selenium+python配置chrome浏览器的选项的实现
1. 背景
在使用selenium浏览器渲染技术,爬取网站信息时,默认情况下就是一个普通的纯净的chrome浏览器,而我们平时在使用浏览器时,经常就添加一些插件,扩展,代理之类的应用。相对应的,当我们用chrome浏览器爬取网站时,可能需要对这个chrome做一些特殊的配置,以满足爬虫的行为。
常用的行为有:
- 禁止图片和视频的加载:提升网页加载速度。
- 添加代理:用于翻墙访问某些页面,或者应对IP访问频率限制的反爬技术。
- 使用移动头:访问移动端的站点,一般这种站点的反爬技术比较薄弱。
- 添加扩展:像正常使用浏览器一样的功能。
- 设置编码:应对中文站,防止乱码。
- 阻止JavaScript执行。
- ………
2. 环境
- python 3.6.1
- 系统:win7
- IDE:pycharm
- 安装过chrome浏览器
- 配置好chromedriver
- selenium 3.7.0
3. chromeOptions
chromeOptions 是一个配置 chrome 启动是属性的类。通过这个类,我们可以为chrome配置如下参数(这个部分可以通过selenium源码看到):
- 设置 chrome 二进制文件位置 (binary_location)
- 添加启动参数 (add_argument)
- 添加扩展应用 (add_extension, add_encoded_extension)
- 添加实验性质的设置参数 (add_experimental_option)
- 设置调试器地址 (debugger_address)
源代码:
# .\Lib\site-packages\selenium\webdriver\chrome\options.py
class Options(object):
def __init__(self):
# 设置 chrome 二进制文件位置
self._binary_location = ''
# 添加启动参数
self._arguments = []
# 添加扩展应用
self._extension_files = []
self._extensions = []
# 添加实验性质的设置参数
self._experimental_options = {}
# 设置调试器地址
self._debugger_address = None
使用案例:
# 设置默认编码为 utf-8,也就是中文
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('lang=zh_CN.UTF-8')
driver = webdriver.Chrome(chrome_options = options)
4. 常用配置官方网站参考:https://sites.google.com/a/chromium.org/chromedriver/capabilities
4.1. 设置编码格式
# 设置默认编码为 utf-8,也就是中文
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('lang=zh_CN.UTF-8')
driver = webdriver.Chrome(chrome_options = options)
4.2. 模拟移动设备
移动设备user-agent表格:http://www.fynas.com/ua
因为移动版网站的反爬虫的能力比较弱
# 通过设置user-agent,用来模拟移动设备
# 比如模拟 android QQ浏览器
options.add_argument('user-agent="MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"')
# 模拟iPhone 6
options.add_argument('user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1"')
4.3. 禁止图片加载
不加载图片的情况下,可以提升爬取速度。
# 禁止图片的加载
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
# 启动浏览器,并设置好wait
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.set_window_size(configure.windowHeight, configure.windowWidth) # 根据桌面分辨率来定,主要是为了抓到验证码的截屏
wait = WebDriverWait(browser, timeout = configure.timeoutMain)
4.4. 添加代理
为selenium爬虫添加代理,这个地方尤其需要注意的是,在选择代理时,尽量选择静态IP,才能提升爬取的稳定性。因为如果选择selenium来做爬虫,说明网站的反爬能力比较高(要不然直接上scrapy了),对网页之间的连贯性,cookies,用户状态等有较高的监测。如果使用动态匿名IP,每个IP的存活时间是很短的(1~3分钟)。
from selenium import webdriver
# 静态IP:102.23.1.105:2005
# 阿布云动态IP:http://D37EPSERV96VT4W2:CERU56DAEB345HU90@proxy.abuyun.com:9020
PROXY = "proxy_host:proxy:port"
options = webdriver.ChromeOptions()
desired_capabilities = options.to_capabilities()
desired_capabilities['proxy'] = {
"httpProxy": PROXY,
"ftpProxy": PROXY,
"sslProxy": PROXY,
"noProxy": None,
"proxyType": "MANUAL",
"class": "org.openqa.selenium.Proxy",
"autodetect": False
}
driver = webdriver.Chrome(desired_capabilities = desired_capabilities)
4.5. 浏览器选项设置
selenium一般打开的是不带扩展的纯净的浏览器,但是有时候我们想对浏览器进行一些设置,比如 设置flash选项的默认值为全局始终允许,清除cookies,清除缓存 之类。
想要实现这个目的,有一种思路,下面以chrome浏览器为例:
在selenium爬虫启动时,首先开一个窗口,在地址栏键入:chrome://settings/content 或 chrome://settings/privacy,然后由程序,像操作普通网页一样,进行设置,保存。
4.6.添加浏览器扩展应用
selenium一般打开的是不带扩展的纯净的浏览器,但是有时候我们爬取数据时需要借助一些插件,比如解析类xpath helper,翻译类,获取额外信息(销量)等。那我们怎么在启动chromedriver时,带上一些我们需要的插件呢?
