这一次搞懂Spring自定义标签以及注解解析原理说明
前言
在上一篇文章中分析了Spring是如何解析默认标签的,并封装为BeanDefinition注册到缓存中,这一篇就来看看对于像context这种自定义标签是如何解析的。同时我们常用的注解如:@Service、@Component、@Controller标注的类也是需要在xml中配置<context:component-scan>才能自动注入到IOC容器中,所以本篇也会重点分析注解解析原理。
正文
自定义标签解析原理
在上一篇分析默认标签解析时看到过这个类DefaultBeanDefinitionDocumentReader的方法parseBeanDefinitions:
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
//默认标签解析
parseDefaultElement(ele, delegate);
}
else {
//自定义标签解析
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
现在我们就来看看parseCustomElement这个方法,但在点进去之前不妨想想自定义标签解析应该怎么做。
public BeanDefinition parseCustomElement(Element ele, @Nullable BeanDefinition containingBd) {
String namespaceUri = getNamespaceURI(ele);
if (namespaceUri == null) {
return null;
}
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
}
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
可以看到和默认标签解析是一样的,只不过由decorate方法改为了parse方法,但具体是如何解析的呢?这里我就以component-scan标签的解析为例,看看注解是如何解析为BeanDefinition对象的。
注解解析原理
进入到parse方法中,首先会进入NamespaceHandlerSupport类中:
public BeanDefinition parse(Element element, ParserContext parserContext) {
BeanDefinitionParser parser = findParserForElement(element, parserContext);
return (parser != null ? parser.parse(element, parserContext) : null);
}
首先通过findParserForElement方法去找到对应的解析器,然后委托给解析器ComponentScanBeanDefinitionParser解析。在往下看之前,我们先想一想,如果是我们自己要去实现这个注解解析过程会怎么做。是不是应该首先通过配置的basePackage属性,去扫描该路径下所有的class文件,然后判断class文件是否符合条件,即是否标注了@Service、@Component、@Controller等注解,如果有,则封装为BeanDefinition对象并注册到容器中去?
下面就来验证我们的猜想:
public BeanDefinition parse(Element element, ParserContext parserContext) {
String basePackage = element.getAttribute(BASE_PACKAGE_ATTRIBUTE);
basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage);
String[] basePackages = StringUtils.tokenizeToStringArray(basePackage,
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
// Actually scan for bean definitions and register them.
// 创造ClassPathBeanDefinitionScanner对象,用来扫描basePackage包下符合条件(默认是@Component标注的类)的类,
// 并创建BeanDefinition类注册到缓存中
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element);
Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages);
registerComponents(parserContext.getReaderContext(), beanDefinitions, element);
return null;
}
可以看到流程和我们猜想的基本一致,首先创建了一个扫描器ClassPathBeanDefinitionScanner对象,然后通过这个扫描器去扫描classpath下的文件并注册,最后调用了registerComponents方法,这个方法的作用稍后来讲,我们先来看看扫描器是如何创建的:
protected ClassPathBeanDefinitionScanner configureScanner(ParserContext parserContext, Element element) {
boolean useDefaultFilters = true;
if (element.hasAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE)) {
useDefaultFilters = Boolean.valueOf(element.getAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE));
}
// Delegate bean definition registration to scanner class.
ClassPathBeanDefinitionScanner scanner = createScanner(parserContext.getReaderContext(), useDefaultFilters);
scanner.setBeanDefinitionDefaults(parserContext.getDelegate().getBeanDefinitionDefaults());
scanner.setAutowireCandidatePatterns(parserContext.getDelegate().getAutowireCandidatePatterns());
if (element.hasAttribute(RESOURCE_PATTERN_ATTRIBUTE)) {
scanner.setResourcePattern(element.getAttribute(RESOURCE_PATTERN_ATTRIBUTE));
}
...
parseTypeFilters(element, scanner, parserContext);
return scanner;
}
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, @Nullable ResourceLoader resourceLoader) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
this.registry = registry;
if (useDefaultFilters) {
registerDefaultFilters();
}
setEnvironment(environment);
setResourceLoader(resourceLoader);
}
protected void registerDefaultFilters() {
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));
logger.trace("JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.
}
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));
logger.trace("JSR-330 'javax.inject.Named' annotation found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
protected void parseTypeFilters(Element element, ClassPathBeanDefinitionScanner scanner, ParserContext parserContext) {
// Parse exclude and include filter elements.
