Redis高并发情况下并发扣减库存项目实战
目录
- 第一种方案:纯MySQL扣减实现
- MySQL架构升级
- 第二种方案:缓存实现扣减
- 第三种方案:数据库+缓存 顺序写的性能更好
- 顺序写的架构
- 扣减流程
相信大家从网上学习项目大部分人第一个项目都是电商,生活中时时刻刻也会用到电商APP,例如淘宝,京东等。做技术的人都知道,电商的业务逻辑简单,但是大部分电商都会涉及到高并发高可用,对并发和对数据的处理要求是很高的。这里我今天就讲一下高并发情况下是如何扣减库存的?
我们对扣减库存所需要关注的技术点如下:
- 当前剩余的数量大于等于当前需要扣减的数量,不允许超卖
- 对于同一个数据的数量存在用户并发扣减,需要保证并发的一致性
- 需要保证可用性和性能,性能至少是秒级
- 一次的扣减包含多个目标数量
- 当次扣减有多个数量时,其中一个扣减不成功即不成功,需要回滚
- 必须有扣减才能有归还
- 返还的数量必须要加回,不能丢失
- 一次扣减可以有多次返还
- 返还需要保证幂等性
第一种方案:纯MySQL扣减实现
顾名思义,就是扣减业务完全依赖MySQL等数据库来完成。而不依赖一些其他的中间件或者缓存。纯数据库实现的好处就是逻辑简单,开发以及部署成本低。(适用于中小型电商)。
纯数据库的实现之所以能够满足扣减业务的各项功能要求,主要依赖两点:
- 基于数据库的乐观锁方式保证并发扣减的强一致性
- 基于数据库的事务实现批量扣减失败进行回滚
基于上述方案,它包含一个扣减服务和一个数量数据库

如果数据量单库压力很大,也可以做主从和分库分表,服务可以做集群等。

一次完整的流程就是先进行数据校验,在其中做一些参数格式校验,这里做接口开发的时候,要保持一个原则就是不信任原则,一切数据都不要相信,都需要做校验判断。其次,还可以进行库存扣减的前置校验。比如当前库存中的库存只有8个,而用户要购买10个,此时的数据校验中即可前置拦截,减少对于数据库的写操作。纯读不会加锁,性能较高,可以采用此种方式提升并发量。
update xxx set leavedAmount=leavedAmount-currentAmount where skuid='xxx' and leavedAmount>=currentAmount
此SQL采用了类似乐观锁的方式实现了原子性。在where后面判断剩余数量大于等于需要的数量,才能成功,否则失败。
扣减完成之后,需要记录流水数据。每一次扣减的时候,都需要外部用户传入一个uuid作为流水编号,此编号是全局唯一的。用户在扣减时传入唯一的编号有两个作用:
- 当用户归还数量时,需要带回此编码,用来标识此次返还属于历史上的哪次扣减。
- 进行幂等性控制。当用户调用扣减接口出现超时时,因为用户不知道是否成功,用户可以采用此编号进行重试或反查。在重试时,使用此编号进行标识防重
当用户只购买某个商品一个的时候,如果校验时剩余库存有8个,此时校验通过。但在后续的实际扣减时,因为其他用户也在并发的扣减,可能会出现幻读,此时用户实际去扣减时不足一个,导致失败。这种场景会导致多一次数据库查询,降低整体的扣减性能。这时候可以对MySQL架构进行升级
MySQL架构升级
多一次查询,就会增加数据库的压力,同时对整体性能也有一定的影响。此外,对外提供的查询库存数量的接口也会对数据库产生压力,同时读的请求要远大于写。
