python中multiprosessing模块的Pool类中的apply函数和apply_async函数的区别
目录
- 1、二者的区别
- 2、apply()
- 3、apply_async()
1、二者的区别
apply():
- 非异步(子进程不是同时执行的),堵塞主进程。
- 它的非异步体现在:一个一个按顺序执行子进程, 子进程不是同时执行的。
- 它的堵塞体现在:等到全部子进程都执行完毕后,继续执行apply()后面主进程的代码。
apply_async():
- 异步的,不堵塞主进程。
- 它的异步体现在:子进程之间是同时执行的。子进程被分配到不同的cpu上被执行。
- 它的非堵塞体现在:他不会等待子进程完全执行完毕, 主进程会继续执行, 他会根据系统调度来进行进程之间的切换。如果想堵塞主要进程,需要用.join()函数来堵塞主进程。
2、apply()
import time
import multiprocessing
def doIt(num):
print("Process num is : %s" % num)
time.sleep(1)
print('process %s end' % num)
if __name__ == '__main__':
print('mainProcess start')
#记录一下开始执行的时间
start_time = time.time()
# 创建一个进程池,允许最多可以有3个子进程可以同时执行。
pool = multiprocessing.Pool(3)
print('Child start')
for i in range(3):
pool.apply(doIt,[i])
print('mainProcess done time:%s s' % (time.time() - start_time))
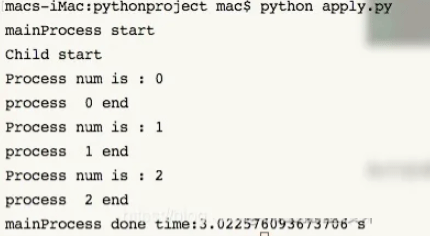
结果如下所示:
从结果中我们可以看到,主进程开始执行之后, 创建的三个子进程也随即开始执行, 后面的主进程被阻塞。而且三个子进程是一个接一个按顺序地执行, 等到子进程全部执行完毕之后, 后面的主进程才会继续执行, 打印出最后一句。所以,apply()函数果然是可以堵塞主进程,而且是非异步的。
3、apply_async()
顾名思义,async就是异步的意思。接下来是使用apply_async(), 只需要把上面的代码使用 apply()的地方改成apply_async() 即可, 代码不再贴上
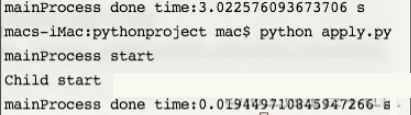
我们来看看运行结果, 可以看出来, 截图的第一句是上一个程序(也就是apply()函数)的执行消耗时间,
最后一句是使用apply_async()所消耗的时间, 在这里, 主进程没有被阻塞, 验证了apply_async()是非阻塞主进程的, 子进程没有执行, 验证了他是根据系统调度完成的,
为什么会这样呢?
原因是, 进程的切换时操作系统控制的, 我们首先运行的是主进程, 而CPU运行得又很快, 快到还没等系统调度到子线程, 主进程就已经运行完毕了, 并且退出程序. 所以子进程就没有运行了.
