mybatis collection和association的区别解析
目录
- 1.collection标签
- 1.1 相关代码和运行结果
- 1.2 collection部分源码解析
- 1.3 <collection>和<association>的相同的和不同点
- 最后
1.collection标签
说到mybatis的collection标签,我们肯定不陌生,可以通过它解决一对多的映射问题,举个例子一个用户对应多个系统权限,通过对用户表和权限表的关联查询我们可以得到好多条记录,但是用户信息这部分在多条记录中是重复的,只有权限不同,我们需要把这多条权限记录映射到这个用户之中,这个时候可以通过collection标签/association标签来解决(虽然assocation标签一般是解决一对一问题的,但它实际上也能实现我们的需求,可以通过后面的源码看出来)
1.1 相关代码和运行结果
实体类和mapper代码
public class Test {
public static void main(String[] args) throws IOException {
try (InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml")) {
// 构建session工厂 DefaultSqlSessionFactory
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
UserDO userDO = userMapper.getByUserId(1);
System.out.println(userDO);
}
}
}
运行结果如下,可以看到权限记录映射到属性permitDOList 的list列表了

1.2 collection部分源码解析
通过PreparedStatement查询完之后得到ResultSet结果集,之后需要将结果集解析为java的pojo类中,下面通过源码简单讲下是如何解析的
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
// 是否有嵌套的resultMaps
if (resultMap.hasNestedResultMaps()) {
ensureNoRowBounds();
checkResultHandler();
handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
} else {
// 无嵌套
handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
}
根据有无嵌套分成两层逻辑,有嵌套resultMaps就是指<resultMap>标签下有子标签<collection>或<association>,分析下第一层
private void handleRowValuesForNestedResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
final DefaultResultContext<Object> resultContext = new DefaultResultContext<>();
ResultSet resultSet = rsw.getResultSet();
// 跳过offset行
skipRows(resultSet, rowBounds);
// 上一次获取的数据
Object rowValue = previousRowValue;
// 已获取记录数量小于limit
while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {
// 鉴别器解析
final ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null);
// 创建缓存key resultMapId + (columnName + columnValue)....
final CacheKey rowKey = createRowKey(discriminatedResultMap, rsw, null);
// 部分对象(可能存在对象内容缺失未完全合并)
Object partialObject = nestedResultObjects.get(rowKey);
// issue #577 && #542
// 关于resultOrdered的理解,举例若查询得到四条记录a,a,b,a , 相同可以合并。
// 那么当resultOrdered=true时,最后可以得到三条记录,第一条和第二条合并成一条、第三条单独一条、第四条也是单独一条记录
// resultOrdered=false时,最后可以得到两条记录,第一条、第二条和第四条会合并成一条,第三条单独一条记录
// 另外存储到resultHandler的时机也不一样,resultOrdered=true是等遇到不可合并的记录的时候才把之前已经合并的记录存储,
// 而resultOrdered=false是直接存储的后续有合并的记录再处理添加到集合属性中
if (mappedStatement.isResultOrdered()) {
// partialObject为null,说明这一条记录不可与上一条记录进行合并了,那么清空nestedResultObjects防止之后出现有可合并的记录的时候继续合并
// 然后将记录存储到resultHandler里面
if (partialObject == null && rowValue != null) {
nestedResultObjects.clear();
storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
}
rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, null, partialObject);
} else {
// 处理resultSet的当前这一条记录
rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, null, partialObject);
if (partialObject == null) {
// 将记录存储到resultHandler里面
storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
}
}
}
