Python中最好用的json库orjson用法详解
目录
- 1 简介
- 2 orjson常用方法
- 2.1 序列化
- 2.2 反序列化
- 2.3 丰富的option选项
- 2.4 针对dataclass、datetime添加自定义处理策略
- 总结
1 简介
大家好,我们在日常使用 Python 的过程中,经常会使用 json 格式存储一些数据,尤其是在 web 开发中。而 Python 原生的 json 库性能差、功能少,只能堪堪应对简单轻量的 json 数据存储转换需求。

而本文我要给大家介绍的第三方 json 库 orjson ,在公开的各项基准性能测试中,以数倍至数十倍的性能优势碾压 json 、 ujson 、 rapidjson 、 simplejson 等其他 Python 库,且具有诸多额外功能,下面我们就来领略其常用方法吧~
2 orjson常用方法
orjson 支持 3.7 到 3.10 所有版本64位的 Python ,本文演示对应的 orjson 的版本为 3.7.0 ,直接使用 pip install -U orjson 即可完成安装。下面我们来对 orjson 中的常用方法进行演示:
2.1 序列化
与原生 json 库类似,我们可以使用 orjson.dumps() 将 Python 对象序列化为 JSON 数据,注意,略有不同的是, orjson 序列化的结果并不是 str 型而是 bytes 型,在下面的例子中,我们对包含一千万个简单字典元素的列表进行序列化, orjson 与 json 库的耗时比较如下:
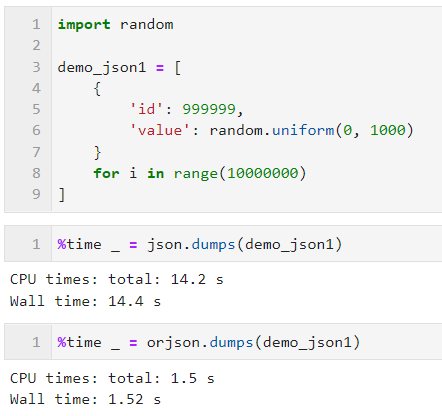
2.2 反序列化
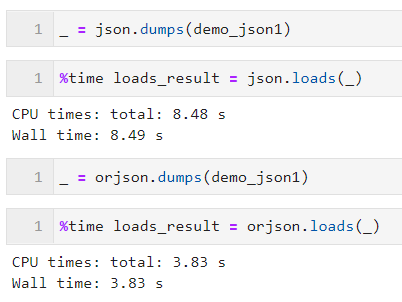
将 JSON 数据转换为 Python 对象的过程我们称之为反序列化,使用 orjson.loads() 进行操作,可接受 bytes 、 str 型等常见类型,在前面例子的基础上我们添加反序列化的例子:
2.3 丰富的option选项
在 orjson 的序列化操作中,可以通过参数 option 来配置诸多额外功能,常用的有:
- OPT_INDENT_2
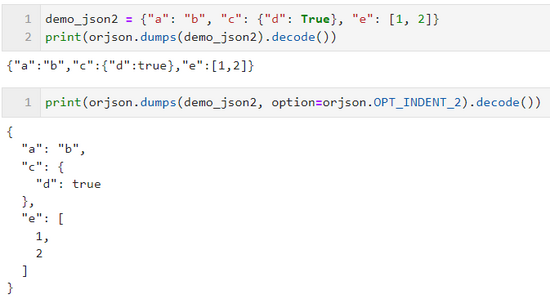
通过配置 option=orjson.OPT_INDENT_2 ,我们可以为序列化后的 JSON 结果添加2个空格的缩进美化效果,从而弥补其没有参数 indent 的不足:
- OPT_OMIT_MICROSECONDS
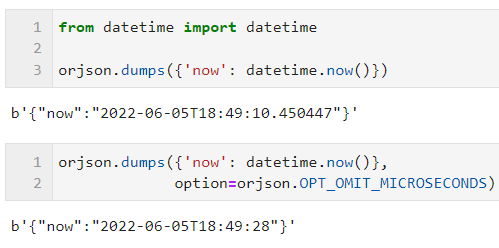
orjson.dumps() 可以直接将 Python 中 datetime 、 time 等标准库中的日期时间对象转换成相应的字符串,这是原生 json 库做不到的,而通过配置 option=orjson.OPT_OMIT_MICROSECONDS ,可以将转换结果后缀的毫秒部分省略掉:
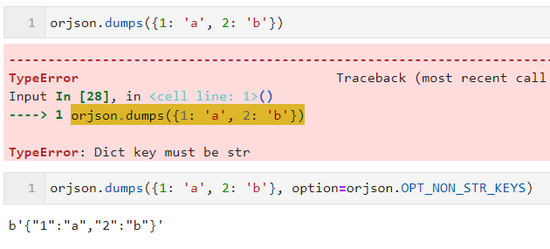
- OPT_NON_STR_KEYS
当需要序列化的对象存在非数值型键时, orjson 默认会抛出 TypeError 错误,这时需要配置 option=orjson.OPT_NON_STR_KEYS 来强制将这些键转换为字符型:
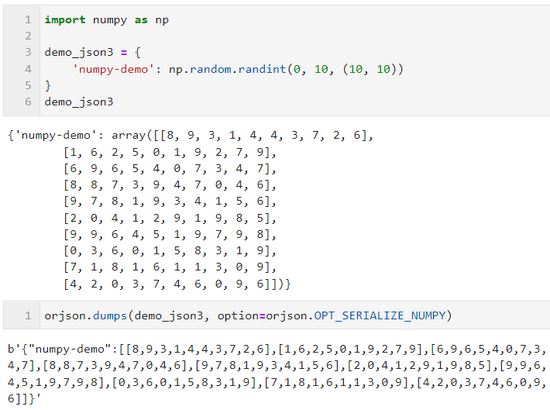
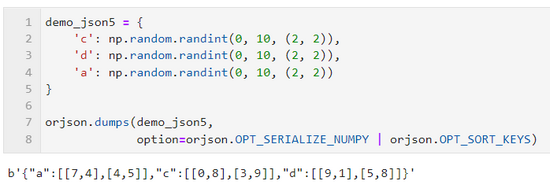
OPT_SERIALIZE_NUMPY
orjson 的一大重要特性是其可以将包含 numpy 中数据结构对象的复杂对象,兼容性地转换为 JSON 中的数组,配合 option=orjson.OPT_SERIALIZE_NUMPY 即可:
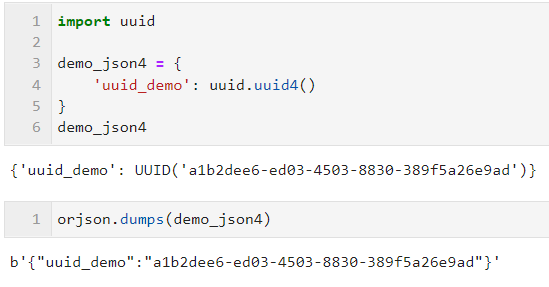
- OPT_SERIALIZE_UUID
除了可以自动序列化 numpy 对象外, orjson 还支持对 UUID 对象进行转换,在 orjson 3.0 之前的版本中,需要配合 option=orjson.OPT_SERIALIZE_UUID ,而本文演示的 3.X 版本则无需额外配置参数:
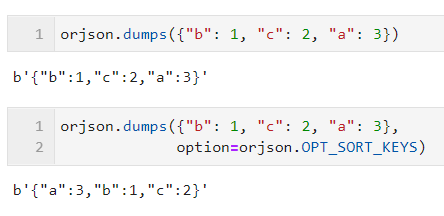
- OPT_SORT_KEYS
通过配合参数 option=orjson.OPT_SORT_KEYS ,可以对序列化后的结果自动按照键进行排序:
- 组合多种option
当你的序列化操作需要涉及多种 option 功能时,则可以使用 | 运算符来组合多个 option 参数即可:
2.4 针对dataclass、datetime添加自定义处理策略
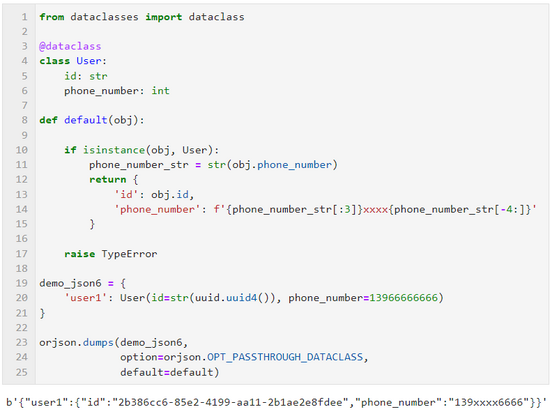
当你需要序列化的对象中涉及到 dataclass 自定义数据结构时,可以配合 orjson.OPT_PASSTHROUGH_DATACLASS ,再通过对 default 参数传入自定义处理函数,来实现更为自由的数据转换逻辑,譬如下面简单的例子中,我们可以利用此特性进行原始数据的脱敏操作:
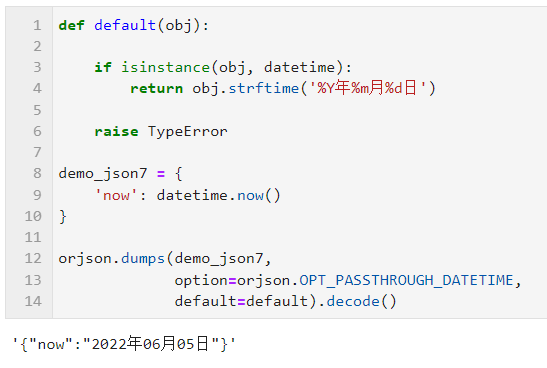
类似的,针对 datetime 类型数据,我们同样可以配合 OPT_PASSTHROUGH_DATETIME 和自定义 default 函数实现日期自定义格式化转换:
总结
到此这篇关于Python中最好用的json库orjson用法的文章就介绍到这了,更多相关Python中json库orjson内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python常用的json标准库
当请求 headers 中,添加一个name为 Accept,值为 application/json 的 header(也即"我"(浏览器)接收的是 json 格式的数据),这样,向服务器请求返回的未必一定是 HTML 页面,也可能是 JSON 文档. 1. 数据交换格式 -- JSON(JavaScript Object Notation) http 1.1 规范 请求一个特殊编码的过程在 http1.1 规范中称为内容协商(content negotiation) JSON 特点
-
Python json解析库jsonpath原理及使用示例
jsonpath jsonpath 用于多层嵌套 json格式的 解析. pip install jsonpath JsonPath 描述 $ 根节点 @ 现行节点 .or[] 取子节点 n/a 取父节点,jsonpath为支持 .. 就是不管位置,选择所有复合条件的条件 * 匹配所有元素节点 n/a 根据属性访问,json不支持,因为json是个key-value递归结构,不需要数属性访问 [] 迭代器标示(可以在里边做简单的迭代操作,如数组下标,根据内容选值等) [,] 支持迭代器中做多选