ClassLoader classLoader = scanner.getResourceLoader().getClassLoader();
// 将component-scan的子标签include-filter和exclude-filter添加到scanner中
NodeList nodeList = element.getChildNodes();
for (int i = 0; i < nodeList.getLength(); i++) {
Node node = nodeList.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
String localName = parserContext.getDelegate().getLocalName(node);
try {
if (INCLUDE_FILTER_ELEMENT.equals(localName)) {
TypeFilter typeFilter = createTypeFilter((Element) node, classLoader, parserContext);
scanner.addIncludeFilter(typeFilter);
}
else if (EXCLUDE_FILTER_ELEMENT.equals(localName)) {
TypeFilter typeFilter = createTypeFilter((Element) node, classLoader, parserContext);
scanner.addExcludeFilter(typeFilter);
}
}
catch (ClassNotFoundException ex) {
parserContext.getReaderContext().warning(
"Ignoring non-present type filter class: " + ex, parserContext.extractSource(element));
}
catch (Exception ex) {
parserContext.getReaderContext().error(
ex.getMessage(), parserContext.extractSource(element), ex.getCause());
}
}
}
}
上面不重要的方法我已经删掉了,首先获取use-default-filters属性,传入到ClassPathBeanDefinitionScanner构造器中判断是否使用默认的过滤器,如果是就调用registerDefaultFilters方法将@Component注解过滤器添加到includeFilters属性中;
创建后紧接着调用了parseTypeFilters方法去解析include-filter和exclude-filter子标签,并分别添加到includeFilters和excludeFilters标签中(关于这两个标签的作用这里不再赘述),所以这一步就是创建包含过滤器的class扫描器,接着就可以调用scan方法完成扫描注册了(如果我们要自定义注解是不是也可以这样实现呢?)。
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
// 这里就是实际扫描符合条件的类并封装为ScannedGenericBeanDefinition对象
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 接着在每个单独解析未解析的信息并注册到缓存中
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
// 解析@Lazy、@Primary、@DependsOn等注解
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
// 主要看这,扫描所有符合条件的class文件并封装为ScannedGenericBeanDefinition
return scanCandidateComponents(basePackage);
}
}
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 获取class文件并加载为Resource
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
// 获取SimpleMetadataReader对象,该对象持有AnnotationMetadataReadingVisitor对象
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
if (isCandidateComponent(metadataReader)) {
// 将AnnotationMetadataReadingVisitor对象设置到ScannedGenericBeanDefinition中
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setResource(resource);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
}
}
}
}
}
return candidates;
}
这个方法实现很复杂,首先是扫描找到符合条件的类并封装成BeanDefinition对象,接着去设置该对象是否可作为根据类型自动装配的标记,然后解析@Lazy、@Primary、@DependsOn等注解,最后才将其注册到容器中。
