微服务分布式架构实现日志链路跟踪的方法
Logback 背景
Logback是由log4j创始人设计的另一个开源日志组件,官方网站:http://logback.qos.ch。它当前分为下面下个模块:
- logback-core:其它两个模块的基础模块
- logback-classic:它是log4j的一个改良版本,同时它完整实现了slf4j API使你可以很方便地更换成其它日志系统如log4j或JDK14 Logging
- logback-access:访问模块与Servlet容器集成提供通过Http来访问日志的功能
普通debug日志

SQL执行日志
Logback 配置案例
日志级别排序为:TRACE < DEBUG < INFO < WARN < ERROR
- %d:表示日期
- %n:换行
- %thread:表示线程名
- %level:日志级别
- %msg:日志消息
- %file:表示文件名
- %class:表示文件名
- %logger:Java类名(含包名,这里设定了36位,若超过36位,包名会精简为类似a.b.c.JavaBean)
- %line:Java类的行号

注意:
%-4relative %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread][%X{TRACE_ID}] %-5level %logger{100}.%M\(%line\) - %msg%n
在logback中,%relative表示自应用程序启动以来打印相对时间戳(以毫秒为单位). %-4只是元素的对齐方式.
案例
3452487 2021-08-03 15:19:36.940 [thread-monitor-daemon][] WARN com.xxxx.common.util.MonitorLogger.warn(27) - 发现超时线程notify-replay-consumer...

由于案例中是守护线程thread-monitor-daemon,所以不记录链路ID。
对在系统设计的时候对于线程的命名规范也是有约束的
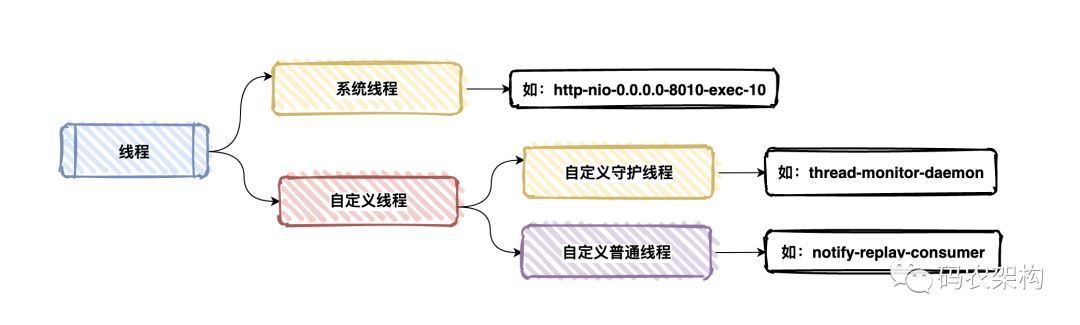
这里就不做详细展开后续有机会会分享。
回归正题比如下面的例子中记录了请求的链路ID
19006989 2021-08-04 22:35:25.776 [http-nio-0.0.0.0-8010-exec-10][1fc8pebmgwukw863w2p342rp2936a3r157w0:0:] INFO com.xxx.framework.eureka.core.listener.EurekaStateChangeListener.listen(58) - 服务实例[XX-PAAS]注册成功,当前服务器已注册服务实例数量[3]

对于上图中显示的系统启动时间、当前时间、当前线程、对应路径按照logback官方配置就可以逐步完善对于的日志信息,但是对于链路ID的生成写入就需要特殊处理。
链路ID设计
对于链路追踪设计我个人比较喜欢两种方案
第一种

在每一次请求中链路编号(traceId)、单元编号(spanId)都是通过HttpHeader的方式进行传递,日志的起始位置会主动生成traceId、spanId,而起始位置的Parent SpanId则是不存在的,值为null。
这样每次通过restTemplate、Openfeign的形式访问其他服务的接口时,就会携带起始位置生成的traceId、spanId到下一个服务单元。
第二种

在每一次请求中链路编号(traceId),没经过一次微服务对于深度(Deep)加1
public static class ThreadTraceListener implements ThreadListener {
@Override
public void onThreadBegin(HttpServletRequest request) {
String traceToken = ThreadLocalUtil.getTranVar(TRACE_ID);
String fromServer = ThreadLocalUtil.getTranVar(FROM_SERVER);
int deep;
String traceId;
if (StringUtils.isBlank(traceToken)) {
traceId = IDGenerator.generateID();
deep = 0;
traceToken = StringHelper.join(traceId, ":0");
} else {
int index = traceToken.lastIndexOf(':');
