Python读取配置文件-ConfigParser的二次封装方法
目录
- Python读取配置文件-ConfigParser二次封装
- 直接上上代码
- 读取配置文件&&简单封装
- 1.configparser模块
- 2.configparser读取文件的基本方法
- 3.引入os模块,使用相对目录读取配置文件
- 4.通过读取配置文件
Python读取配置文件-ConfigParser二次封装
直接上上代码
test.conf
[database] connect = mysql sleep = no test = yes
config.py
# -*- coding:utf-8 -*-
__author__ = 'guoqianqian'
import os
import ConfigParser
import os
current_dir = os.path.abspath(os.path.dirname(__file__))
class OperationalError(Exception):
"""operation error."""
class Dictionary(dict):
""" custom dict."""
def __getattr__(self, key):
return self.get(key, None)
__setattr__ = dict.__setitem__
__delattr__ = dict.__delitem__
class Config:
def __init__(self, file_name="test", cfg=None):
"""
@param file_name: file name without extension.
@param cfg: configuration file path.
"""
env = {}
for key, value in os.environ.items():
if key.startswith("TEST_"):
env[key] = value
config = ConfigParser.ConfigParser(env)
if cfg:
config.read(cfg)
else:
config.read(os.path.join(current_dir, "conf", "%s.conf" % file_name))
for section in config.sections():
setattr(self, section, Dictionary())
for name, raw_value in config.items(section):
try:
# Ugly fix to avoid '0' and '1' to be parsed as a
# boolean value.
# We raise an exception to goto fail^w parse it
# as integer.
if config.get(section, name) in ["0", "1"]:
raise ValueError
value = config.getboolean(section, name)
except ValueError:
try:
value = config.getint(section, name)
except ValueError:
value = config.get(section, name)
setattr(getattr(self, section), name, value)
def get(self, section):
"""Get option.
@param section: section to fetch.
@return: option value.
"""
try:
return getattr(self, section)
except AttributeError as e:
raise OperationalError("Option %s is not found in "
"configuration, error: %s" %
(section, e))
if __name__ == "__main__":
conf = Config()
print conf.get("database").connect
print conf.get("database").sleep
print conf.get("database").test
执行结果
mysql
False
True
目录结构
demo conf test.conf config.py
读取配置文件&&简单封装
之前有做过把爬虫数据写到数据库中的练习,这次想把数据库信息抽离到一个ini配置文件中,这样做的好处在于可以在配置文件中添加多个数据库,方便切换(另外配置文件也可以添加诸如邮箱、url等信息)
1.configparser模块
python使用自带的configparser模块用来读取配置文件,配置文件的形式类似windows中的ini文件
在使用前需要先安装该模块,使用pip安装即可
2.configparser读取文件的基本方法
(1)新建一个config.ini文件,如下
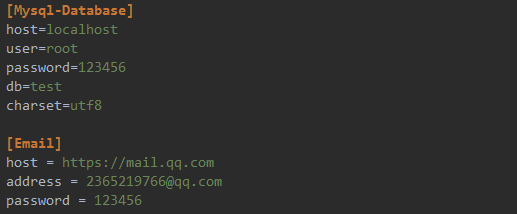
(2)新建一个readconfig.py文件,读取配置文件的信息
import configparser
cf = configparser.ConfigParser()
cf.read("E:\Crawler\config.ini") # 读取配置文件,如果写文件的绝对路径,就可以不用os模块
secs = cf.sections() # 获取文件中所有的section(一个配置文件中可以有多个配置,如数据库相关的配置,邮箱相关的配置, 每个section由[]包裹,即[section]),并以列表的形式返回
print(secs)
options = cf.options("Mysql-Database") # 获取某个section名为Mysql-Database所对应的键
print(options)
items = cf.items("Mysql-Database") # 获取section名为Mysql-Database所对应的全部键值对
print(items)
