Python 实例进阶之预测房价走势
目录
- 项目描述
- 项目分析
- Show Time
- Step 1 导入数据
- Step 2 分析数据
- 基础统计运算
- 特征观察
- Step 3 数据划分
- Step 4 定义评价函数
- Step 5 模型调优
- 学习曲线
- 小结
该分享源于 Udacity 机器学习进阶中的一个mini作业项目,用于入门非常合适,刨除了繁琐的部分,保留了最关键、基本的步骤,能够对机器学习基本流程有一个最清晰的认识。欢迎收藏学习,喜欢点赞支持,文末提供技术交流群。
项目描述
利用马萨诸塞州波士顿郊区的房屋信息数据训练和测试一个模型,并对模型的性能和预测能力进行测试;
项目分析
数据集字段解释:
RM: 住宅平均房间数量;LSTAT: 区域中被认为是低收入阶层的比率;PTRATIO: 镇上学生与教师数量比例;MEDV: 房屋的中值价格(目标特征,即我们要预测的值);
其实现在回过头来看,前三个特征应该都是挖掘后的组合特征,比如RM,通常在原始数据中会分为多个特征:一楼房间、二楼房间、厨房、卧室个数、地下室房间等等,这里应该是为了教学简单化了;
MEDV为我们要预测的值,属于回归问题,另外数据集不大(不到500个数据点),小数据集上的回归问题,现在的我初步考虑会用SVM,稍后让我们看看当时的选择;
Show Time
Step 1 导入数据
注意点:
- 如果数据在多个csv中(比如很多销售项目中,销售数据和店铺数据是分开两个csv的,类似数据库的两张表),这里一般要连接起来;
- 训练数据和测试数据连接起来,这是为了后续的数据处理的一致,否则训练模型时会有问题(比如用训练数据训练的模型,预测测试数据时报错维度不一致);
- 观察下数据量,数据量对于后续选择算法、可视化方法等有比较大的影响,所以一般会看一下;
- pandas内存优化,这一点项目中目前没有,但是我最近的项目有用到,简单说一下,通过对特征字段的数据类型向下转换(比如int64转为int8)降低对内存的使用,这里很重要,数据量大时很容易撑爆个人电脑的内存存储;
上代码:
# 载入波士顿房屋的数据集
data = pd.read_csv('housing.csv')
prices = data['MEDV']
features = data.drop('MEDV', axis = 1)
# 完成
print"Boston housing dataset has {} data points with {} variables each.".format(*data.shape)
Step 2 分析数据
加载数据后,不要直接就急匆匆的上各种处理手段,加各种模型,先慢一点,对数据进行一个初步的了解,了解其各个特征的统计值、分布情况、与目标特征的关系,最好进行可视化,这样会看到很多意料之外的东西;
基础统计运算
统计运算用于了解某个特征的整体取值情况,它的最大最小值,平均值中位数,百分位数等等,这些都是最简单的对一个字段进行了解的手段;
上代码:
#目标:计算价值的最小值 minimum_price = np.min(prices)# prices.min() #目标:计算价值的最大值 maximum_price = np.max(prices)# prices.max() #目标:计算价值的平均值 mean_price = np.mean(prices)# prices.mean() #目标:计算价值的中值 median_price = np.median(prices)# prices.median() #目标:计算价值的标准差 std_price = np.std(prices)# prices.std()
特征观察
这里主要考虑各个特征与目标之间的关系,比如是正相关还是负相关,通常都是通过对业务的了解而来的,这里就延伸出一个点,机器学习项目通常来说,对业务越了解,越容易得到好的效果,因为所谓的特征工程其实就是理解业务、深挖业务的过程;