-

Python中最好用的json库orjson用法详解
目录 1 简介 2 orjson常用方法 2.1 序列化 2.2 反序列化 2.3 丰富的option选项 2.4 针对dataclass.datetime添加自定义处理策略 总结 1 简介 大家好,我们在日常使用 Python 的过程中,经常会使用 json 格式存储一些数据,尤其是在 web 开发中.而 Python 原生的 json 库性能差.功能少,只能堪堪应对简单轻量的 json 数据存储转换需求. 而本文我要给大家介绍的第三方 json 库 orjson ,在公开的各项基准性能测试中
-
对Python中class和instance以及self的用法详解
一. Python 的类和实例 在面向对象中,最重要的概念就是类(class)和实例(instance),类是抽象的模板,而实例是根据类创建出来的一个个具体的 "对象". 就好比,学生是个较为抽象的概念,同时拥有很多属性,可以用一个 Student 类来描述,类中可定义学生的分数.身高等属性,但是没有具体的数值.而实例是类创建的一个个具体的对象, 每一个对象都从类中继承有相同的方法,但是属性值可能不同,如创建一个实例叫 hansry 的学生,其分数为 93,身高为 176,则这个实例拥
-
python Web应用程序测试selenium库使用用法详解
目录 一.声明浏览器对象 二.访问页面并获取网页html 三.查找元素 四.元素交互操作-搜索框传入关键词进行自动搜索 五.交互动作,驱动浏览器进行动作,模拟拖拽动作,将动作附加到动作链中串行执行 六.执行JavaScript 七.获取元素信息 八.Frame操作 九.等待 十一.前进后退-实现浏览器的前进后退以浏览不同的网页 十二.Cookies 十三.异常处理 模拟浏览器进行网页加载,当requests,urllib无法正常获取网页内容的时候 一.声明浏览器对象 注意点一,Python文件名
-
Python中内置的日志模块logging用法详解
logging模块简介 Python的logging模块提供了通用的日志系统,可以方便第三方模块或者是应用使用.这个模块提供不同的日志级别,并可以采用不同的方式记录日志,比如文件,HTTP GET/POST,SMTP,Socket等,甚至可以自己实现具体的日志记录方式. logging模块与log4j的机制是一样的,只是具体的实现细节不同.模块提供logger,handler,filter,formatter. logger:提供日志接口,供应用代码使用.logger最长用的操作有两类:配置和发
-
闭包在python中的应用之translate和maketrans用法详解
相对来说python对字符串的处理是比较高效的,方法也有很多.其中maketrans和translate两个方法被应用的很多,本文就针对这两个方法的用法做一总结整理. 首先让我们先回顾下这两个方法: ① s.translate(table,str) 对字符串s移除str包含的字符,剩下的字符串按照table里的字符映射关系替换.table可以理解为转换表,比较'a' -> 'A', 'b'->'B'. ② tabel = string.maketrans('s1', 's2') s1 和 s2
