R语言关于非线性最小二乘的知识点实例
当模拟真实世界数据用于回归分析时,我们观察到,很少情况下,模型的方程是给出线性图的线性方程。大多数时候,真实世界数据模型的方程涉及更高程度的数学函数,如3的指数或sin函数。在这种情况下,模型的图给出了曲线而不是线。线性和非线性回归的目的是调整模型参数的值,以找到最接近您的数据的线或曲线。在找到这些值时,我们将能够以良好的精确度估计响应变量。
在最小二乘回归中,我们建立了一个回归模型,其中来自回归曲线的不同点的垂直距离的平方和被最小化。我们通常从定义的模型开始,并假设系数的一些值。然后我们应用R语言的nls()函数获得更准确的值以及置信区间。
语法
在R语言中创建非线性最小二乘测试的基本语法是
nls(formula, data, start)
以下是所使用的参数的描述
- formula是包括变量和参数的非线性模型公式。
- data是用于计算公式中变量的数据框。
- start是起始估计的命名列表或命名数字向量。
例
我们将考虑一个假设其系数的初始值的非线性模型。 接下来,我们将看到这些假设值的置信区间是什么,以便我们可以判断这些值在模型中有多好。
所以让我们考虑下面的方程为这个目的
a = b1*x^2+b2
让我们假设初始系数为1和3,并将这些值拟合到nls()函数中。
xvalues <- c(1.6,2.1,2,2.23,3.71,3.25,3.4,3.86,1.19,2.21) yvalues <- c(5.19,7.43,6.94,8.11,18.75,14.88,16.06,19.12,3.21,7.58) # Give the chart file a name. png(file = "nls.png") # Plot these values. plot(xvalues,yvalues) # Take the assumed values and fit into the model. model <- nls(yvalues ~ b1*xvalues^2+b2,start = list(b1 = 1,b2 = 3)) # Plot the chart with new data by fitting it to a prediction from 100 data points. new.data <- data.frame(xvalues = seq(min(xvalues),max(xvalues),len = 100)) lines(new.data$xvalues,predict(model,newdata = new.data)) # Save the file. dev.off() # Get the sum of the squared residuals. print(sum(resid(model)^2)) # Get the confidence intervals on the chosen values of the coefficients. print(confint(model))
当我们执行上面的代码,它产生以下结果
[1] 1.081935
Waiting for profiling to be done...
2.5% 97.5%
b1 1.137708 1.253135
b2 1.497364 2.496484
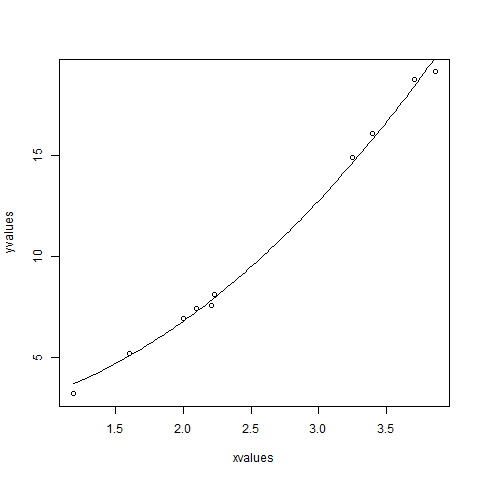
我们可以得出结论,b1的值更接近1,而b2的值更接近2而不是3。
以上就是R语言关于非线性最小二乘的知识点实例的详细内容,更多关于R语言非线性最小二乘的资料请关注我们其它相关文章!
