利用Pandas来清除重复数据的实现方法
一.前言
最近刚好在练手一个数据挖掘的项目,众所周知,数据挖掘中比较重要的一步为数据清洗,而对重复数据的处理也是数据清洗中经常碰到的一项。本文将仅介绍如何利用Pandas来清除重复数据(主要指重复行),话不多说请看下文。
二.具体介绍
2.1. 导入Pandas库
pandas是python的核心数据分析库,你可以把它理解为python版的excel,倘若你还没有安装相应的库,请查询相关教程进行安装,导入pandas的代码为:
import pandas as pd
2.2. DataFrame.duplicated和DataFrame.drop_duplicates
2.2.1. duplicated函数
duplicated函数的功能为:Return boolean Series denoting duplicate rows,即返回一个标识重复行的布尔类型的数组(Series),其中重复行将标识为true,而非重复行将标识为false。
要介绍该函数的功能,首先我随意创建一个DataFrame对象,该对象的数据如下:
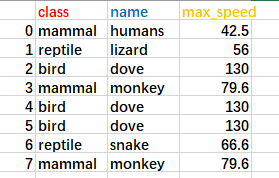
对应的创建代码为
import pandas as pd
#利用字典创建DataFrame对象
animal={'class':['mammal','reptile','bird','mammal','bird','bird','reptile','mammal'],
'name':['humans','lizard','dove','monkey','dove','dove','snake','monkey'],
'max_speed':[42.5,56,130,79.6,130,130,66.6,79.6]}
df = pd.DataFrame(animal)
应用duplicated函数便可以得到对应的bool数组,对应的代码行为
print(df.duplicated())
'''
对应的运行结果为
0 False
1 False
2 False
3 False
4 True
5 True
6 False
7 True
dtype: bool
'''
当然,在应用该函数时,我们可以为其指定参数,其原型为DataFrame.duplicated(self,subset,keep),其中:
subset参数用来指定用来识别重复的列标签/列标签序列,当未指定时默认比较整行的所有列来判别是否重复;
keep参数用来指定如何标记重复行,它的值有三个:first,last,False。当选择first时,重复行中除了第一次出现的全部标记为True;当选择last时,重复行中除最后一次出现的全部标记为True;当选择False时,所有重复行都将标记为True。
上述参数的代码示例为
#指定subset为class
print(df.duplicated('class'))
'''
对应的运行结果
0 False
1 False
2 False
3 True
4 True
5 True
6 True
7 True
dtype: bool
'''
#指定subset为class,name
print(df.duplicated(['class','name']))
'''
对应的运行结果
0 False
1 False
2 False
3 False
4 True
5 True
6 False
7 True
dtype: bool
'''
#指定keep为last
print(df.duplicated(subset=['class','name'],keep='last'))
'''
对应的运行结果
0 False
1 False
2 True
3 True
4 True
5 False
6 False
7 False
dtype: bool
'''
drop_duplicates函数
该函数的作用为:Return DataFrame with duplicate rows removed.即返回一个重复行被移除了的表,该函数的原型为:drop_duplicates(self,subset,keep,inplace),其中:
- subset参数的功能和duplicated函数类似;
- keep参数也与duplicated函数类似,不同的是:在duplicated函数中该函数是决定该标记哪些重复行,而这里是决定该删除那些重复行;
- inplace参数是决定在本对象直接删除重复行(inplace=True, 需显示指定),还是返回一个本对象的副本并删除了对应的重复行(inplace=False, 为默认情况)。
由于subset,keep参数的功能与duplicated参数功能类似,因此这里不做详细演示,下面将展示参数inplace参数在不同情况下代码和运行结果:
#inplace=False时的错误用法,这种情况df并未改变,同时又为获取到对应的副本
df.drop_duplicates()
print(df)
'''
运行结果为
class name max_speed
0 mammal humans 42.5
1 reptile lizard 56.0
2 bird dove 130.0
3 mammal monkey 79.6
4 bird dove 130.0
5 bird dove 130.0
6 reptile snake 66.6
7 mammal monkey 79.6
'''
#inplace=False时的正确用法
df_copy=df.drop_duplicates()
print(df_copy)
'''
运行结果为
class name max_speed
0 mammal humans 42.5
1 reptile lizard 56.0
2 bird dove 130.0
3 mammal monkey 79.6
6 reptile snake 66.6
'''
#inplace=True的情况
df.drop_duplicates(inplace=True)
print(df)
'''
运行结果为
class name max_speed
0 mammal humans 42.5
1 reptile lizard 56.0
2 bird dove 130.0
3 mammal monkey 79.6
6 reptile snake 66.6
'''
三.总结
利用Pandas中的这两个函数你可以清除数据中的重复行,或者加以指定参数你也可以指定删除数据中某项/某几项中重复的数据,总而言之,Pandas大法好!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
pandas取出重复数据的方法