比如这个问题中的三个特征:
- RM:房间个数明显应该是与房价正相关的;
- LSTAT:低收入比例一定程度上表示着这个社区的级别,因此应该是负相关;
- PTRATIO:学生/教师比例越高,说明教育资源越紧缺,也应该是负相关;
上述这三个点,同样可以通过可视化的方式来验证,事实上也应该去验证而不是只靠主观猜想,有些情况下,主观感觉与客观事实是完全相反的,这里要注意;
Step 3 数据划分
为了验证模型的好坏,通常的做法是进行cv,即交叉验证,基本思路是将数据平均划分N块,取其中N-1块训练,并对另外1块做预测,并比对预测结果与实际结果,这个过程反复N次直到每一块都作为验证数据使用过;
上代码:
# 提示:导入train_test_split from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(features, prices, test_size=0.2, random_state=RANDOM_STATE) print X_train.shape print X_test.shape print y_train.shape print y_test.shape
Step 4 定义评价函数
这里主要是根据问题来定义,比如分类问题用的最多的是准确率(精确率、召回率也有使用,具体看业务场景中更重视什么),回归问题用RMSE(均方误差)等等,实际项目中根据业务特点经常会有需要去自定义评价函数的时候,这里就比较灵活;
Step 5 模型调优
通过GridSearch对模型参数进行网格组合搜索最优,注意这里要考虑数据量以及组合后的可能个数,避免运行时间过长哈。
上代码:
from sklearn.model_selection importKFold,GridSearchCV
from sklearn.tree importDecisionTreeRegressor
from sklearn.metrics import make_scorer
def fit_model(X, y):
""" 基于输入数据 [X,y],利于网格搜索找到最优的决策树模型"""
cross_validator = KFold()
regressor = DecisionTreeRegressor()
params = {'max_depth':[1,2,3,4,5,6,7,8,9,10]}
scoring_fnc = make_scorer(performance_metric)
grid = GridSearchCV(estimator=regressor, param_grid=params, scoring=scoring_fnc, cv=cross_validator)
# 基于输入数据 [X,y],进行网格搜索
grid = grid.fit(X, y)
# 返回网格搜索后的最优模型
return grid.best_estimator_
可以看到当时项目中选择的是决策树模型,现在看,树模型在这种小数据集上其实是比较容易过拟合的,因此可以考虑用SVM代替,你也可以试试哈,我估计是SVM效果最好;
学习曲线
通过绘制分析学习曲线,可以对模型当前状态有一个基本了解,如下图:
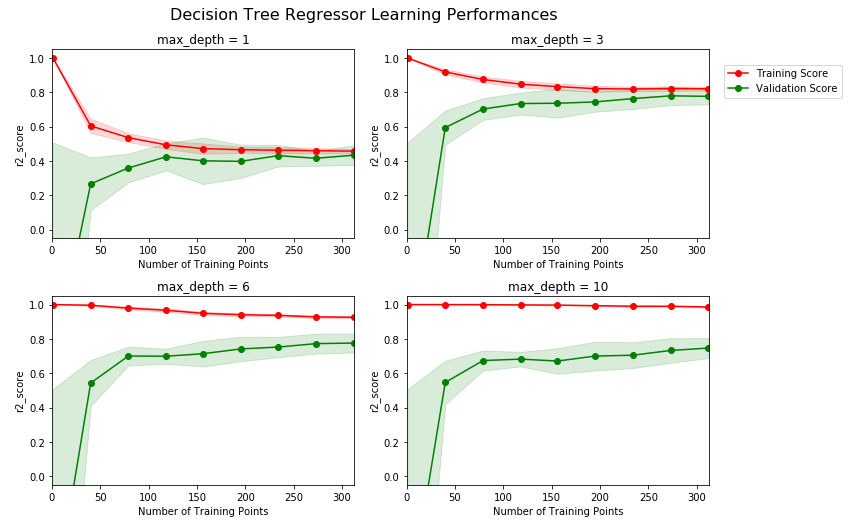
可以看到,超参数max_depth为1和3时,明显训练分数过低,这说明此时模型有欠拟合的情况,而当max_depth为6和10时,明显训练分数和验证分析差距过大,说明出现了过拟合,因此我们初步可以猜测,最佳参数在3和6之间,即4,5中的一个,其他参数一样可以通过学习曲线来进行可视化分析,判断是欠拟合还是过拟合,再分别进行针对处理;