traceId = traceToken.substring(0, index);
deep = Integer.valueOf(traceToken.substring(index + 1));
}
ThreadLocalUtil.setLocalVar(TRACE_ID, traceId);
ThreadLocalUtil.setLocalVar(TRACE_DEEP, deep);
ThreadLocalUtil.setTranVar(TRACE_ID, StringHelper.join(traceId, ":", deep + 1));
ThreadLocalUtil.setLocalVar(FROM_SERVER, fromServer);
ThreadLocalUtil.setTranVar(FROM_SERVER, getCurrentServer());
MDC.put(TRACE_ID, StringHelper.join(traceToken, ":", fromServer));
}
@Override
public void onThreadEnd(HttpServletRequest request) {
MDC.remove(TRACE_ID);
}
}
针对请求拦截
protected void doFilterInternal(HttpServletRequest request,
HttpServletResponse response,
FilterChain chain) throws ServletException, IOException {
long startTime = System.currentTimeMillis();
// 从Header中装载传递过来的变量
Map<String, Object> tranVar = new HashMap<String, Object>();
Enumeration<String> headers = request.getHeaderNames();
while (headers.hasMoreElements()) {
String key = headers.nextElement();
if (!StringUtils.isEmpty(key)
&& key.startsWith(ThreadLocalUtil.TRAN_PREFIX)) {
tranVar.put(key.substring(ThreadLocalUtil.TRAN_PREFIX.length()),
request.getHeader(key));
}
}
ThreadLocalHolder.begin(tranVar, request);
try {
if (isGateway) {
response.addHeader("X-TRACE-ID", TraceUtil.getTraceId());
}
// 检查RPC调用深度
checkRpcDeep(request, response);
// 业务处理
chain.doFilter(request, response);
// 记录RPC调用次数
logRpcCount(request, response);
} catch (Throwable ex) {
// 错误处理
Response<?> result = ExceptionUtil.toResponse(ex);
Determine determine = ExceptionUtil.determineType(ex);
ExceptionUtil.doLog(result, determine.getStatus(), ex);
response.setStatus(determine.getStatus().value());
response.setCharacterEncoding("UTF-8");
response.setContentType(MediaType.APPLICATION_JSON_UTF8_VALUE);
response.getWriter().write(JsonUtil.toJsonString(result));
} finally {
try {
doMonitor(request, response, startTime);
if (TraceUtil.isTraceLoggerOn()) {
log.warn(StringHelper.join(
"TRACE-HTTP-", request.getMethod(),
" URI:", request.getRequestURI(),
", dt:", System.currentTimeMillis() - startTime,