需要注意的是和xml解析不同的是在扫描过程中,创建的是ScannedGenericBeanDefinition对象:
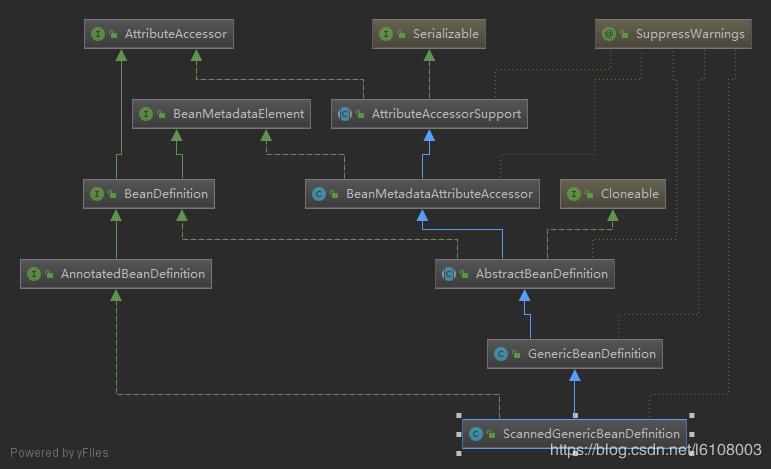
该类是GenericBeanDefinition对象的子类,并持有了AnnotationMetadata对象的引用,进入下面这行代码:
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
我们可以发现AnnotationMetadata实际上是AnnotationMetadataReadingVisitor对象:
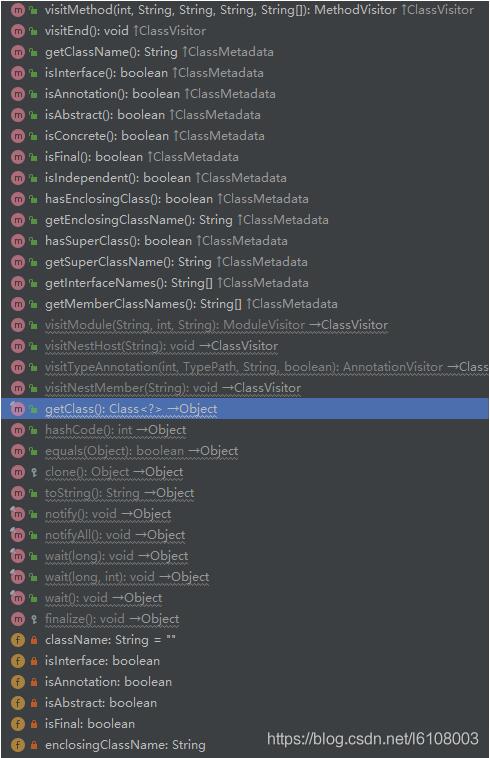
从上图中我们可以看到该对象具有很多属性,基本上包含了我们类的所有信息,所以后面在对象实例化时需要的信息都是来自于这里。
以上就是Spring注解的扫描解析过程,现在还剩一个方法registerComponents,它是做什么的呢?
protected void registerComponents(
XmlReaderContext readerContext, Set<BeanDefinitionHolder> beanDefinitions, Element element) {
Object source = readerContext.extractSource(element);
CompositeComponentDefinition compositeDef = new CompositeComponentDefinition(element.getTagName(), source);
for (BeanDefinitionHolder beanDefHolder : beanDefinitions) {
compositeDef.addNestedComponent(new BeanComponentDefinition(beanDefHolder));
}
// Register annotation config processors, if necessary.
boolean annotationConfig = true;
if (element.hasAttribute(ANNOTATION_CONFIG_ATTRIBUTE)) {
annotationConfig = Boolean.valueOf(element.getAttribute(ANNOTATION_CONFIG_ATTRIBUTE));
}
if (annotationConfig) {
Set<BeanDefinitionHolder> processorDefinitions =
AnnotationConfigUtils.registerAnnotationConfigProcessors(readerContext.getRegistry(), source);
for (BeanDefinitionHolder processorDefinition : processorDefinitions) {
compositeDef.addNestedComponent(new BeanComponentDefinition(processorDefinition));
}
}
readerContext.fireComponentRegistered(compositeDef);
}
在该标签中有一个属性annotation-config,该属性的作用是,当配置为true时,才会去注册一个个BeanPostProcessor类,这个类非常重要,比如:ConfigurationClassPostProcessor支持@Configuration注解,AutowiredAnnotationBeanPostProcessor支持@Autowired注解,CommonAnnotationBeanPostProcessor支持@Resource、@PostConstruct、@PreDestroy等注解。这里只是简单提提,详细分析留待后篇。
至此,自定义标签和注解的解析原理就分析完了,下面就看看如何定义我们自己的标签。
定义我们自己的标签
通过上面的分析,我相信对于定义自己的标签流程应该大致清楚了,如下:
首先设计一个标签并定义其NamespaceHandler类,让它继承NamespaceHandlerSupport类;
其次定义标签对应的解析器,并实现parse方法,在parse方法中解析我们的标签,将其封装为BeanDefinition对象并注册到容器中;
最后在classpath/META-INF文件夹下创建一个spring.handler文件,并定义标签的命名空间和NamespaceHandler的映射关系。
这就是我们从之前的源码分析中理解到的,但这里实际还忽略了一个步骤,这也是之前分析时没讲到的,你能想到是什么么?我们设计的标签需不需要一个规范?不可能让其他人随便写,否则怎么识别呢?因此需要一个规范约束。同样,在Spring的META-INF文件夹下都会有一个spring.schemas文件,该文件和spring.handler文件一样,定义了约束文件和约束命名空间的映射关系,下面就是context的spring.schemas文件部分内容:
http\://www.springframework.org/schema/context/spring-context-2.5.xsd=org/springframework/context/config/spring-context.xsd
......