-
python爬虫---requests库的用法详解
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多 因为是第三方库,所以使用前需要cmd安装 pip install requests 安装完成后import一下,正常则说明可以开始使用了. 基本用法: requests.get()用于请求目标网站,类型是一个HTTPresponse类型 import requests response = requests.get('http://www.baidu.com')print(response.status_c
-
基于python中pygame模块的Linux下安装过程(详解)
一.使用pip安装Python包 大多数较新的Python版本都自带pip,因此首先可检查系统是否已经安装了pip.在Python3中,pip有时被称为pip3. 1.在Linux和OS X系统中检查是否安装了pip 打开一个终端窗口,并执行如下命令: Python2.7中: zhuzhu@zhuzhu-K53SJ:~$ pip --version pip 8.1.1 from /usr/lib/python2.7/dist-packages (python 2.7) Python3.X中: z
-
对python中url参数编码与解码的实例详解
一.简介 在python中url,对于中文等非ascii码字符,需要进行参数的编码与解码. 二.关键代码 1.url编码 对字符串编码用urllib.parse包下的quote(string, safe='/', encoding=None, errors=None)方法. 对json格式的参数名和值编码,用urllib.parse包下的 urlencode(query, doseq=False, safe='', encoding=None, errors=None, quote_via=qu
-
python简单实现最大似然估计&scipy库的使用详解
python简单实现最大似然估计 1.scipy库的安装 wim+R输入cmd,然后cd到python的pip路径,即安装:pip install scipy即可 2.导入scipy库 from scipy.sats import norm 导入scipy.sats中的norm 3.案例分析 from scipy.stats import norm import matplotlib.pyplot as plt import numpy as np ''' norm.cdf 返回对应的累计分布函
-
python中random.randint和random.randrange的区别详解
在python中,通过导入random库,就能使用randint 和 randrange 这两个方法来产生随机整数.那这两个方法的区别在于什么地方呢?让我们一起来看看! 区别: randint 产生的随机数区间是包含左右极限的,也就是说左右都是闭区间的[1, n],能取到1和n.而 randrange 产生的随机数区间只包含左极限,也就是左闭右开的[1, n),1能取到,而n取不到.randint 产生的随机数是在指定的某个区间内的一个值,而 randrange 产生的随机数可以设定一个步长,也