host = cf.get("Mysql-Database", "host") # 获取[Mysql-Database]中host对应的值
print(host)
上述代码运行结果如下,可以和config.ini进行对比

3.引入os模块,使用相对目录读取配置文件
工程目录如下:
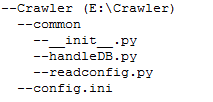
readconfig.py:
import configparser
import os
root_dir = os.path.dirname(os.path.abspath('.')) # 获取当前文件所在目录的上一级目录,即项目所在目录E:\Crawler
cf = configparser.ConfigParser()
cf.read(root_dir+"/config.ini") # 拼接得到config.ini文件的路径,直接使用
secs = cf.sections() # 获取文件中所有的section(一个配置文件中可以有多个配置,如数据库相关的配置,邮箱相关的配置,每个section由[]包裹,即[section]),并以列表的形式返回
print(secs)
options = cf.options("Mysql-Database") # 获取某个section名为Mysql-Database所对应的键
print(options)
items = cf.items("Mysql-Database") # 获取section名为Mysql-Database所对应的全部键值对
print(items)
host = cf.get("Mysql-Database", "host") # 获取[Mysql-Database]中host对应的值
print(host)
或者使用os.path.join()进行拼接
import configparser
import os
root_dir = os.path.dirname(os.path.abspath('.')) # 获取当前文件所在目录的上一级目录,即项目所在目录E:\Crawler
configpath = os.path.join(root_dir, "config.ini")
cf = configparser.ConfigParser()
cf.read(configpath) # 读取配置文件
secs = cf.sections() # 获取文件中所有的section(一个配置文件中可以有多个配置,如数据库相关的配置,邮箱相关的配置,每个section由[]包裹,即[section]),并以列表的形式返回
print(secs)
options = cf.options("Mysql-Database") # 获取某个section名为Mysql-Database所对应的键
print(options)
items = cf.items("Mysql-Database") # 获取section名为Mysql-Database所对应的全部键值对
print(items)
host = cf.get("Mysql-Database", "host") # 获取[Mysql-Database]中host对应的值
print(host)
4.通过读取配置文件
重新写一下之前的requests+正则表达式爬取猫眼电影的例子
把读取配置文件readconfig.py和操作数据库handleDB.py分别封装到一个类中
readconfig.py如下
import configparser
import os
class ReadConfig:
"""定义一个读取配置文件的类"""
def __init__(self, filepath=None):
if filepath:
configpath = filepath
else:
root_dir = os.path.dirname(os.path.abspath('.'))
configpath = os.path.join(root_dir, "config.ini")
self.cf = configparser.ConfigParser()
self.cf.read(configpath)
def get_db(self, param):
value = self.cf.get("Mysql-Database", param)
return value
if __name__ == '__main__':
test = ReadConfig()
t = test.get_db("host")
print(t)
handleDB.py如下
# coding: utf-8
# author: hmk
from common.readconfig import ReadConfig
import pymysql.cursors
class HandleMysql:
def __init__(self):
self.data = ReadConfig()
def conn_mysql(self):
"""连接数据库"""
host = self.data.get_db("host")
user = self.data.get_db("user")
password = self.data.get_db("password")
db = self.data.get_db("db")
charset = self.data.get_db("charset")
self.conn = pymysql.connect(host=host, user=user, password=password, db=db, charset=charset)
self.cur = self.conn.cursor()
def execute_sql(self, sql, data):
"""执行操作数据的相关sql"""
self.conn_mysql()
self.cur.execute(sql, data)
self.conn.commit()
def search(self, sql):
"""执行查询sql"""
self.conn_mysql()
self.cur.execute(sql)
return self.cur.fetchall()
def close_mysql(self):
"""关闭数据库连接"""
self.cur.close()