", rpc:", TraceUtil.getRpcCount(),
", status:", response.getStatus()));
} else if (log.isTraceEnabled()) {
log.trace(StringHelper.join(request.getMethod(),
" URI:", request.getRequestURI(),
", dt:", System.currentTimeMillis() - startTime,
", rpc:", TraceUtil.getRpcCount(),
", status:", response.getStatus()));
}
} finally {
ThreadLocalHolder.end(request);
}
}
}
到此这篇关于微服务分布式架构实现日志链路跟踪的方法的文章就介绍到这了,更多相关微服务分布式架构日志链路跟踪内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Spring Cloud微服务架构的构建:分布式配置中心(加密解密功能)
前言 要会用,首先要了解.图懒得画,借鉴网上大牛的图吧,springcloud组建架构如图: 微服务架构的应用场景: 1.系统拆分,多个子系统 2.每个子系统可部署多个应用,应用之间负载均衡实现 3.需要一个服务注册中心,所有的服务都在注册中心注册,负载均衡也是通过在注册中心注册的服务来使用一定策略来实现. 4.所有的客户端都通过同一个网关地址访问后台的服务,通过路由配置,网关来判断一个URL请求由哪个服务处理.请求转发到服务上的时候也使用负载均衡. 5.服务之间有时候也需要相互访问.例如有一个
-
Python自定义主从分布式架构实例分析
本文实例讲述了Python自定义主从分布式架构.分享给大家供大家参考,具体如下: 环境:Win7 x64,Python 2.7,APScheduler 2.1.2. 原理图如下: 代码部分: (1).中心节点: #encoding=utf-8 #author: walker #date: 2014-12-03 #function: 中心节点(主要功能是分配任务) import SocketServer, socket, Queue CenterIP = '127.0.0.1' #中心节点IP C
-
详解spring cloud分布式日志链路跟踪
首先要明白一点,为什么要使用链路跟踪? 当我们微服务之间调用的时候可能会出错,但是我们不知道是哪个服务的问题,这时候就可以通过日志链路跟踪发现哪个服务出错. 它还有一个好处:当我们在企业中,可能每个人都负责一个服务,我们可以通过日志来检查自己所负责的服务不会出错,当调用其它服务时,这时候出现错误,那么就可以判定出不是自己的服务出错,从而也可以发现责任不是自己的. 基于微服务之间的调用开始,如果看不懂的小伙伴,请先参考我上篇博客:spring cloud中微服务之间的调用以及eureka的自我保护
-
Java高级架构之FastDFS分布式文件集群详解
FastDFS简介 FastDFS是一款开源的轻量级分布式文件系统,使用C实现,支持Linux.BSD等unix-like操作系统.值得注意的是,fastdfs并不是通用的文件系统,只能通过专用的API访问. fastdfs为互联网应用量身定做,解决了大容量文件存储的问题,fastdfs追求高性能和高扩展性.fastdfs的主要概念: tracker-server:跟踪服务器.用于跟踪文件,主要起调度作用.在内存中记录了所有存储组和存储服务器的状态信息,是客户端和数据存储的主要枢纽.相比GFS更
-
微服务分布式架构实现日志链路跟踪的方法
Logback 背景 Logback是由log4j创始人设计的另一个开源日志组件,官方网站:http://logback.qos.ch.它当前分为下面下个模块: logback-core:其它两个模块的基础模块 logback-classic:它是log4j的一个改良版本,同时它完整实现了slf4j API使你可以很方便地更换成其它日志系统如log4j或JDK14 Logging logback-access:访问模块与Servlet容器集成提供通过Http来访问日志的功能 普通debug日志
-
微服务全景架构全面瓦解
目录 1 微服务优势与挑战 1.1 微服务的优势 1.1.1 单一职责 1.1.2 轻量级通信 1.1.3 独立性 1.1.4 进程隔离 1.1.5 混合技术栈和混合部署方式 1.1.6 简化治理 1.1.7 安全可靠,可维护. 1.2 面临的挑战 1.2.1 分布式固有复杂性 1.2.2 服务的依赖管理和测试 1.2.3 有效的配置版本管理 1.2.4 自动化的部署流程 1.2.5 对于DevOps更高的要求 1.2.6 运维成本 2 微服务全景架构 3 微服务核心组件 3.1 服务注册与发现