这段代码主要是创建了一个缓存key,主要是根据resultMapId和<id>标签的column和对应的columvalue来创建的(若没有<id>标签,则会使用所有的<result>标签的column和columnValue来创建),以此缓存键来区分记录是否可合并。nestedResultObjects是一个储存结果的map,以缓存键为key,实体类(本例中为UserDO)为value,若能以cacheKey取到值,则说明本条记录可合并。
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, CacheKey combinedKey, String columnPrefix, Object partialObject) throws SQLException {
final String resultMapId = resultMap.getId();
Object rowValue = partialObject;
// rowValue不等于null时,说明此条记录可合并
if (rowValue != null) {
final MetaObject metaObject = configuration.newMetaObject(rowValue);
putAncestor(rowValue, resultMapId);
applyNestedResultMappings(rsw, resultMap, metaObject, columnPrefix, combinedKey, false);
ancestorObjects.remove(resultMapId);
} else {
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
// 创建result接收对象,本例中是UserDO对象
rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);
if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final MetaObject metaObject = configuration.newMetaObject(rowValue);
boolean foundValues = this.useConstructorMappings;
// 是否将查询出来的字段全部映射 默认false
if (shouldApplyAutomaticMappings(resultMap, true)) {
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;
}
// 设置需要映射的属性值,不管有嵌套ResultMap的
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;
// 存放第一条数据
putAncestor(rowValue, resultMapId);
// 处理有嵌套的resultMapping
foundValues = applyNestedResultMappings(rsw, resultMap, metaObject, columnPrefix, combinedKey, true) || foundValues;
ancestorObjects.remove(resultMapId);
foundValues = lazyLoader.size() > 0 || foundValues;
rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;
}
// 将最终结果放入到nestedResultObjects中
if (combinedKey != CacheKey.NULL_CACHE_KEY) {
nestedResultObjects.put(combinedKey, rowValue);
}
}
return rowValue;
}
getRowValue方法主要是将ResultSet解析为实体类对象,applyPropertyMappings填充<id><result>标签的实体属性值
private boolean applyNestedResultMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String parentPrefix, CacheKey parentRowKey, boolean newObject) {
boolean foundValues = false;
for (ResultMapping resultMapping : resultMap.getPropertyResultMappings()) {
// 嵌套id
final String nestedResultMapId = resultMapping.getNestedResultMapId();
// resultMapping有嵌套的map才继续 <association> <collection>
if (nestedResultMapId != null && resultMapping.getResultSet() == null) {
try {
final String columnPrefix = getColumnPrefix(parentPrefix, resultMapping);
// 获取嵌套(经过一次鉴权)的ResultMap
final ResultMap nestedResultMap = getNestedResultMap(rsw.getResultSet(), nestedResultMapId, columnPrefix);
if (resultMapping.getColumnPrefix() == null) {
// try to fill circular reference only when columnPrefix
// is not specified for the nested result map (issue #215)
Object ancestorObject = ancestorObjects.get(nestedResultMapId);
if (ancestorObject != null) {
if (newObject) {
linkObjects(metaObject, resultMapping, ancestorObject); // issue #385
}
continue;
}
}
// 构建嵌套map的key
final CacheKey rowKey = createRowKey(nestedResultMap, rsw, columnPrefix);
// 合并cacheKey
final CacheKey combinedKey = combineKeys(rowKey, parentRowKey);