根据业务场景分析,读库存的请求一般是顾客浏览商品时产生,而调用扣减库存的请求基本上是用户购买时才触发。用户购买请求的业务价值比读请求会更大,因此对于写需要重点保障。针对上述的问题,可以对MySQL整体架构进行升级

整体的升级策略采用读写分离的方式,另外主从复制直接使用MySQL等数据库已有的功能,改动上非常小,只要在扣减服务里配置两个数据源。当客户查询剩余库存,扣减服务中的前置校验时,读取从数据库即可。而真正的数据扣减还是使用主数据库。
读写分离之后,根据二八原则,80% 的均为读流量,主库的压力降低了 80%。但采用了读写分离也会导致读取的数据不准确的问题,不过库存数量本身就在实时变化,短暂的差异业务上是可以容忍的,最终的实际扣减会保证数据的准确性。
在上面基础上,还可以升级,增加缓存

纯数据库的方案虽然可以避免超卖和少卖的情况,但是并发量实在很低,性能不是很乐观。所以这里再进行升级
第二种方案:缓存实现扣减
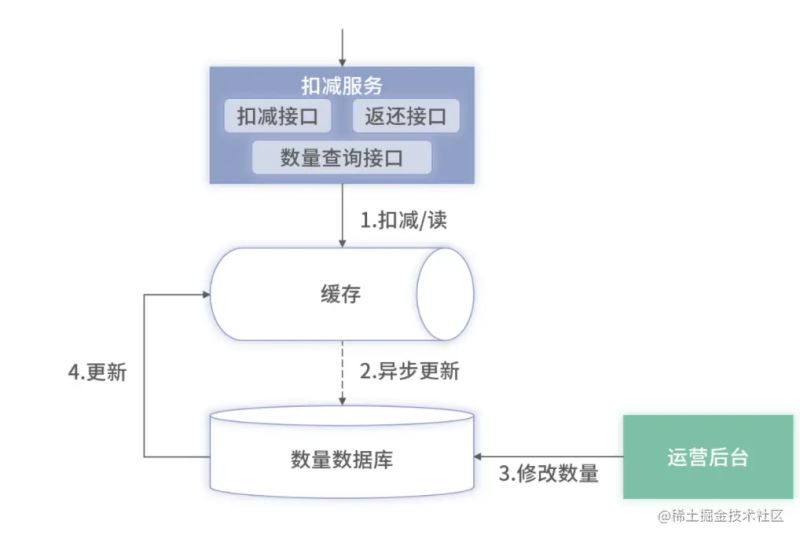
这和前面的扣减库存其实是一样的。但是此时扣减服务依赖的是Redis而不是数据库了。
这里针对Redis的hash结构不支持多个key的批量操作问题,我们可以采用Redis+lua脚本来实现批量扣减单线程请求。
升级成纯Redis实现扣减也会有问题
- Redis挂了,如果还没有执行到扣减Redis里面库存的操作挂了,只需要返回给客户端失败即可。如果已经执行到Redis扣减库存之后挂了。那这时候就需要有一个对账程序。通过对比Redis与数据库中的数据是否一致,并结合扣减服务的日志。当发现数据不一致同时日志记录扣减失败时,可以将数据库比Redis多的库存数据在Redis进行加回。
- Redis扣减完成,异步刷新数据库失败了。此时Redis里面的数据是准的,数据库的库存是多的。在结合扣减服务的日志确定是Redis扣减成功到但异步记录数据失败后,可以将数据库比Redis多的库存数据在数据库中进行扣减。
虽然使用纯Redis方案可以提高并发量,但是因为Redis不具备事务特性,极端情况下会存在Redis的数据无法回滚,导致出现少卖的情况。也可能发生异步写库失败,导致多扣的数据再也无法找回的情况。
第三种方案:数据库+缓存 顺序写的性能更好
在向磁盘进行数据操作时,向文件末尾不断追加写入的性能要远大于随机修改的性能。因为对于传统的机械硬盘来说,每一次的随机更新都需要机械键盘的磁头在硬盘的盘面上进行寻址,再去更新目标数据,这种方式十分消耗性能。而向文件末尾追加写入,每一次的写入只需要磁头一次寻址,将磁头定位到文件末尾即可,后续的顺序写入不断追加即可。
对于固态硬盘来说,虽然避免了磁头移动,但依然存在一定的寻址过程。此外,对文件内容的随机更新和数据库的表更新比较类似,都存在加锁带来的性能消耗。
数据库同样是插入要比更新的性能好。对于数据库的更新,为了保证对同一条数据并发更新的一致性,会在更新时增加锁,但加锁是十分消耗性能的。此外,对于没有索引的更新条件,要想找到需要更新的那条数据,需要遍历整张表,时间复杂度为 O(N)。而插入只在末尾进行追加,性能非常好。
顺序写的架构
通过上面的理论就可以得出一个兼具性能和高可靠的扣减架构
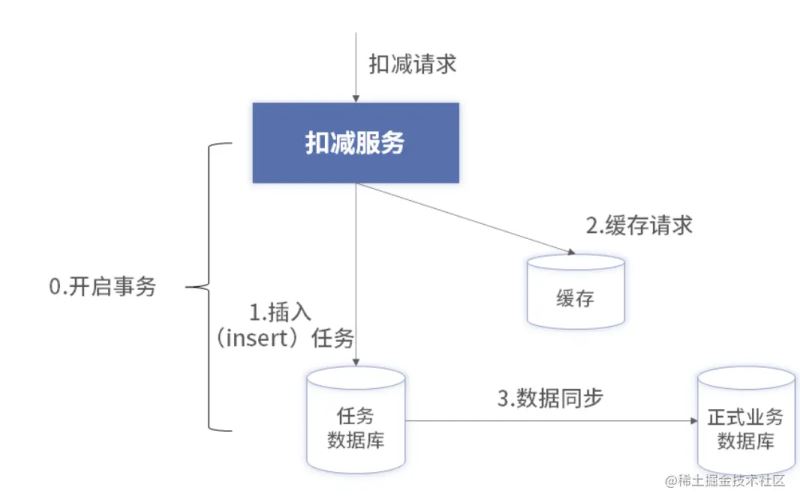
上述的架构和纯缓存的架构区别在于,写入数据库不是异步写入,而是在扣减的时候同步写入。同步写入数据库使用的是insert操作,就是顺序写,而不是update做数据库数量的修改,所以,性能会更好。