-
详解spring cloud分布式整合zipkin的链路跟踪
为什么使用zipkin? 上篇主要写了:spring cloud分布式日志链路跟踪 从上篇中可以看出服务之间的调用,假设现在有十几台服务,那么在查找日志的时候比较繁琐.复杂,而且在查看调用的时候也会像蜘蛛网一样,量太大. 这时候zipkin可以把链路调用整个过程给升级起来,只需要到一个地方去查找,就可以知道哪一步出错. zipkin也分为服务器和客户端,服务器就是zipkin,微服务就是客户端. 首先,建立服务器zipkin 在此服务build.gradle加上zipkin的依赖: compil
-
使用MDC实现日志链路跟踪
目录 1.原理 2.实现 3.过滤器 4.logback.xml 5.返回体 6.效果日志 前言: 在微服务环境中,我们经常使用Skywalking.CAT等去实现整体请求链路的追踪,但是这个整体运维成本高,架构复杂,我们来使用MDC通过Log来实现一个轻量级的会话事务跟踪功能. 1.原理 MDC org.sl4j.MDC其实内部就是ThreadLocal,MDC提供了put/get/clear等几个核心接口,用于操作ThreadLocal中的数据:ThreadLocal中的K-V,可以在log
-
Spring Cloud 整合Apache-SkyWalking实现链路跟踪的方法
什么是SkyWalking 查看官网https://skywalking.apache.org/ 分布式系统的应用程序性能监视工具,专为微服务.云原生架构和基于容器(Docker.K8s.Mesos)架构而设计. 安装 进入下载页面https://skywalking.apache.org/zh/downloads/ 这里用的是ElasticSearch 7版本,所以你需要安装完成ElasticSearch 7,不再赘述. 解压后,可以修改启动端口 apache-skywalking-apm-b
-
go micro集成链路跟踪的方法和中间件原理解析
目录 链路跟踪实战 安装zipkin 程序结构 安装依赖包 编写服务端 编写客户端 Wrap原理分析 服务端Wrap HandlerWrapper Wrap Handler 客户端Wrap XXXWrapper Wrap Client 客户端Wrap和服务端Wrap的区别 Http服务的链路跟踪 前几天有个同学想了解下如何在go-micro中做链路跟踪,这几天正好看到wrapper这块,wrapper这个东西在某些框架中也称为中间件,里边有个opentracing的插件,正好用来做链路追踪.op
-
微服务领域Spring Boot自动伸缩的实现方法
前言 自动伸缩是每个人都想要的,尤其是在微服务领域.让我们看看如何在基于Spring Boot的应用程序中实现. 我们决定使用Kubernetes.Pivotal Cloud Foundry或HashiCorp's Nomad等工具的一个更重要的原因是为了让系统可以自动伸缩.当然,这些工具也提供了许多其他有用的功能,在这里,我们只是用它们来实现系统的自动伸缩.乍一看,这似乎很困难,但是,如果我们使用Spring Boot来构建应用程序,并使用Jenkins来实现CI,那么就用不了太多工作. 今天
-
SpringCloud分布式链路跟踪的方法
注:作者使用IDEA + Gradle 注:需要有一定的java SpringBoot and SSM+Springcloud基础 程序测试错误追责 我举个例子,我现在要做一个电商项目,项目里面有一个购买模块,那我这边可能要执行一个代码,比如减库存之类的东西,那我两个服务不就是要相互调用嘛,我自身是一个服务,我现在要调用减库存这个服务: 你调用它,你知道它一定能执行成功吗?肯定是不一定: 比如说,我现在要执行一个减库存的代码,我调用这个方法会进行库存的一个更改,这个库存减少成功还好,万一要是失败
-
教你Spring Cloud保证各个微服务之间调用安全性
导读:在微服务的架构下,系统会根据业务拆分为多个服务,各自负责单一的职责,在这样的架构下,我们需要确保各api的安全性,也就是说服务不是开放的,而是需要授权才可访问的,避免接口被不合法的请求所访问. 但是在在微服务集群中服务之间暴力的接口,或者对于第三方开放的接口如果不做及安全和认证,后果可想而知. 阅读下文之前思考几个问题: 如何在restTemplate远程调用请求增加添加统一认证? 服务认证如何规范加密和解密? 远程调用统一什么协议比较合适? 如下图,三个服务注册到同一个注册中心集群,服务