小结
通过以上的几步,可以非常简单、清晰的看到一个机器学习项目的全流程,其实再复杂的流程也是这些简单步骤的一些扩展,而更难的往往是对业务的理解,没有足够的理解很难得到好的结果,体现出来就是特征工程部分做的好坏,这里就需要各位小伙伴们奋发图强了,路漫漫啊。
到此这篇关于Python 实例进阶之预测房价走势的文章就介绍到这了,更多相关Python 预测房价走势内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python预测分词的实现
目录 前言 加载模型 构建词网 维特比算法 实战 前言 在机器学习中,我们有了训练集的话,就开始预测.预测是指利用模型对句子进行推断的过程.在中文分词任务中也就是利用模型推断分词序列,同时也叫解码. 在HanLP库中,二元语法的解码由ViterbiSegment分词器提供.本篇将详细介绍ViterbiSegment的使用方式 加载模型 在前篇博文中,我们已经得到了训练的一元,二元语法模型.后续的处理肯定会基于这几个文件来处理.所以,我们首先要做的就是加载这些模型到程序中: if __name__
-
Python实现对照片中的人脸进行颜值预测
一.所需工具 **Python版本:**3.5.4(64bit) 二.相关模块 opencv_python模块 sklearn模块 numpy模块 dlib模块 一些Python自带的模块. 三.环境搭建 (1)安装相应版本的Python并添加到环境变量中: (2)pip安装相关模块中提到的模块. 例如: 若pip安装报错,请自行到: http://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载pip安装报错模块的whl文件,并使用: pip install whl
-
python数据分析之用sklearn预测糖尿病
一.数据集描述 本数据集内含十个属性列 Pergnancies: 怀孕次数 Glucose:血糖浓度 BloodPressure:舒张压(毫米汞柱) SkinThickness:肱三头肌皮肤褶皱厚度(毫米) Insulin:两个小时血清胰岛素(μU/毫升) BMI:身体质量指数,体重除以身高的平方 Diabets Pedigree Function: 疾病血统指数 是否和遗传相关,Height:身高(厘米) Age:年龄 Outcome:0表示不患病,1表示患病. 任务:建立机器学习模型以准确预
-
利用Python第三方库实现预测NBA比赛结果
主要思路 (1)数据选取 获取数据的链接为: https://www.basketball-reference.com/ 获取的数据内容为: 每支队伍平均每场比赛的表现统计: 每支队伍的对手平均每场比赛的表现统计: 综合统计数据: 2016-2017年NBA常规赛以及季后赛的每场比赛的比赛数据: 2017-2018年NBA的常规赛以及季后赛的比赛安排. (2)建模思路 主要利用数据内容的前四项来评估球队的战斗力. 利用数据内容的第五项也就是比赛安排来预测每场比赛的获胜队伍. 利用方式为: 数据内
-
python基于机器学习预测股票交易信号
引言 近年来,随着技术的发展,机器学习和深度学习在金融资产量化研究上的应用越来越广泛和深入.目前,大量数据科学家在Kaggle网站上发布了使用机器学习/深度学习模型对股票.期货.比特币等金融资产做预测和分析的文章.从金融投资的角度看,这些文章可能缺乏一定的理论基础支撑(或交易思维),大都是基于数据挖掘.但从量化的角度看,有很多值得我们学习参考的地方,尤其是Pyhton的深入应用.数据可视化和机器学习模型的评估与优化等.下面借鉴Kaggle上的一篇文章<Building an Asset Trad
-
Python实现新型冠状病毒传播模型及预测代码实例