下面以在chrome中加载Xpath Helper插件为例:
4.6.1. 下载相应的插件Xpath Helper下载地址:https://www.jb51.net/softs/673040.html
如下,是一个 以 crx 为后缀的文件:
 4.6.2.
4.6.2.
将插件路径填入代码中
# 添加xpath helper应用 from selenium import webdriver chrome_options = webdriver.ChromeOptions() # 设置好应用扩展 extension_path = 'D:/extension/XPath-Helper_v2.0.2.crx' chrome_options.add_extension(extension_path) # 启动浏览器,并设置好wait browser = webdriver.Chrome(chrome_options=chrome_options)
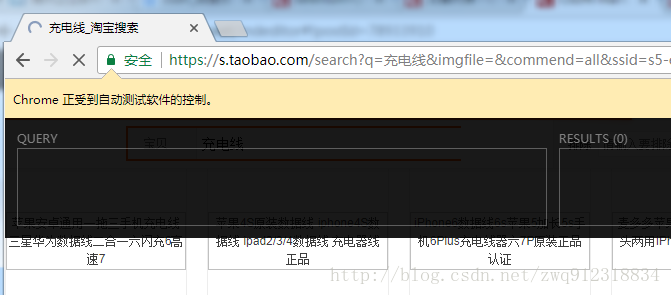
4.6.3. 结果展示
4.6.4. 注意事项
第一,为了提高爬取速度,尽可能的少加载插件。
第二,有一种方案会加载用户对chrome浏览器的所有配置信息,但是测试并无法使用,如下:
首先进入C:\Users(用户)\你的电脑名称\AppData\Local\Google\Chrome\User Data\Default\Extensions,点开Extensions,里面的文件夹就是安装过的扩展,(记得先把电脑隐藏文件夹显示出来,否则找不到) 但是名字是一堆我看不懂的无序的英文字母,我的办法是一个一个点开找到对应的插件版本号,版本号在chrome Extensions选项里找然后打包你需要的插件:打开chrome的设置,在里面点开扩展程序,选中开发者模式,你安装的插件的下面会出现一个ID,这个ID对应的就是你要打包的插件,然后打包扩展程序,找到对应的文件夹(或者你也可以把这个文件夹复制到电脑任意地方)下面的版本号的文件夹,也就是ID名文件夹内部的那个文件夹,然后点击打包扩展程序,就可以了,会相应的在版本号的同一级地方出现后缀名是crx和pem的文件,这个crx的文件就是我们需要的(不过按照这种方式,在我的本地目录是找不到这样的crx文件,需要单独下载…)。准备工作完成,看代码:
# 第一种方式
# chrome浏览器的扩展程序都在:C:\Users\Administrator\AppData\Local\Google\Chrome\User Data\Profile 2\Extensions\下
chrome_options.add_argument("user-data-dir=C:/Users/Administrator/AppData/Local/Google/Chrome/User Data")
# 加载所有Chrome配置, 用Chrome地址栏输入chrome://version/,查看自己的“个人资料路径”,然后在浏览器启动时,调用这个配置文件,代码如下:
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument('--user-data-dir=C:\Users\Administrator\AppData\Local\Google\Chrome\User Data') #设置成用户自己的数据目录
driver = webdriver.Chrome(chrome_options=option)
# 出现错误结果 第一,所有浏览器窗口,包括自己打开的都会被控制住。 第二,其他动作不起作用,而且会crash。 Traceback (most recent call last): File "E:/PyCharmCode/taobaoProductSelenium/taobaoSelenium.py", line 40, in <module> # 启动浏览器,并设置好wait File "E:\Miniconda\lib\site-packages\selenium\webdriver\chrome\webdriver.py", line 69, in __init__ desired_capabilities=desired_capabilities) File "E:\Miniconda\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 151, in __init__ self.start_session(desired_capabilities, browser_profile) File "E:\Miniconda\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 240, in start_session response = self.execute(Command.NEW_SESSION, parameters) File "E:\Miniconda\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 308, in execute self.error_handler.check_response(response) File "E:\Miniconda\lib\site-packages\selenium\webdriver\remote\errorhandler.py", line 194, in check_response raise exception_class(message, screen, stacktrace) selenium.common.exceptions.WebDriverException: Message: unknown error: Chrome failed to start: crashed (Driver info: chromedriver=2.32.498550 (9dec58e66c31bcc53a9ce3c7226f0c1c5810906a),platform=Windows NT 6.1.7601 SP1 x86_64)
4.7. 登录时关闭弹出的密码保存提示框