相关推荐
-

R语言关于非线性最小二乘的知识点实例
当模拟真实世界数据用于回归分析时,我们观察到,很少情况下,模型的方程是给出线性图的线性方程.大多数时候,真实世界数据模型的方程涉及更高程度的数学函数,如3的指数或sin函数.在这种情况下,模型的图给出了曲线而不是线.线性和非线性回归的目的是调整模型参数的值,以找到最接近您的数据的线或曲线.在找到这些值时,我们将能够以良好的精确度估计响应变量. 在最小二乘回归中,我们建立了一个回归模型,其中来自回归曲线的不同点的垂直距离的平方和被最小化.我们通常从定义的模型开始,并假设系数的一些值.然后我们应用R
-
R语言中字符串的拼接操作实例讲解
在R语言中 paste 是一个很有用的字符串处理函数,可以连接不同类型的变量及常量. 函数paste的一般使用格式为: paste(..., sep = " ", collapse = NULL) 其 中-表示一个或多个R可以被转化为字符型的对象:参数sep表示分隔符,默认为空格:参数collapse可选,如果不指定值,那么函数paste的返回值是自变量之间通过sep指定的分隔符连接后得到的一个字符型向量:如果为其指定了特定的值,那么自变量连接后的字符型向量会再被连接成一个字符串,之间
-
R语言绘制饼状图代码实例
R编程语言有许多库来创建图表和图表. 饼图是将值表示为具有不同颜色的圆的切片. 切片被标记,并且对应于每个片的数字也在图表中表示. 在R语言中,饼图是使用pie()函数创建的,它使用正数作为向量输入. 附加参数用于控制标签,颜色,标题等. 语法 使用R语言创建饼图的基本语法是 pie(x, labels, radius, main, col, clockwise) 以下是所使用的参数的描述 x是包含饼图中使用的数值的向量. labels用于给出切片的描述. radius表示饼图圆的半径(值-1和
-
R语言对数据库进行操作的实例详解
数据是关系数据库系统以规范化格式存储. 因此,要进行统计计算,我们将需要非常先进和复杂的Sql查询. 但R语言可以轻松地连接到许多关系数据库,如MySql,Oracle,Sql服务器等,并从它们获取记录作为数据框. 一旦数据在R语言环境中可用,它就变成正常的R语言数据集,并且可以使用所有强大的包和函数来操作或分析. 在本教程中,我们将使用MySql作为连接到R语言的参考数据库. RMySQL包 R语言有一个名为"RMySQL"的内置包,它提供与MySql数据库之间的本地连接. 您可以使
-
R语言多元Logistic逻辑回归应用实例
可以使用逐步过程确定多元逻辑回归.此函数选择模型以最小化AIC. 如何进行多元逻辑回归 可以使用阶梯函数通过逐步过程确定多元逻辑回归.此函数选择模型以最小化AIC. 通常建议不要盲目地遵循逐步程序,而是要使用拟合统计(AIC,AICc,BIC)比较模型,或者根据生物学或科学上合理的可用变量建立模型. 多元相关是研究潜在自变量之间关系的一种工具.例如,如果两个独立变量彼此相关,可能在最终模型中都不需要这两个变量,但可能有理由选择一个变量而不是另一个变量. 多元相关 创建数值变量的数据框 Data.
-
R语言列筛选的方法select实例详解
目录 前言 1. 数据描述 2. 使用R语言默认的方法:列选择 3. tidyverse的rename函数 4. tidyverse的select函数 5. select函数注意事项 5.1 绝对引用函数 5.2 放到环境变量中 6. 提取h开头的列 7. 提取因子和数字的列 总结 前言 我们知道,R语言学习,80%的时间都是在清洗数据,而选择合适的数据进行分析和处理也至关重要,如何选择合适的列进行分析,你知道几种方法? 如何优雅高效的选择合适的列,让我们一起来看一下吧. 1. 数据描述 数据来
-
R语言向量知识点及实例讲解
有常见的六种基本的向量类型 创建向量 设定recursive = T,c函数可以从其他数据结构中递归形成向量 > v <- c(.295, .300, .250, .287, list(.102, .200, .303), recursive = T) > v [1] 0.295 0.300 0.250 0.287 0.102 0.200 0.303 > typeof(v) [1] "double" > v <- c(.295, .300, .250
-
R语言属性知识点总结及实例
属性(attribute):R中对象具备的特性 特性描述了所代表的内容以及R解释该对象的方式 很多时候两个对象之间的唯一差别在于它们的属性不同 常见的属性 属性 描述 class 对象的类 comment 对象的注释,一般用于描述对象的含义 dim 对象的维度 dimnames 与对象的每个维度相关的名字 names 返回对象的名字属性.返回结果取决于对象的类型.对于数据框对象会返回数据框的列名;对于数组会返回数组中被命名元素的名字 row,names 对象的行名(dimnames相关) tsp
-
R语言字符串知识点总结及实例分析
在R语言中的单引号或双引号对中写入的任何值都被视为字符串. R语言存储的每个字符串都在双引号内,即使是使用单引号创建的依旧如此. 在字符串构造中应用的规则 在字符串的开头和结尾的引号应该是两个双引号或两个单引号.它们不能被混合. 双引号可以插入到以单引号开头和结尾的字符串中. 单引号可以插入以双引号开头和结尾的字符串. 双引号不能插入以双引号开头和结尾的字符串. 单引号不能插入以单引号开头和结尾的字符串. 有效字符串的示例 以下示例阐明了在 R 语言中创建字符串的规则. a <- 'Start
-
R语言矩阵知识点总结及实例分析
矩阵是其中元素以二维矩形布局布置的R对象. 它们包含相同原子类型的元素. 虽然我们可以创建一个只包含字符或只包含逻辑值的矩阵,但它们没有太多用处. 我们使用包含数字元素的矩阵用于数学计算. 使用matrix()函数创建一个矩阵. 语法 在R语言中创建矩阵的基本语法是 matrix(data, nrow, ncol, byrow, dimnames) 以下是所使用的参数的说明 数据是成为矩阵的数据元素的输入向量. nrow是要创建的行数. ncol是要创建的列数. byrow是一个逻辑线索. 如果