1.传染及发病过程 一个健康人感染病毒后进入潜伏期(时间长度为Q天),潜伏期之后进入发病期(时间长度为D天),发病期之后该患者有三个可能去向,分别是自愈.接收隔离.死亡. 2.模型假设 潜伏期Q=7天,根据报道潜伏期为2~14天,取中间值:发病期D=10天,根据文献报告,WHO认定SARS发病期为10天,假设武汉肺炎与此相同:潜伏期的患者不具有将病毒传染给他人的能力:发病期的患者具有将病毒传染给他人的能力:患者在发病期之后不再具有将病毒传染他人的能力:假设处于发病期的患者平均每天密切接触1人,致
-
Python预测2020高考分数和录取情况
"迟到"了一个月的高考终于要来了. 正好我得到了一份山东新高考模拟考的成绩和山东考试院公布的一分一段表,以及过去三年的普通高考本科普通批首次志愿录取情况统计.2020年是山东新高考改革的元年,全新的录取模式以及选考科目要求都给考生带来了非常大的挑战. 我正好就本次山东模拟考的成绩进行深入数据分析,用python可视化带大家模拟一下2020高考分数和录取情况. (代码较长,故只展示部分,完整数据+源码下载见文末) 不同考生的成绩分布图 首先对山东新高考模拟考的成绩进行总体描述: fig
-
Python 实例进阶之预测房价走势
目录 项目描述 项目分析 Show Time Step 1 导入数据 Step 2 分析数据 基础统计运算 特征观察 Step 3 数据划分 Step 4 定义评价函数 Step 5 模型调优 学习曲线 小结 该分享源于 Udacity 机器学习进阶中的一个mini作业项目,用于入门非常合适,刨除了繁琐的部分,保留了最关键.基本的步骤,能够对机器学习基本流程有一个最清晰的认识.欢迎收藏学习,喜欢点赞支持,文末提供技术交流群. 项目描述 利用马萨诸塞州波士顿郊区的房屋信息数据训练和测试一个模型,并
-
Python实例一个类背后发生了什么
首先来看一个例子,正常情况下我们定义并且实例一个类如下 class Foo(object): def __init__(self): pass obj = Foo() # obj是通过Foo类实例化的对象 上述代码中,obj 是通过 Foo 类实例化的对象,其实,不仅 obj 是一个对象,Foo类本身也是一个对象,因为在Python中一切事物都是对象. print type(obj) # 输出: Foo 表示,obj 对象由Foo类创建 print type(Foo) # 输出:type表示,F
-
python:目标检测模型预测准确度计算方式(基于IoU)
训练完目标检测模型之后,需要评价其性能,在不同的阈值下的准确度是多少,有没有漏检,在这里基于IoU(Intersection over Union)来计算. 希望能提供一些思路,如果觉得有用欢迎赞我表扬我~ IoU的值可以理解为系统预测出来的框与原来图片中标记的框的重合程度.系统预测出来的框是利用目标检测模型对测试数据集进行识别得到的. 计算方法即检测结果DetectionResult与GroundTruth的交集比上它们的并集,如下图: 蓝色的框是:GroundTruth 黄色的框是:Dete
-
Python爬虫进阶之爬取某视频并下载的实现
这几天在家闲得无聊,意外的挖掘到了一个资源网站(你懂得),但是网速慢广告多下载不了种种原因让我突然萌生了爬虫的想法. 下面说说流程: 一.网站分析 首先进入网站,F12检查,本来以为这种低端网站很好爬取,是我太低估了web主.可以看到我刷新网页之后,出现了很多js文件,并且响应获取的代码与源代码不一样,这就不难猜到这个网站是动态加载页面. 目前我知道的动态网页爬取的方法只有这两种:1.从网页响应中找到JS脚本返回的JSON数据:2.使用Selenium对网页进行模拟访问.源代码问题好解决,重要的
-
Python基础进阶之海量表情包多线程爬虫功能的实现