最近在使用chrome登录网站的时候总有密码保存提示框,并不是所有的都会有密码保存提示框,其实只需要设置启动chrome的相关参数就可以避免这种问题。
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
options = webdriver.ChromeOptions()
prefs = {}
# 设置这两个参数就可以避免密码提示框的弹出
prefs[“credentials_enable_service”] = False
prefs[“profile.password_manager_enabled”] = False
options.add_experimental_option(“prefs”, prefs)
browser = webdriver.Chrome(chrome_options=options)
browser.get('https://www.baidu.com/')
5. 其他参数
参考文章:https://www.jb51.net/article/182967.htm
5.1 chrome地址栏命令在Chrome的浏览器地址栏中输入以下命令,就会返回相应的结果。这些命令包括查看内存状态,浏览器状态,网络状态,DNS服务器状态,插件缓存等等。但是需要注意的是这些命令会不停的变动,所以不一定都是好用的。
about:version - 显示当前版本
about:memory - 显示本机浏览器内存使用状况
about:plugins - 显示已安装插件
about:histograms - 显示历史记录
about:dns - 显示DNS状态
about:cache - 显示缓存页面
about:gpu -是否有硬件加速
about:flags -开启一些插件 //使用后弹出这么些东西:“请小心,这些实验可能有风险”,不知会不会搞乱俺的配置啊!
chrome://extensions/ - 查看已经安装的扩展
5.2. chrome实用参数
其他的一些关于Chrome的实用参数及简要的中文说明,使用方法同上4.5.4,当然也可以在shell中使用。
–user-data-dir=”[PATH]” 指定用户文件夹User Data路径,可以把书签这样的用户数据保存在系统分区以外的分区。
–disk-cache-dir=”[PATH]“ 指定缓存Cache路径
–disk-cache-size= 指定Cache大小,单位Byte
–first run 重置到初始状态,第一次运行
–incognito 隐身模式启动
–disable-javascript 禁用Javascript
--omnibox-popup-count=“num” 将地址栏弹出的提示菜单数量改为num个。我都改为15个了。
--user-agent=“xxxxxxxx” 修改HTTP请求头部的Agent字符串,可以通过about:version页面查看修改效果
--disable-plugins 禁止加载所有插件,可以增加速度。可以通过about:plugins页面查看效果
--disable-javascript 禁用JavaScript,如果觉得速度慢在加上这个
--disable-java 禁用java
--start-maximized 启动就最大化
--no-sandbox 取消沙盒模式
--single-process 单进程运行
--process-per-tab 每个标签使用单独进程
--process-per-site 每个站点使用单独进程
--in-process-plugins 插件不启用单独进程
--disable-popup-blocking 禁用弹出拦截
--disable-plugins 禁用插件
--disable-images 禁用图像
--incognito 启动进入隐身模式
--enable-udd-profiles 启用账户切换菜单
--proxy-pac-url 使用pac代理 [via 1/2]
--lang=zh-CN 设置语言为简体中文
--disk-cache-dir 自定义缓存目录
--disk-cache-size 自定义缓存最大值(单位byte)
--media-cache-size 自定义多媒体缓存最大值(单位byte)
--bookmark-menu 在工具 栏增加一个书签按钮
--enable-sync 启用书签同步
–single-process 单进程运行Google Chrome
–start-maximized 启动Google Chrome就最大化
–disable-java 禁止Java
–no-sandbox 非沙盒模式运行
到此这篇关于selenium+python配置chrome浏览器的选项的实现的文章就介绍到这了,更多相关selenium python配置chrome内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

详解mac python+selenium+Chrome 简单案例