drop_duplicates为我们提供了数据去重的方法,那怎么得到哪些数据有重复呢? 实现步骤: 1.采用drop_duplicates对数据去两次重,一次将重复数据全部去除(keep=False)记为data1,另一次将重复数据保留一个(keep='first)记为data2; 2.求data1和data2的差集即可:data2.append(data1).drop_duplicates(keep=False) 以上这篇pandas取出重复数据的方法就是小编分享给大家的全部内容了,希望能给大
-
利用Pandas来清除重复数据的实现方法
一.前言 最近刚好在练手一个数据挖掘的项目,众所周知,数据挖掘中比较重要的一步为数据清洗,而对重复数据的处理也是数据清洗中经常碰到的一项.本文将仅介绍如何利用Pandas来清除重复数据(主要指重复行),话不多说请看下文. 二.具体介绍 2.1. 导入Pandas库 pandas是python的核心数据分析库,你可以把它理解为python版的excel,倘若你还没有安装相应的库,请查询相关教程进行安装,导入pandas的代码为: import pandas as pd 2.2. DataFrame
-

利用Pandas读取表格行数据判断是否相同的方法
描述: 下午快下班的时候公司供应链部门的同事跑过来问我能不能以程序的方法帮他解决一些excel表格每周都需要手工重复做的事情,Excel 是数据处理最常用的办公工具对于市场.运营都应该很熟练.哈哈,然而程序员是不怎么会用excel的.下面给大家介绍一下pandas, Pandas是一个强大的分析结构化数据的工具集:它的使用基础是Numpy(提供高性能的矩阵运算):用于数据挖掘和数据分析,同时也提供数据清洗功能. 具体需求: 找出相同的数字,把与数字对应的英文字母合并在一起. 期望最终生成值:
-
利用pandas进行大文件计数处理的方法
Pandas读取大文件 要处理的是由探测器读出的脉冲信号,一组数据为两列,一列为时间,一列为脉冲能量,数据量在千万级,为了有一个直接的认识,先使用Pandas读取一些 import pandas as pd data = pd.read_table('filename.txt', iterator=True) chunk = data.get_chunk(5) 而输出是这样的: Out[4]: 332.977889999979 -0.0164794921875 0 332.97790 -0.02
-
Oracle表中重复数据去重的方法实例详解
Oracle表中重复数据去重的方法实例详解 我们在项目中肯定会遇到一种情况,就是表中没有主键 有重复数据 或者有主键 但是部分字段有重复数据 而我们需要过滤掉重复数据 下面是一种解决方法 delete from mytest ms where rowid in (select aa.rid from (select rowid as rid, row_number() over(partition by s.name order by s.id) as nu from mytest s) aa
-
sql删除重复数据的详细方法
一. 删除完全重复的记录 完全重复的数据,通常是由于没有设置主键/唯一键约束导致的.测试数据: 复制代码 代码如下: if OBJECT_ID('duplicate_all') is not nulldrop table duplicate_all GO create table duplicate_all ( c1 int, c2 int, c3 varchar(100) ) GO insert into duplicate_all select 1,100,'aaa' union allse
-
使用aggregate在MongoDB中查询重复数据记录的方法
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*). aggregate() 方法 MongoDB中聚合的方法使用aggregate(). 语法 aggregate() 方法的基本语法格式如下所示: >db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION) 我们知道,MongoDB属于文档型数据库,其存储的文档类型都是JSON对象.正是由于这一特性,我们
-
MySQL中删除重复数据的简单方法
MYSQL里有五百万数据,但大多是重复的,真实的就180万,于是想怎样把这些重复的数据搞出来,在网上找了一圈,好多是用NOT IN这样的代码,这样效率很低,自己琢磨组合了一下,找到一个高效的处理方式,用这个方式,五百万数据,十来分钟就全部去除重复了,请各位参考. 第一步:从500万数据表data_content_152里提取出不重复的字段SFZHM对应的ID字段到TMP3表 create table tmp3 as select min(id) as col1 from data_content
-
Python Pandas读取Excel日期数据的异常处理方法
目录 异常描述 出现原因 解决方案:修改自定义格式 pandas直接解析Excel数值为日期 总结 异常描述 有时我们的Excel有一个调整过自定义格式的日期字段: 当我们用pandas读取时却是这样的效果: 不管如何指定参数都无效. 出现原因 没有使用系统内置的日期单元格格式,自定义格式没有对负数格式进行定义,pandas读取时无法识别出是日期格式,而是读取出单元格实际存储的数值. 解决方案:修改自定义格式 可以修改为系统内置的自定义格式: 或者在自定义格式上补充负数的定义: 增加;@即可 p
-
oracle数据库去除重复数据常用的方法总结
目录 创建测试数据 针对指定列,查出去重后的结果集 distinct row_number() 针对指定列,查出所有重复的行 count having count over 删除所有重复的行 删除重复数据并保留一条 分析函数法 group by 总结 创建测试数据 create table nayi224_180824(col_1 varchar2(10), col_2 varchar2(10), col_3 varchar2(10)); insert into nayi224_180824 s
-
利用Pandas索引和选取数据方法详解
目录 1. 导入数据集 2. 列选择 3. 行选择 数字Index 字符串Index 4. 行+列选择,找到元素 获取北汽2019年11月的销量 获取前5个品牌从2019年10月到12月的销量 5. 条件选择 6. 查找元素位置 在已知列中查找 在整个DataFrame中查找 我们将使用2019年全国新能源汽车的销量数据作为演示数据,数据保存在一个csv文件中,读者可以在GitHub仓库下载到 https://github.com/pythonlibrary/practice-pandas-sk