// 尝试获取之前是否已经创建过
Object rowValue = nestedResultObjects.get(combinedKey);
boolean knownValue = rowValue != null;
// 实例化集合属性 list复制为空列表
instantiateCollectionPropertyIfAppropriate(resultMapping, metaObject); // mandatory
// 存在指定的非空列存在空值则返回false
if (anyNotNullColumnHasValue(resultMapping, columnPrefix, rsw)) {
rowValue = getRowValue(rsw, nestedResultMap, combinedKey, columnPrefix, rowValue);
if (rowValue != null && !knownValue) {
// 合并记录,设置对象-association或将对象添加到集合属性中-collection
linkObjects(metaObject, resultMapping, rowValue);
foundValues = true;
}
}
} catch (SQLException e) {
throw new ExecutorException("Error getting nested result map values for '" + resultMapping.getProperty() + "'. Cause: " + e, e);
}
}
}
return foundValues;
}
处理嵌套的结果映射,其实就是<collection><association>标签。同时调用getRowValue方法根据<collection>指定的resultMap获取实体对象(这里是PermitDO对象),然后调用linkObjects方法将permitDO对象调用add方法添加到permitDOList中
private void linkObjects(MetaObject metaObject, ResultMapping resultMapping, Object rowValue) {
final Object collectionProperty = instantiateCollectionPropertyIfAppropriate(resultMapping, metaObject);
// 属性是集合进行添加 <collection>
if (collectionProperty != null) {
final MetaObject targetMetaObject = configuration.newMetaObject(collectionProperty);
targetMetaObject.add(rowValue);
} else {
// 否则是对象 直接进行setter设置 <association>
metaObject.setValue(resultMapping.getProperty(), rowValue);
}
}
最后就把能合并的记录都合并在一起了,不同的权限映射到permitDOList这个集合中了
1.3 <collection>和<association>的相同的和不同点
从上面的代码看来,关于<collection>和<association>标签都属于嵌套结果集了,处理逻辑也是基本相同的没啥区分,换句话来说,把上面的<collection>替换成<association>标签其实也能得到相同的结果,关键还是pojo类中javaType的属性,若属性为List则会创建空的list并将嵌套结果映射添加到list中(即使是一对一的那么list中就只有一条记录),若属性为普通对象则直接进行setter设置。
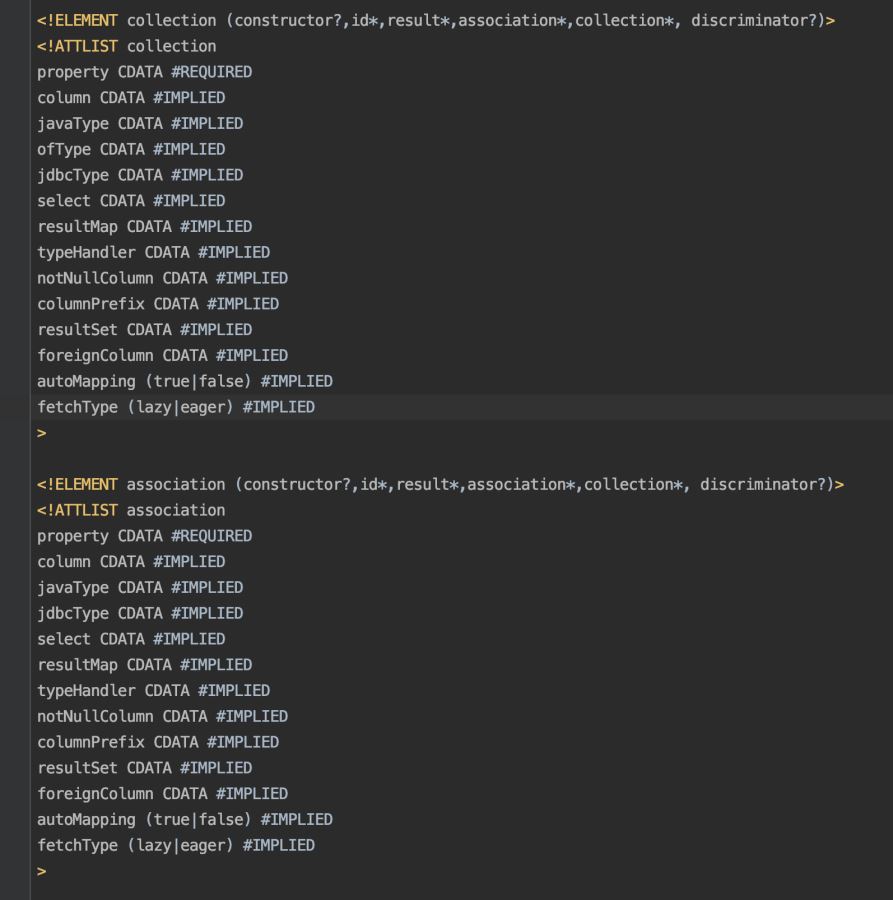
从上面的图中我们可以看到<collection>和<association>标签属性基本相同,<collection>比<association>多了一个ofType属性,这个ofType属性其实就是collection集合中单个元素的javaType属性,<collection>的javaType属性是继承了Collection接口的list或set等java集合属性。
另外在使用习惯上因为我们能确认表和表之间的关系是一对一还是一对多的,能够确认pojo类中的属性javaType是使用list还是普通对象,所以一般情况下一对一使用<association>标签,一对多使用<collection>标签,语义上更清晰更好理解。
最后
如果说的有问题欢迎提出指正讨论,代码提交在gitee上,感兴趣的同学可以下载看看
到此这篇关于mybatis collection解析以及和association的区别的文章就介绍到这了,更多相关mybatis collection内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Mybatis中collection和association的使用区别详解
最近一直把collection和association弄混,所以为了增强自己的记忆,就撸一个关系出来算是总结罢了 1. 关联-association 2. 集合-collection 比如同时有User.java和Card.java两个类 User.java如下: public class User{ private Card card_one; private List<Card> card_many; } 在映射card_one属性时用association标签, 映射card_many时
-
mybatis利用association或collection传递多参数子查询
有时候我们在查询数据库时,需要以查询结果为查询条件进行关联查询. 在mybatis 中通过 association 标签(一对一查询,collection 一对多 查询) 实现延迟加载子查询 <resultMap id="xxxMap" type="xxxx.bean.xxx" extends="zzzzMap"> <association property="destName" javaType="
-
详解mybatis中association和collection的column传入多个参数问题
项目中在使用association和collection实现一对一和一对多关系时需要对关系中结果集进行筛选,如果使用懒加载模式,即联合使用select标签时,主sql和关系映射里的sql是分开的,查询参数传递成为问题. mybatis文档: property description column 数据库的列名或者列标签别名.与传递给resultSet.getString(columnName)的参数名称相同.注意: 在处理组合键时,您可以使用column="{prop1=col1,prop2=c