insert 的数据库称为任务库,它只存储每次扣减的原始数据,而不做真实扣减(即不进行 update)。它的表结构大致如下:
create table task{
id bigint not null comment "任务顺序编号",
task_id bigint not null
}
任务表里存储的内容格式可以为 JSON、XML 等结构化的数据。以 JSON 为例,数据内容大致可以如下:
{
"扣减号":uuid,
"skuid1":"数量",
"skuid2":"数量",
"xxxx":"xxxx"
}
这里我们肯定是还有一个记录业务数据的库,这里存储的是真正的扣减名企和SKU的汇总数据。对于另一个库里面的数据,只需要通过这个表进行异步同步就好了。
扣减流程

这里和纯缓存的区别在于增加了事务开启与回滚的步骤,以及同步的数据库写入流程
任务库里存储的是纯文本的 JSON 数据,无法被直接使用。需要将其中的数据转储至实际的业务库里。业务库里会存储两类数据,一类是每次扣减的流水数据,它与任务表里的数据区别在于它是结构化,而不是 JSON 文本的大字段内容。另外一类是汇总数据,即每一个 SKU 当前总共有多少量,当前还剩余多少量(即从任务库同步时需要进行扣减的),表结构大致如下:
create table 流水表{
id bigint not null,
uuid bigint not null comment '扣减编号',
sku_id bigint not null comment '商品编号',
num int not null comment '当次扣减的数量'
}comment '扣减流水表'
商品的实时数据汇总表,结构如下:
create table 汇总表{
id bitint not null,
sku_id unsigned bigint not null comment '商品编号',
total_num unsigned int not null comment '总数量',
leaved_num unsigned int not null comment '当前剩余的商品数量'
}comment '记录表'
在整体的流程上,还是复用了上一讲纯缓存的架构流程。当新加入一个商品,或者对已有商品进行补货时,对应的新增商品数量都会通过 Binlog 同步至缓存里。在扣减时,依然以缓存中的数量为准
到此这篇关于Redis高并发情况下并发扣减库存项目实战的文章就介绍到这了,更多相关Redis 并发扣减库存内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
如何使用Redis实现电商系统的库存扣减
目录 解决方案 分析 基于数据库单库存 基于数据库多库存 基于redis 基于redis实现扣减库存的具体实现 在日常开发中有很多地方都有类似扣减库存的操作,比如电商系统中的商品库存,抽奖系统中的奖品库存等. 解决方案 使用mysql数据库,使用一个字段来存储库存,每次扣减库存去更新这个字段.还是使用数据库,但是将库存分层多份存到多条记录里面,扣减库存的时候路由一下,这样子增大了并发量,但是还是避免不了大量的去访问数据库来更新库存.将库存放到redis使用redis的incrby特性来扣减库存.
