python正则表达式的懒惰匹配和贪婪匹配说明
第一次碰到这个问题的时候,确实不知道该怎么办,后来请教了一个大神,加上自己的理解,才了解是什么意思,这个东西写python的会经常用到,而且会特别频繁,在此写一篇博客,希望可以帮到一些朋友。
例:一个字符串 “abcdacsdnd”
①懒惰匹配
regex = "a.*?d"
②贪婪匹配
regex = "a.*d"
测试代码:
# coding=UTF-8
import re
str = "abcdacsdn"
print("原始字符串 " + str)
# 懒惰匹配
regexL = "a.*?d"
print("懒惰匹配 = " + regexL)
regL = re.compile(regexL)
listL = re.findall(regL, str)
print("懒惰匹配结果")
print(listL)
# 贪婪匹配
regexT = "a.*d"
print("贪婪匹配 = " + regexT)
regT = re.compile(regexT)
listT = re.findall(regT, str)
print("贪婪匹配结果")
print(listT)
测试结果:
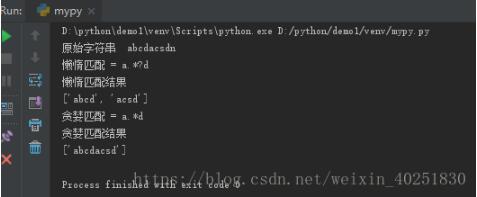
结果分析:
懒惰匹配,匹配成功两次,一次abcd,一次acsd,匹配到满足条件的abcd就停止了此次匹配,不会干扰后面的继续匹配。
贪婪匹配,匹配成功一次,只有abcdacsd,匹配到字符串后,会最大限度的占用字符串
以上两种,一个是尽量匹配最短串,一个是匹配最长串。
补充知识:python正则匹配中贪婪匹配效率比较
用例回归完成之后,一般都要生成一个summary_report.但是,发现生成报告的时间耗时很久,搜集资料发现与匹配文件内容使用的正则表达式有很大关系.
1.匹配模式说明
下图中圈住的部分,没有注释掉的使用贪婪匹配,注释掉的使用非贪婪匹配

