤 3.匹配过滤停顿词过滤. 4.敏感词重复词过滤. 例如: 支持如下类型类型过滤检测: fuck 全小写 FuCk 大小写 fuck全角半角 f!!!u&c ###k 停顿词 fffuuuucccckkk 重复词 敏感词过滤的做法有很多,我简单描述我现在理
-
Java使用DFA算法实现过滤多家公司自定义敏感字功能详解
本文实例讲述了Java使用DFA算法实现过滤多家公司自定义敏感字功能.分享给大家供大家参考,具体如下: 背景 因为最近有通讯有个需求,说需要让多家客户公司可以自定义敏感词过滤掉他们自定义的规则,选择了DFA算法来做,不过和以前传统了DFA写法不太一样了 模式图 直接上代码 public class KeywordFilter { // private static ReentrantReadWriteLock lock = new ReentrantReadWriteLock(); public
-
java利用DFA算法实现敏感词过滤功能
前言 敏感词过滤应该是不用给大家过多的解释吧?讲白了就是你在项目中输入某些字(比如输入xxoo相关的文字时)时要能检 测出来,很多项目中都会有一个敏感词管理模块,在敏感词管理模块中你可以加入敏感词,然后根据加入的敏感词去过滤输 入内容中的敏感词并进行相应的处理,要么提示,要么高亮显示,要么直接替换成其它的文字或者符号代替. 敏感词过滤的做法有很多,我简单描述我现在理解的几种: ①查询数据库当中的敏感词,循环每一个敏感词,然后去输入的文本中从头到尾搜索一遍,看是否存在此敏感词,有则做相 应的处理,
-
浅析Python实现DFA算法
一.概述 计算机操作系统中的进程状态与切换可以作为 DFA 算法的一种近似理解.如下图所示,其中椭圆表示状态,状态之间的连线表示事件,进程的状态以及事件都是可确定的,且都可以穷举. DFA 算法具有多种应用,在此先介绍在匹配关键词领域的应用. 二.匹配关键词 我们可以将每个文本片段作为状态,例如"匹配关键词"可拆分为"匹"."匹配"."匹配关"."匹配关键"和"匹配关键词"五个文本片段.
-
Python基于DFA算法实现内容敏感词过滤
DFA 算法是通过提前构造出一个 树状查找结构,之后根据输入在该树状结构中就可以进行非常高效的查找. 设我们有一个敏感词库,词酷中的词汇为: 我爱你 我爱他 我爱她 我爱你呀 我爱他呀 我爱她呀 我爱她啊 那么就可以构造出这样的树状结构: 设玩家输入的字符串为:白菊我爱你呀哈哈哈 我们遍历玩家输入的字符串 str,并设指针 i 指向树状结构的根节点,即最左边的空白节点: str[0] = ‘白’ 时,此时 tree[i] 没有指向值为 ‘白’ 的节点,所以不满足匹配条件,继续往下遍历 str[1
-
深入浅析python中的多进程、多线程、协程
进程与线程的历史 我们都知道计算机是由硬件和软件组成的.硬件中的CPU是计算机的核心,它承担计算机的所有任务. 操作系统是运行在硬件之上的软件,是计算机的管理者,它负责资源的管理和分配.任务的调度. 程序是运行在系统上的具有某种功能的软件,比如说浏览器,音乐播放器等. 每次执行程序的时候,都会完成一定的功能,比如说浏览器帮我们打开网页,为了保证其独立性,就需要一个专门的管理和控制执行程序的数据结构--进程控制块. 进程就是一个程序在一个数据集上的一次动态执行过程. 进程一般由程序.数据集.进程控
-
浅析python 通⽤爬⾍和聚焦爬⾍
一.爬虫的简单理解 1. 什么是爬虫? 网络爬虫也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,爬虫程序通过请求url地址,根据响应的内容进行解析采集数据, 比如:如果响应内容是html,分析dom结构,进行dom解析.或者正则匹配,如果响应内容是xml/json数据,就可以转数据对象,然后对数据进行解析. 2. 爬虫有什么作用? 通过有效的爬虫手段批量采集数据,可以降低人工成本,提高有效数据量,给予运营/销售的数据支撑,加快产品发展. 3. 爬虫业界的情况 目前互
-
浅析Python自带性能强悍的标准库itertools
目录 前言 无限迭代 有限迭代 排列组合迭代 前言 可迭代对象就像密闭容器里的水,有货倒不出 itertools是python内置的标准模块,提供了很多简洁又高效的专用功能,使用得当能够极大的简化代码行数,同时所有方法都是实现了生成器函数,这就意味着极大的节省内存. itertools提供的功能主要分为三大块,以最新版本的3.10为例: 对可迭代对象无限迭代,无限输出 对可迭代对象有限迭代 对可迭代对象排列组合 方法如下: 导入包 >>> from iteratortools imp
-
浅析Python中的for 循环
Python for 和其他语言一样,也可以用来循环遍历对象,本文章向大家介绍Python for 循环的使用方法和实例,需要的朋友可与参考一下. 一个循环是一个结构,导致第一个程序要重复一定次数.重复不断循环的条件仍是如此.当条件变为假,循环结束和程序的控制传递给后面的语句循环. for循环: 在Python for循环遍历序列的任何物品,如一个列表或一个字符串,有能力. for循环语法是: for iterating_var in sequence: statements(s) 如果一个序列
-
python快速查找算法应用实例
本文实例讲述了Python快速查找算法的应用,分享给大家供大家参考. 具体实现方法如下: import random def partition(list_object,start,end): random_choice = start #random.choice(range(start,end+1)) #把这里的start改成random()效率会更高些 x = list_object[random_choice] i = start j = end while True: while li
-
Python数据结构与算法之图结构(Graph)实例分析
本文实例讲述了Python数据结构与算法之图结构(Graph).分享给大家供大家参考,具体如下: 图结构(Graph)--算法学中最强大的框架之一.树结构只是图的一种特殊情况. 如果我们可将自己的工作诠释成一个图问题的话,那么该问题至少已经接近解决方案了.而我们我们的问题实例可以用树结构(tree)来诠释,那么我们基本上已经拥有了一个真正有效的解决方案了. 邻接表及加权邻接字典 对于图结构的实现来说,最直观的方式之一就是使用邻接列表.基本上就是针对每个节点设置一个邻接列表.下面我们来实现一个最简
-
Python基于分水岭算法解决走迷宫游戏示例
本文实例讲述了Python基于分水岭算法解决走迷宫游戏.分享给大家供大家参考,具体如下: #Solving maze with morphological transformation """ usage:Solving maze with morphological transformation needed module:cv2/numpy/sys ref: 1.http://www.mazegenerator.net/ 2.http://blog.leanote.com