self.conn.close()
if __name__ == '__main__':
test = HandleMysql()
sql = "select * from maoyan_movie"
for i in test.search(sql):
print(i)
最后的运行文件,调用前面的方法
# coding: utf-8
# author: hmk
import requests
import re
from common import handleDB
class Crawler:
"""定义一个爬虫类"""
def __init__(self):
self.db = handleDB.HandleMysql()
@staticmethod
def get_html(url, header):
response = requests.get(url=url, headers=header)
if response.status_code == 200:
return response.text
else:
return None
@staticmethod
def get_data(html, list_data):
pattern = re.compile(r'<dd>.*?<i.*?>(\d+)</i>.*?' # 匹配电影排名
r'<p class="name"><a.*?data-val=".*?">(.*?)' # 匹配电影名称
r'</a>.*?<p.*?class="releasetime">(.*?)</p>' # 匹配上映时间
r'.*?<i.*?"integer">(.*?)</i>' # 匹配分数的整数位
r'.*?<i.*?"fraction">(.*?)</i>.*?</dd>', re.S) # 匹配分数小数位
m = pattern.findall(html)
for i in m: # 因为匹配到的所有结果会以列表形式返回,每部电影信息以元组形式保存,所以可以迭代处理每组电影信息
ranking = i[0] # 提取一组电影信息中的排名
movie = i[1] # 提取一组电影信息中的名称
release_time = i[2] # 提取一组电影信息中的上映时间
score = i[3] + i[4] # 提取一组电影信息中的分数,这里把分数的整数部分和小数部分拼在一起
list_data.append([ranking, movie, release_time, score]) # 每提取一组电影信息就放到一个列表中,同时追加到一个大列表里,这样最后得到的大列表就包含所有电影信息
def write_data(self, sql, data):
self.db.conn_mysql()
try:
self.db.execute_sql(sql, data)
print('导入成功')
except:
print('导入失败')
self.db.close_mysql()
def run_main(self):
start_url = 'http://maoyan.com/board/4'
depth = 10 # 爬取深度(翻页)
header = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, sdch",
"Accept-Language": "zh-CN,zh;q=0.8",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Host": "maoyan.com",
"Referer": "http://maoyan.com/board",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36"}
for i in range(depth):
url = start_url + '?offset=' + str(10 * i)
html = self.get_html(url, header)
list_data = []
self.get_data(html, list_data)
for i in list_data:
"""这里的list_data参数是指正则匹配并处理后的列表数据(是一个大列表,包含所有电影信息,每个电影信息都存在各自的一个列表中;
对大列表进行迭代,提取每组电影信息,这样提取到的每组电影信息都是一个小列表,然后就可以把每组电影信息写入数据库了)"""
movie = i # 每组电影信息,这里可以看做是准备插入数据库的每组电影数据
sql = "insert into maoyan_movie(ranking,movie,release_time,score) values(%s, %s, %s, %s)" # sql插入语句
self.write_data(sql, movie)
if __name__ == '__main__':
test = Crawler()
test.run_main()
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

如何利用python 读取配置文件
引言 在编写接口自动化测试脚本时,有时我们需要在代码中定义变量并给变量固定的赋值.为了统一管理和操作这些固定的变量,咱们一般会将这些固定的变量以一定规则配置到指定的配置文件中,后续需要用到这些变量和变量值时通过代码读取或者写入数据到该配置文件即可,使用配置文件的好处就是不用在程序员写死,可以使程序更灵活.因而对于python语言就封装了configparser模块,用来处理指定格式的文件(文件名称一般为xxx.ini),配置文件的格式跟windows下的ini配置文件相似,可以包含一个或多个节(
-
Python实现读取Properties配置文件的方法
本文实例讲述了Python实现读取Properties配置文件的方法.分享给大家供大家参考,具体如下: JAVA本身提供了对于Properties文件操作的类,项目中的很多配置信息都是放在了Properties文件.但是Python并没有提供操作Properties文件的库,所以,自己动手写个一个可以加载Properties文件的脚本. class Properties: fileName = '' def __init__(self, fileName): self.fileName = fi