第一步:下载selenium pip install selenium 第二步:下载和你当前谷歌浏览器对应的驱动Chromedriver 下载地址:https://npm.taobao.org/mirrors/chromedriver 这是我谷歌对应的版本,点击选择下载对应的系统文件,下载完解压到你项目的目录里即可! 第三步:简单操作selenium from selenium import webdriver import time # 创建Chrome的驱动对象 driver = webdr
-
Python使用selenium + headless chrome获取网页内容的方法示例
使用python写爬虫时,优选selenium,由于PhantomJS因内部原因已经停止更新,最新版的selenium已经使用headless chrome替换掉了PhantomJS,所以建议将selenium更新到最新版,使用selenium + headless chrome 准备工作: 安装chrome.chrome driver.selenium 一.安装chrome 配置yum下载源,在目录/etc/yum.repos.d/下新建文件google-chrome.repo > cd /e
-
Selenium chrome配置代理Python版的方法
环境: windows 7 + Python 3.5.2 + Selenium 3.4.2 + Chrome Driver 2.29 + Chrome 58.0.3029.110 (64-bit) Selenium官方给的Firefox代理配置方式并不起效,也没看到合适的配置方式,对于Chrome Selenium官方没有告知如何配置,但以下两种方式是有效的: 1. 连接无用户名密码认证的代理 chromeOptions = webdriver.ChromeOptions() chromeOpt
-
下载与当前Chrome对应的chromedriver.exe(用于python+selenium)
一. 打开Chrome浏览器,输chrome://version/ 二.下载chromedriver.exe驱动 注意:上图可以看到安装的Chrome浏览器版本为79.0.3945.88 (正式版本) 下载地址1:http://npm.taobao.org/mirrors/chromedriver/ 下载地址2:http://chromedriver.storage.googleapis.com/index.html Firefox浏览器驱动下载地址:https://github.com/moz
-
python selenium 执行完毕关闭chromedriver进程示例
因为使用多次以后发现进程中出现了很多chromedriver的残留,造成卡顿,所以决定优化一下. 这个问题困扰了楼主很久,百度谷歌查来查去都只有java,后面根据java和selenium结合看找出了python如何执行完把chromedriver进程关闭 Python的话控制chromedriver的开启和关闭的包是Service from selenium.webdriver.chrome.service import Service 创建的时候需要把chromedriver.exe的位置写
-
python+selenium+Chrome options参数的使用
Chrome Options常用的行为一般有以下几种: 禁止图片和视频的加载:提升网页加载速度. 添加代理:用于翻墙访问某些页面,或者应对IP访问频率限制的反爬技术. 使用移动头:访问移动端的站点,一般这种站点的反爬技术比较薄弱. 添加扩展:像正常使用浏览器一样的功能. 设置编码:应对中文站,防止乱码. 阻止JavaScript执行 ... Chrome Options是一个配置chrome启动时属性的类,通过这个参数我们可以为Chrome添加如下参数: 设置 chrome 二进制文件位置 (b
-
详解pyinstaller selenium python3 chrome打包问题
今天打包selenium一个简单的请求,打完包本机运行exe没有问题,换台机器就闪退,非常蛋疼找了半天原因. 下面简述下,防止踩坑,如果闪退十有八九是浏览器版本跟浏览器插件对不上. 首先安装pyinstaller pip install pyinstaller 然后进入要打包的py文件目录 然后pyinstaller tomcat.py 这种打包方式有很多文件,不太美观 第二种打包方式:pyinstaller -F tomcat.py 下面就是重点,我之前忘记把浏览器插件复制到.exe文件目录所
-
Python3+Selenium+Chrome实现自动填写WPS表单
引言 本文通过python3.第三方python库Selenium和谷歌浏览器Chrome,完成WPS表单的自动填写. 开发环境配置 python3的安装:略,网上都有教程. Selenium的安装:在命令行输入pip3 install selenium并回车即可完成安装,如果不成功,查找网上教程. Chrome的安装:略,网上都有教程. 因为Selenium需要ChromeDriver来驱动Chrome,所以还需要下载驱动ChromeDriver.下面重点介绍一下Chrom
-
selenium+python配置chrome浏览器的选项的实现
1. 背景 在使用selenium浏览器渲染技术,爬取网站信息时,默认情况下就是一个普通的纯净的chrome浏览器,而我们平时在使用浏览器时,经常就添加一些插件,扩展,代理之类的应用.相对应的,当我们用chrome浏览器爬取网站时,可能需要对这个chrome做一些特殊的配置,以满足爬虫的行为. 常用的行为有: 禁止图片和视频的加载:提升网页加载速度. 添加代理:用于翻墙访问某些页面,或者应对IP访问频率限制的反爬技术. 使用移动头:访问移动端的站点,一般这种站点的反爬技术比较薄弱. 添加扩展:像