-

Redis高并发情况下并发扣减库存项目实战
目录 第一种方案:纯MySQL扣减实现 MySQL架构升级 第二种方案:缓存实现扣减 第三种方案:数据库+缓存 顺序写的性能更好 顺序写的架构 扣减流程 相信大家从网上学习项目大部分人第一个项目都是电商,生活中时时刻刻也会用到电商APP,例如淘宝,京东等.做技术的人都知道,电商的业务逻辑简单,但是大部分电商都会涉及到高并发高可用,对并发和对数据的处理要求是很高的.这里我今天就讲一下高并发情况下是如何扣减库存的? 我们对扣减库存所需要关注的技术点如下: 当前剩余的数量大于等于当前需要扣减的数量,不
-
J2ee 高并发情况下监听器实例详解
J2ee 高并发情况下监听器实例详解 引言:在高并发下限制最大并发次数,在web.xml中用过滤器设置参数(最大并发数),并设置其他相关参数.详细见代码. 第一步:配置web.xml配置,不懂的地方解释一下:参数50通过参数名maxConcurrent用在filter的实现类中获取,filter-class就是写的实现类, url-pattern就是限制并发时间的url,结束! <filter> <filter-name>ConcurrentCountFilter</filt
-
java高并发情况下高效的随机数生成器
前言 在代码中生成随机数,是一个非常常用的功能,并且JDK已经提供了一个现成的Random类来实现它,并且Random类是线程安全的. 下面是Random.next()生成一个随机整数的实现: protected int next(int bits) { long oldseed, nextseed; AtomicLong seed = this.seed; do { oldseed = seed.get(); nextseed = (oldseed * multiplier + addend)
-
java并发高的情况下用ThreadLocalRandom来生成随机数
目录 一:简述 二:Random的性能差在哪里 三:ThreadLocalRandom的简单使用 四:为什么ThreadLocalRandom能在保证线程安全的情况下还能有不错的性能 一:简述 如果我们想要生成一个随机数,通常会使用Random类.但是在并发情况下Random生成随机数的性能并不是很理想,今天给大家介绍一下JUC包中的用于生成随机数的类--ThreadLocalRandom.(本文基于JDK1.8) 二:Random的性能差在哪里 Random随机数生成是和种子seed有关,而为
-
PHP通过加锁实现并发情况下抢码功能
需求:抢码功能 要求: 1.特定时间段才开放抢码: 2.每个时间段放开的码是有限的: 3.每个码不允许重复: 实现: 1.在不考虑并发的情况下实现: function get_code($len){ $CHAR_ARR = array('1','2','3','4','5','6','7','8','9','A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','X','Y','Z','W','S','R','T')
-
Yii+MYSQL锁表防止并发情况下重复数据的方法
本文实例讲述了Yii+MYSQL锁表防止并发情况下重复数据的方法.分享给大家供大家参考,具体如下: lock table 读锁定 如果一个线程获得在一个表上的read锁,那么该线程和所有其他线程只能从表中读数据,不能进行任何写操作. lock tables user read;//读锁定表 unlock tables;//解锁 lock tables user read local;//本地读锁定表,其他线程的insert未被阻塞,update操作被阻塞 lock table 写锁定 如果一个线
-
数据库高并发情况下重复值写入的避免 字段组合约束
10线程同时操作,频繁出现插入同样数据的问题.虽然在插入数据的时候使用了: insert inti tablename(fields....) select @t1,@t2,@t3 from tablename where not exists (select id from tablename where t1=@t1,t2=@t2,t3=@t3) 当时还是在高并发的情况下无效.此语句也包含在存储过程中.(之前也尝试线判断有无记录再看是否写入,无效). 因此,对于此类情况还是需要从数据库的根本
-
Redis高并发场景下秒杀超卖解决方案(秒杀场景)
目录 1 什么是秒杀 2 为什么要防止超卖 3 单体架构常规秒杀 3.1 常规减库存代码 3.2 模拟高并发 3.3 超卖现象 3.4 分析原因 4 简单实现悲观乐观锁解决单体架构超卖 4.1 悲观锁 4.2 乐观锁 4.3 redis锁setnx 4.4 使用Redision 5 分布式锁的解决方案 6 采用缓存队列防止超卖 1 什么是秒杀 秒杀最直观的定义:在高并发场景下而下单某一个商品,这个过程就叫秒杀 [秒杀场景] 火车票抢票 双十一限购商品 热度高的明星演唱会门票 … 2 为什么要防止
-
Redis高并发防止秒杀超卖实战源码解决方案
目录 1:解决思路 2:添加 redis 常量 3:添加 redis 配置类 4:修改业务层 1:秒杀业务逻辑层 2:添加需要抢购的代金券 3:抢购代金券 5:postman 测试 6:压力测试 8:配置Lua 9:修改业务层 1:抢购代金券 10:压力测试 1:解决思路 将活动写入 redis 中,通过 redis 自减指令扣除库存. 2:添加 redis 常量 commons/constant/RedisKeyConstant.java seckill_vouchers("seckill_v