-
Mybatis之association和collection用法
目录 association和collection用法 1.单个关联查询association 2.多个关联查询 collection 3.鉴别器discriminator association和collection关联查询用法 一对多 collection 一对一 & 多对一 association和collection用法 1.单个关联查询association 1.1实体之间的关联表示 package com.worldly.config.entity; import java.io.S
-
mybatis collection和association的区别解析
目录 1.collection标签 1.1 相关代码和运行结果 1.2 collection部分源码解析 1.3 <collection>和<association>的相同的和不同点 最后 1.collection标签 说到mybatis的collection标签,我们肯定不陌生,可以通过它解决一对多的映射问题,举个例子一个用户对应多个系统权限,通过对用户表和权限表的关联查询我们可以得到好多条记录,但是用户信息这部分在多条记录中是重复的,只有权限不同,我们需要把这多条权限记录映射到
-
浅谈mybatis中的#和$的区别 以及防止sql注入的方法
mybatis中的#和$的区别 1. #将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号.如:order by #user_id#,如果传入的值是111,那么解析成sql时的值为order by "111", 如果传入的值是id,则解析成的sql为order by "id". 2. $将传入的数据直接显示生成在sql中.如:order by $user_id$,如果传入的值是111,那么解析成sql时的值为order by user_id, 如果传入的
-
浅谈mybatis中的#和$的区别
1. #将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号.如:order by #user_id#,如果传入的值是111,那么解析成sql时的值为order by "111", 如果传入的值是id,则解析成的sql为order by "id". 2. $将传入的数据直接显示生成在sql中.如:order by $user_id$,如果传入的值是111,那么解析成sql时的值为order by user_id, 如果传入的值是id,则解析成的sql为ord
-
Mybatis中的动态SQL语句解析
这篇文章主要介绍了Mybatis中的动态SQL语句解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Mybatis中配置SQL有两种方式,一种是利用xml 方式进行配置,一种是利用注解进行配置. Mybatis使用注解配置SQL,但是由于配置功能受限,而且对于复杂的SQL而言可读性很差,所以很少使用. Mybatis常用xml配置的方式,使用xml的几个简单的元素,便能完成动态SQL的功能,大量的判断都可以在mybaties的映射xml里面配
-
Java Mybatis中的 ${ } 和 #{ }的区别使用详解
好了,真正做开发也差不多一年了.一直都是看别人的博客,自己懒得写,而且也不会写博客,今天就开始慢慢的练习一下写博客吧.前段时间刚好在公司遇到这样的问题. 一.举例说明 select * from user where name = "dato"; select * from user where name = #{name}; select * from user where name = '${name}'; 一般情况下,我们都不会注意到这里面有什么不一样的地方.因为这些sql都可以
-
MyBatis中#{}和${}有哪些区别
目录 前言 #{} 和 ${} 的区别 #{} 和 ${} 的实例:假设传入参数为 1 实例步骤一 实例步骤二 实例步骤三 #{} 和 ${} 的大括号中的值 #{} 和 ${} 在使用中的技巧和建议 总结 前言 在MyBatis 的映射配置文件中,动态传递参数有两种方式: 1.#{} 占位符 2.${} 拼接符 #{} 和 ${} 的区别 区别1 #{} 为参数占位符 ?,即sql 预编译 ${} 为字符串替换,即 sql 拼接 区别2. #{}:动态解析 -> 预编译 -> 执行 ${}:
-
mybatis collection 多条件查询的实现方法
mybatis collection 多条件查询的实现方法 前言: 业务需要通过mybatis 查询返回嵌套集合,嫌多次查询太麻烦,用自带的高级查询解决问题,下边是代码,已测试通过. 说下自己的理解,就是一个主查询结果集里面嵌套了子查询的结果集,可以是多个子查询,每个子查询的条件从主查询结果集中获取,返回值各自定义.collection 标签的property是主查询里面集合的名字,如果有多个就再写个collection,column是子查询参数,单参数直接写主查询结合返回结果,例如直接写上us
-
浅谈Java中Collection和Collections的区别
1.java.util.Collection 是一个集合接口.它提供了对集合对象进行基本操作的通用接口方法.Collection接口在Java 类库中有很多具体的实现.Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式. Collection ├List │├LinkedList │├ArrayList │└Vector │ └Stack └Set 2.java.util.Collections 是一个包装类.它包含有各种有关集合操作的静态多态方法.此类不能实例化,就像一
-
iOS开发中#import、#include和@class的区别解析
1. 一般来说,导入objective c的头文件时用#import,包含c/c++头文件时用#include. 2. #import 确定一个文件只能被导入一次,这使你在递归包含中不会出现问题.<标记> 所以,#import比起#include的好处就是不会引起交叉编译. #import && #class: 1. import会包含这个类的所有信息,包括实体变量和方法(.h文件中),而@class只是告诉编译器,其后面声明的名称是类的名称,至于这些类是如何定义的,后面会再告