http\://www.springframework.org/schema/cache/spring-cache.xsd=org/springframework/cache/config/spring-cache.xsd
但是这个文件是在什么时候被读取的呢?是不是应该在解析xml之前就把规范设置好?实际上就是在调用XmlBeanDefinitionReader的doLoadDocument方法时读取的该文件:
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,
getValidationModeForResource(resource), isNamespaceAware());
}
protected EntityResolver getEntityResolver() {
if (this.entityResolver == null) {
// Determine default EntityResolver to use.
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader != null) {
this.entityResolver = new ResourceEntityResolver(resourceLoader);
}
else {
this.entityResolver = new DelegatingEntityResolver(getBeanClassLoader());
}
}
return this.entityResolver;
}
public DelegatingEntityResolver(@Nullable ClassLoader classLoader) {
this.dtdResolver = new BeansDtdResolver();
this.schemaResolver = new PluggableSchemaResolver(classLoader);
}
public static final String DEFAULT_SCHEMA_MAPPINGS_LOCATION = "META-INF/spring.schemas";
public PluggableSchemaResolver(@Nullable ClassLoader classLoader) {
this.classLoader = classLoader;
this.schemaMappingsLocation = DEFAULT_SCHEMA_MAPPINGS_LOCATION;
}
总结
通过两篇文章完成了对Spring XML标签和注解解析的源码分析,整体流程多看几遍还是不复杂,关键是要学习到其中的设计思想:装饰、模板、委托、SPI;
掌握其中我们可以使用到的扩展点:xml解析前后扩展、自定义标签扩展、自定义注解扩展(本篇没有讲解,可以思考一下);深刻理解BeanDefinition对象,可以看到所有标签和注解类都会封装为该对象,因此接下来对象实例化都是根据该对象进行的。
以上这篇这一次搞懂Spring自定义标签以及注解解析原理说明就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
这一次搞懂Spring事务注解的解析方式
前言 事务我们都知道是什么,而Spring事务就是在数据库之上利用AOP提供声明式事务和编程式事务帮助我们简化开发,解耦业务逻辑和系统逻辑.但是Spring事务原理是怎样?事务在方法间是如何传播的?为什么有时候事务会失效?接下来几篇文章将重点分析Spring事务源码,让我们彻底搞懂Spring事务的原理. 正文 XML标签的解析 <tx:annotation-driven transaction-manager="transactionManager"/> 配置过事务的应该
-
这一次搞懂Spring事务是如何传播的
前言 上一篇分析了事务注解的解析过程,本质上是将事务封装为切面加入到AOP的执行链中,因此会调用到MethodInceptor的实现类的invoke方法,而事务切面的Interceptor就是TransactionInterceptor,所以本篇直接从该类开始. 正文 事务切面的调用过程 public Object invoke(MethodInvocation invocation) throws Throwable { // Work out the target class: may be
-
解决SpringBoot2多线程无法注入的问题
1.情况描述 使用springboot2多线程,线程类无法实现自动注入需要的bean,解决思路,通过工具类获取需要的bean 如下 package com.ps.uzkefu.apps.ctilink.handler; import com.baomidou.mybatisplus.mapper.EntityWrapper; import com.ps.uzkefu.apps.callcenter.entity.CallRecord; import com.ps.uzkefu.apps.call
-
这一次搞懂Spring代理创建及AOP链式调用过程操作