-
使用Python解析Chrome浏览器书签的示例
Chrome 浏览器的书签如果可以导出,并转换为我们需要的格式时,我们就可以编写各种插件来配合书签的使用. 答案显然是可以的,接下来我们以 Python 为例写一个遍历打印书签的例子 书签地址 先来说下获取书签的方法 Chrome 浏览器的书签存放位置在各个平台的区别 Mac ~/Library/Application Support/Google/Chrome/Default/Bookmarks Linux ~/.config/google-chrome/Default/Bookmarks W
-
如何使用Python提取Chrome浏览器保存的密码
由于Chrome会将大量浏览数据本地保存磁盘中,在本教程中,我们将编写 Python 代码来提取 Windows 计算机上 Chrome 中保存的密码. 首先,让我们安装所需的库: pip install pycryptodome pypiwin32 打开一个新的 Python 文件,并导入必要的模块: import os import json import base64 import sqlite3 import win32crypt from Crypto.Cipher import AE
-
python解析Chrome浏览器历史浏览记录和收藏夹数据
目录 前言 (一)查询chrome数据缓存地址 (二)提取收藏夹数据 1.文件路径 2.解析代码 (三)查看浏览历史数据 1.文件路径 2.解析代码 (四)完整代码&测试代码 总结 前言 常使用chrome浏览器作为自己的默认浏览器,也喜欢使用浏览器来收藏自己的喜欢的有用的链接,自己也做了一个记录笔记的小脚本,想扩展收录chrome浏览器收藏夹的内容,,下面,,使用python提取chrome浏览器的历史记录,以及收藏夹. (一)查询chrome数据缓存地址 1.打开 chrome浏览器,输入
-
python用selenium打开chrome浏览器保持登录方式
目录 导读 selenium操作浏览器 打开chrome浏览器 使用selenium打开网站 总结 导读 我们在使用selenium打开google浏览器的时候,默认打开的是一个新的浏览器窗口,而且里面不带有任何的浏览器缓存信息.当我们想要爬取某个网站信息或者做某些操作的时候就需要自己再去模拟登陆 selenium操作浏览器 这里我们就以CSDN为例,来展示如何让selenium在打开chrome浏览器的时候带上用户的登录信息 打开chrome浏览器 from selenium import w
-
python使用selenium打开chrome浏览器时带用户登录信息实现过程详解
导读 我们在使用selenium打开google浏览器的时候,默认打开的是一个新的浏览器窗口,而且里面不带有任何的浏览器缓存信息.当我们想要爬取某个网站信息或者做某些操作的时候就需要自己再去模拟登陆 selenium操作浏览器 这里我们就以CSDN为例,来展示如何让selenium在打开chrome浏览器的时候带上用户的登录信息 打开chrome浏览器 from selenium import webdriver from selenium.webdriver import ChromeOpti
-
Python使用chrome配置selenium操作详解
目录 1.下载chrome浏览器驱动程序 2.文件解压放置 3.配置环境变量 总结 1.下载chrome浏览器驱动程序 驱动程序网址http://chromedriver.storage.googleapis.com/index.html根据chrome对应的版本下载适合的驱动程序 查询chrome版本方法: 点击浏览器红圈处,点击帮助,关于chrome 下载对应版本的驱动程序: 2.文件解压放置 将下载后的文件解压到对应chrome的安装目录,也是就chrome浏览器对应的文件位置,通常为C:
-
Python使用Selenium模块实现模拟浏览器抓取淘宝商品美食信息功能示例
本文实例讲述了Python使用Selenium模块实现模拟浏览器抓取淘宝商品美食信息功能.分享给大家供大家参考,具体如下: import re from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected
-
Python Selenium参数配置方法解析
这篇文章主要介绍了Python Selenium参数配置方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 selenium.获取浏览器大小.设置浏览器位置.最大化浏览器 get_window_size() 获取浏览器大小 # 将窗口大小实例化 size_Dict = driver.get_window_size() # 打印浏览器的宽和高 print("当前浏览器的宽:", size_Dict['width']) print(&
-
selenium+python自动化测试之使用webdriver操作浏览器的方法
WebDriver简介 selenium从2.0开始集成了webdriver的API,提供了更简单,更简洁的编程接口.selenium webdriver的目标是提供一个设计良好的面向对象的API,提供了更好的支持进行web-app测试.从这篇博客开始,将学习使用如何使用python调用webdriver框架对浏览器进行一系列的操作 打开浏览器 在selenium+python自动化测试(一)–环境搭建中,运行了一个测试脚本,脚本内容如下: from selenium import webdri