一.前言 在我们日常聊天的过程中会使用大量的表情包,那么如何去获取表情包资源呢?今天老师带领大家使用python中的爬虫去一键下载海量表情包资源 二.知识点 requests网络库 bs4选择器 文件操作 多线程 三.所用到得库 import os import requests from bs4 import BeautifulSoup 四. 功能 # 多线程程序需要用到的一些包 # 队列 from queue import Queue from threading import Thread
-
Python爬虫进阶之Beautiful Soup库详解
一.Beautiful Soup库简介 BeautifulSoup4 是一个 HTML/XML 的解析器,主要的功能是解析和提取 HTML/XML 的数据.和 lxml 库一样. lxml 只会局部遍历,而 BeautifulSoup4 是基于 HTML DOM 的,会加载整个文档,解析 整个 DOM 树,因此内存开销比较大,性能比较低. BeautifulSoup4 用来解析 HTML 比较简单,API 使用非常人性化,支持 CSS 选择器,是 Python 标准库中的 HTML 解析器,也支
-
python实例小练习之Turtle绘制南方的雪花
导语 又到了裹紧被子,穿起秋裤的季节! 这些天,我们这边开始下雨了,温度瞬间降了10几度. 遭受了秋天第一场寒潮的"侵袭",我是真的冷,一大早穿上了长裙. 寒风呼啸,大雪飘飘,咳咳咳......说的严重了点儿,还没飘雪呢,思维有点儿远了! 唯一的愿望就是: 我们公司的冷空调能不能稍微收住一点儿,话说还有的同事穿着短衣短裤是怎么熬过来的, 咋没感觉冷呢?后面我还加了一件外套来着!后来想了想:估计是男孩子皮比较厚一点点.[开个玩笑.jpg] 哼唧唧,独冷冷不如众冷冷,木木子来帮你了~大家一
-
Python爬虫进阶Scrapy框架精文讲解
目录 一.前情提要 为什么要使用Scrapy 框架? 二.Scrapy框架的概念 三.Scrapy安装 四.Scrapy实战运用 这一串代码干了什么? 五.Scrapy的css选择器教学 按标签名选择 按 class 选择 按 id 选择 按层级关系选择 取元素中的文本 取元素的属性 一.前情提要 为什么要使用Scrapy 框架? 前两篇深造篇介绍了多线程这个概念和实战 多线程网页爬取 多线程爬取网页项目实战 经过之前的学习,我们基本掌握了分析页面.分析动态请求.抓取内容,也学会使用多线程来并发
-
据Python爬虫不靠谱预测可知今年双十一销售额将超过6000亿元
不知不觉,双十一到今年已经是13个年头,每年大家都在满心期待看着屏幕上的数字跳动,年年打破记录.而 2019 年的天猫双11的销售额却被一位微博网友提前7个月用数据拟合的方法预测出来了.他的预测值是2675.37或者2689.00亿元,而实际成交额是2684亿元.只差了5亿元,误差率只有千分之一. 但如果你用同样的方法去做预测2020年的时候,发现预测是3282亿,实际却到了 4982亿.原来2020改了规则,实际上统计的是11月1到11日的销量,理论上已经不能和历史数据合并预测,但咱们就为了图
-
Python实例解析图像形态学运算技术
1 图像形态学运算 在Python OpenCV图像处理之图像滤波特效详解中我们将图像滤波进行了以下分类: 邻域滤波 线性滤波 非线性滤波 频域滤波 低通滤波 高通滤波 在非线性滤波中,之前只介绍了中值滤波,事实上,还有一类非常常用的非线性滤波方法,称为图像形态学运算(Morphological operations). 图像形态学运算是一类基于图像形状运算的非线性滤波技术,其基本思想是利用一些特殊的结构元来测量或提取图像中相应的形状和特征,以便进一步进行图像分析和处理.这里结构元素就相当于我们