执行时间上二者差别巨大;另外执行时间与正则表达式的长度也有关系,较长的表达式建议分段匹配.
2.贪婪匹配时间

3.非贪婪匹配时间

以上这篇python正则表达式的懒惰匹配和贪婪匹配说明就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python贪婪匹配以及多行匹配的实例讲解
1 非贪婪flag >>> re.findall(r"a(\d+?)", "a23b") ['2'] >>> re.findall(r"a(\d+)", "a23b") ['23'] 注意比较这种情况: >>> re.findall(r"a(\d+)b", "a23b") ['23'] >>> re.findall(
-
python re模块匹配贪婪和非贪婪模式详解
这篇文章主要介绍了python re模块匹配贪婪和非贪婪模式详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 python贪婪和非贪婪 正则表达式通常用于在文本中查找匹配的字符串.Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符:非贪婪则相反,总是尝试匹配尽可能少的字符.在"*","?","+","{m,n}"后面加上?,使贪婪
-
Python正则表达式教程之三:贪婪/非贪婪特性
之前已经简单介绍了Python正则表达式的基础与捕获,那么在这一篇文章里,我将总结一下正则表达式的贪婪/非贪婪特性. 贪婪 默认情况下,正则表达式将进行贪婪匹配.所谓"贪婪",其实就是在多种长度的匹配字符串中,选择较长的那一个.例如,如下正则表达式本意是选出人物所说的话,但是却由于"贪婪"特性,出现了匹配不当: >>> sentence = """You said "why?" and I say
-
python 正则表达式贪婪模式与非贪婪模式原理、用法实例分析
本文实例讲述了python 正则表达式贪婪模式与非贪婪模式原理.用法.分享给大家供大家参考,具体如下: 之前未接触过正则表达式,今日看python网络爬虫的源码,里面一行正则表达式匹配的代码初看之下,不是很理解,代码如下: myItems = re.findall('<div.*?class="content".*?title="(.*?)">(.*?)</div>',unicodePage,re.S) ".*?"这种匹配
-
python正则表达式的懒惰匹配和贪婪匹配说明
第一次碰到这个问题的时候,确实不知道该怎么办,后来请教了一个大神,加上自己的理解,才了解是什么意思,这个东西写python的会经常用到,而且会特别频繁,在此写一篇博客,希望可以帮到一些朋友. 例:一个字符串 "abcdacsdnd" ①懒惰匹配 regex = "a.*?d" ②贪婪匹配 regex = "a.*d" 测试代码: # coding=UTF-8 import re str = "abcdacsdn" print(
-
js正则表达式惰性匹配和贪婪匹配用法分析
本文实例讲述了js正则表达式惰性匹配和贪婪匹配用法.分享给大家供大家参考,具体如下: 在讲贪婪模式和惰性模式之前,先回顾一下JS正则基础: 写法基础: ①不需要双引号,直接用//包含 => /wehfwue123123/.test(); ②反斜杠\表示转义 =>/\.jpg$/ ③用法基础:.test(str); 语法: ①锚点类 /^a/=>以"a"开头 /\.jpg$/=>以".jpg"结尾 ②字符类 [abc]:a或b或c [0-9]:
-
Python正则表达式基本原理
目录 ️正则表达式 正则表达式是什么? 1.实例引入 2.match() 匹配目标 贪婪匹配 3.findall() 常用符号 特殊字符 总结 ️正则表达式 大家好,大家都听过正则表达式,却不知道正则表达式干什么的.正则表达式是一个特殊的符号系列,它可以帮助我们检查某个字符串和某种模式匹配.在python中,re库拥有全部的正则表达式的功能. 今天,我们来深入的了解一下.我们知道正则表达式是处理字符串的强大工具,它有自己的语法结构,什么匹配啊,都不算什么. 正则表达式是什么? 正则表达式,又称规
-
js正则表达式最长匹配(贪婪匹配)和最短匹配(懒惰匹配)用法分析
本文实例分析了js正则表达式最长匹配(贪婪匹配)和最短匹配(懒惰匹配)用法.分享给大家供大家参考,具体如下: 最近在阅读RequireJS 2.1.15源码,源码开始处定义了一系列的变量,有4个正则表达式: var commentRegExp = /(\/\*([\s\S]*?)\*\/|([^:]|^)\/\/(.*)$)/mg, cjsRequireRegExp = /[^.]\s*require\s*\(\s*["']([^'"\s]+)["']\s*\)/g, jsS
-
Python正则表达式非贪婪、多行匹配功能示例
本文实例讲述了Python正则表达式非贪婪.多行匹配功能.分享给大家供大家参考,具体如下: 一些regular的tips: 1 非贪婪flag >>> re.findall(r"a(\d+?)","a23b") # 非贪婪模式 ['2'] >>> re.findall(r"a(\d+)","a23b") ['23'] 注意比较这种情况: >>> re.findall(r&q
-

python 正则表达式如何实现重叠匹配
目录 正则表达式实现重叠匹配 正则表达式与正则匹配 正则表达式 正则匹配 正则表达式实现重叠匹配 import regex string = '100101010001' str_re = '101' print(regex.findall(str_re, string, overlapped=True)) 普通的re库匹配,只能匹配一个’101’. 正则表达式与正则匹配 正则表达式 正则表达式可理解为对数据筛选的表达式,是有限个原子和元字符组成. 原子:基本组成单位,每个表达式至少有一个原子
-
Python正则表达式匹配中文用法示例
本文实例讲述了Python正则表达式匹配中文用法.分享给大家供大家参考,具体如下: #!/usr/bin/python #-*- coding:cp936-*-#思路,将str转换成unicode,方可用正则表达式,前提是,要知道文件的编码,本例中是gbk import cPickle as mypickle import re import sys if (__name__=='__main__'): fid1=file('demo.txt','r');#demo.txt写入字符如:我们 p=
-
JavaScript正则表达式的贪婪匹配和非贪婪匹配
所谓贪婪匹配就是匹配重复字符是尽可能多的匹配,比如: "aaaaa".match(/a+/); //["aaaaa", index: 0, input: "aaaaa"] 非贪婪匹配就是尽可能少的匹配,用法就是在量词后面加上一个"?",比如: "aaaaa".match(/a+?/); //["a", index: 0, input: "aaaaa"] 但是非贪婪匹配
-
Python 正则表达式匹配字符串中的http链接方法
利用Python正则表达式匹配字符串中的http链接.主要难点是用正则表示出http 链接的模式. import re pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+') # 匹配模式 string = 'Its after 12 noon, do you know where your rooftops are? http://tinyur