-
python读取ini配置的类封装代码实例
这篇文章主要介绍了python读取ini配置的类封装代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 此为基础封装,未考虑过多异常处理 类 # coding:utf-8 import configparser import os class IniCfg(): def __init__(self): self.conf = configparser.ConfigParser() self.cfgpath = '' def checkSec
-
Python读取配置文件-ConfigParser的二次封装方法
目录 Python读取配置文件-ConfigParser二次封装 直接上上代码 读取配置文件&&简单封装 1.configparser模块 2.configparser读取文件的基本方法 3.引入os模块,使用相对目录读取配置文件 4.通过读取配置文件 Python读取配置文件-ConfigParser二次封装 直接上上代码 test.conf [database] connect = mysql sleep = no test = yes config.py # -*- coding:u
-
python的schedule定时任务模块二次封装方法
通过定时来执行任务,我们日常工作生活中会经常用到.python有schedule这个库,简单好用,比如,可以每秒,每分,每小时,每天,每天的某个时间点,间隔天数的某个时间点定时执行,另外自己又写了一个可以自定义时间点来定时执行任务,代码如下. import schedule import time class Timing(): #按秒循环定时执行任务 def doEverySecond(self,seconds,job_func): try: schedule.every(seconds).s
-
Python读取配置文件(config.ini)以及写入配置文件
一.读取配置文件 我的目录如下,在config下有一个config.ini配置文件 配置文件内容 # 定义config分组 [config] platformName=Android appPackage=com.romwe appActivity=com.romwe.SplashActivity # 定义cmd分组 [cmd] viewPhone=adb devices startServer=adb start-server stopServer=adb kill-server instal
-
python读取配置文件方式(ini、yaml、xml)
零.前言 python代码中配置文件是必不可少的内容.常见的配置文件格式有很多中:ini.yaml.xml.properties.txt.py等. 一.ini文件 1.1 ini文件的格式 ; 注释内容 [url] ; section名称 baidu = https://www.jb51.net port = 80 [email] sender = 'xxx@qq.com' 注意section的名称不可以重复,注释用分号开头. 1.2 读取 configparser python自带的confi
-
Python读取配置文件的实战操作
目录 一. yaml 1. 准备 2. 操作数据 2.1 读取数据 二. ini 1.准备 2. 操作数据 2.1 读取数据 2.2. 写数据 三. xml 1. 准备 2. 操作数据 2.1 读取数据 2.2 写入数据 四. env 1. 准备 2. 读取文件 五. json 1. 准备 2. 操作数据 六. toml 1. 准备 2. 操作数据 2.1 读取数据 2.2 写入数据 七. HOCON 1. 准备 2. 数据操作 2.1 读取数据 总结 一. yaml 1. 准备 支持的数据类型
-
Python如何实现Paramiko的二次封装
Paramiko是一个用于执行SSH命令的Python第三方库,使用该库可实现自动化运维的所有任务,如下是一些常用代码的封装方式,多数代码为半成品,只是敲代码时的备份副本防止丢失,仅供参考. 目前本人巡检百台设备完全无压力,如果要巡检过千台则需要多线程的支持,过万台则需要加入智能判断等. 实现命令执行: 直接使用过程化封装,执行CMD命令. import paramiko ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(par
-
python读取几个G的csv文件方法
如下所示: import pandas as pd file = pd.read_csv('file.csv',iterator=True) while True: chunk = file.get_chunk(1000) print(chunk.head(10)) print(chunk.tail(10)) 以上这篇python读取几个G的csv文件方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Python读取excel中的图片完美解决方法
excel中有图片是很常见的,但是通过python读取excel中的图片没有很好的解决办法. 网上找了一种很聪明的方法,原理是这样的: 1.将待读取的excel文件后缀名改成zip,变成压缩文件. 2.再解压这个文件. 3.在解压后的文件夹中,就有excel中的图片. 4.这样读excel中的图片,就变成了读文件夹中的图片了,和普通文件一样,可以做各种处理. 解压后的压缩包如下: python脚本如下: ''' File Name: readexcelimg Author: tim Date:
-
python读取目录下最新的文件夹方法
如下所示: def new_report(test_report): lists = os.listdir(test_report) # 列出目录的下所有文件和文件夹保存到lists lists.sort(key=lambda fn: os.path.getmtime(test_report + "/" + fn)) # 按时间排序 file_new = os.path.join(test_report, lists[-1]) # 获取最新的文件保存到file_new print(fi