前言 AOP,也就是面向切面编程,它可以将公共的代码抽离出来,动态的织入到目标类.目标方法中,大大提高我们编程的效率,也使程序变得更加优雅.如事务.操作日志等都可以使用AOP实现.这种织入可以是在运行期动态生成代理对象实现,也可以在编译期.类加载时期静态织入到代码中.而Spring正是通过第一种方法实现,且在代理类的生成上也有两种方式:JDK Proxy和CGLIB,默认当类实现了接口时使用前者,否则使用后者:另外Spring AOP只能实现对方法的增强. 正文 基本概念 AOP的术语很多,虽然
-
这一次搞懂Spring自定义标签以及注解解析原理说明
前言 在上一篇文章中分析了Spring是如何解析默认标签的,并封装为BeanDefinition注册到缓存中,这一篇就来看看对于像context这种自定义标签是如何解析的.同时我们常用的注解如:@Service.@Component.@Controller标注的类也是需要在xml中配置<context:component-scan>才能自动注入到IOC容器中,所以本篇也会重点分析注解解析原理. 正文 自定义标签解析原理 在上一篇分析默认标签解析时看到过这个类DefaultBeanDefinit
-
这一次搞懂Spring的XML解析原理说明
前言 Spring已经是我们Java Web开发必不可少的一个框架,其大大简化了我们的开发,提高了开发者的效率.同时,其源码对于开发者来说也是宝藏,从中我们可以学习到非常优秀的设计思想以及优雅的命名规范,但因其体系庞大.设计复杂对于刚开始阅读源码的人来说是非常困难的.所以在此之前首先你得下定决心,不管有多困难都得坚持下去:其次,最好先把设计模式掌握熟练:然后在开始阅读源码时一定要多画UML类图和时序图,多问自己为什么要这么设计?这样设计的好处是什么?还有没有更好的设计?当然,晕车是难免的,但还是
-

一文搞懂Spring中的注解与反射
目录 前言 一.内置(常用)注解 1.1@Overrode 1.2@RequestMapping 1.3@RequestBody 1.4@GetMapping 1.5@PathVariable 1.6@RequestParam 1.7@ComponentScan 1.8@Component 1.9@Service 1.10@Repository 二.元注解 @Target @Retention @Documented @Inherited 三.自定义注解 四.反射机制概述 4.1动态语言与静态语
-
一文搞懂Spring Bean中的作用域和生命周期
目录 一.Spring Bean 作用域 singleton(单例) prototype(原型) 小结 二.Spring Bean生命周期 如何关闭容器 生命周期回调 通过接口设置生命周期 通过xml设置生命周期 一.Spring Bean 作用域 常规的 Spring IoC 容器中Bean的作用域有两种:singleton(单例)和prototype(非单例) 注:基于Web的容器还有其他种作用域,在这就不赘述了. singleton(单例) singleton是Spring默认的作用域.当
-
一文搞懂Spring中的Bean作用域
目录 概述 Singleton prototype request session application 概述 scope用来声明容器中的对象所应该处的限定场景或者说该对象的存活时间,即容器在对象进入其 相应的scope之前,生成并装配这些对象,在该对象不再处于这些scope的限定之后,容器通常会销毁这些对象. Spring容器bean的作用域类型: singleton:Spring IoC 容器的单个对象实例作用域都默认为singleton prototype:针对声明为拥有prototyp
-
一文搞懂Spring中Bean的生命周期
目录 一.使用配置生命周期的方法 二.生命周期控制——接口控制(了解) 小结 生命周期:从创建到消亡的完整过程 bean声明周期:bean从创建到销毁的整体过程 bean声明周期控制:在bean创建后到销毁前做一些事情 一.使用配置生命周期的方法 在BookDaoImpl中实现类中创建相应的方法: //表示bean初始化对应的操作 public void init(){ System.out.println("init..."); } //表示bean销毁前对应的操作 public v
-
一文搞懂Spring循环依赖的原理
目录 简介 循环依赖实例 测试 简介 说明 本文用实例来介绍@Autowired解决循环依赖的原理.@Autowired是通过三级缓存来解决循环依赖的. 除了@Autoired,还有其他方案来解决循环依赖的,见:Spring循环依赖的解决方案详解 概述 @Autowired进行属性注入可以解决循环依赖.原理是:Spring控制了bean的生命周期,先实例化bean,后注入bean的属性.Spring中记录了正在创建中的bean(已经实例化但还没初始化完毕的bean),所以可以在注入属性时,从记录
-
一文带你搞懂Spring响应式编程
目录 1. 前言 1.1 常用函数式编程 1.2 Stream操作 2. Java响应式编程 带有中间处理器的响应式流 3. Reactor 3.1 Flux & Mono 3.2 Flux Mono创建与使用 4. WebFlux Spring WebFlux示例 基于注解的WebFlux 基于函数式编程的WebFlux Flux与Mono的响应式编程延迟示例 总结 哈喽,大家好,我是指北君. 相信响应式编程经常会在各种地方被提到.本篇就为大家从函数式编程一直到Spring WeFlux做一次