那么我们在使用apply_async()函数是不是就不能执行子进程呢?肯定可以啊!!!小老弟,想啥呢??还记得join()的作用吗?他可以阻塞主进程, 等待所有子进程结束之后再运行,join()就是告诉主进程老子要运行子进程了,你先等等。
import time
import multiprocessing
def doIt(num):
print("Process num is : %s" % num)
time.sleep(1)
print('process %s end' % num)
if __name__ == '__main__':
print('mainProcess start')
#记录一下开始执行的时间
start_time = time.time()
# 创建一个进程池,最大允许3个子进程同时执行。
pool = multiprocessing.Pool(3)
print('Child start')
for i in range(3):
pool.apply_async(doIt,[i])
pool.close()
pool.join()
print('mainProcess done time:%s s' % (time.time() - start_time))
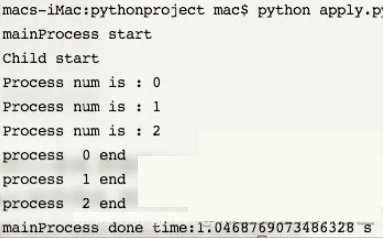
结果如下所示:
我们看看加入这两句的运行结果, 我们可以看到即使是使用了非阻塞主进程的apply_async() 也能让子进程运行完毕之后再执行主进程了。
CPU在执行第一个子进程的时候, 还没等第一个子进程结束, 系统调度到了按顺序调度到了第二个子进程, 以此类推, 一直调度运行子进程, 一个接一个地结束子进程的运行, 最后运行主进程, 而且我们可以看到使用apply_async()的执行效力会更高,看一下他们各自执行结果最后一句的执行消耗时间就知道了, 这也是官方推荐我们使用apply_async()的主要原因吧
到此这篇关于python中multiprosessing模块的Pool()类中的apply()函数和apply_async()函数的区别的文章就介绍到这了,更多相关python multiprosessing内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

分析解决Python中sqlalchemy数据库连接池QueuePool异常
目录 数据库相关错误的解决办法 错误一:数据库连接池超过限制 错误二:数据库事务未回滚 数据库相关错误的解决办法 错误一:数据库连接池超过限制 SqlAlchemy QueuePool limit overflow 造成连接数超过数据库连接池的限制,有两方面的原因,第一个是由于数据库连接池数比较小,因此当连接数稍微增加的时候就会超过限制,另一个原因就是在使用完数据库连接后未能即使释放,最后造成数据连接数持续增加从而超出数据库连接池的限制,所以我们也可以从这两个方面来解决这个问题,但是根本上还是得
-
python线程池 ThreadPoolExecutor 的用法示例
前言 从Python3.2开始,标准库为我们提供了 concurrent.futures 模块,它提供了 ThreadPoolExecutor (线程池)和ProcessPoolExecutor (进程池)两个类. 相比 threading 等模块,该模块通过 submit 返回的是一个 future 对象,它是一个未来可期的对象,通过它可以获悉线程的状态主线程(或进程)中可以获取某一个线程(进程)执行的状态或者某一个任务执行的状态及返回值: 主线程可以获取某一个线程(或者任务的)的状态,以及返
-
解决Python 进程池Pool中一些坑
1 from multiprocessing import Pool,Queue. 其中Queue在Pool中不起作用,具体原因未明. 解决方案: 如果要用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue, 与multiprocessing中的Queue不同 q=Manager().Queue()#Manager中的Queue才能配合Pool po = Pool() # 无穷多进程 2 使用进程池,在进程中调用io读写操作. 例如: p=Pool()
-
python 进程池pool使用详解
和选用线程池来关系多线程类似,当程序中设置到多进程编程时,Python 提供了更好的管理多个进程的方式,就是使用进程池. 在利用 Python 进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间. 当被操作对象数目不大时,可以直接利用 multiprocessing 中的 Process 动态生成多个进程,十几个还好,但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效. Pool可以提供指定数量的进程供用户调用,当
-
python Pool常用函数用法总结
1.说明 apply_async(func[,args[,kwds]):使用非堵塞调用func(并行执行,堵塞方式必须等待上一个过程退出才能执行下一个过程),args是传输给func的参数列表,kwds是传输给func的关键词参数列表. close():关闭Pool,使之不再接受新任务. terminate():无论任务是否完成,都要立即终止. join():主进程堵塞,等待子进程退出,必须在close或terminate之后使用. 2.实例 #coding: utf-8 import mult
-
python3通过gevent.pool限制协程并发数量的实现方法
协程虽然是轻量级的线程,但到达一定数量后,仍然会造成服务器崩溃出错.最好的方法通过限制协程并发数量来解决此类问题. server代码: #!/usr/bin/env python # -*- coding: utf-8 -*- # @Author : Cain # @Email : 771535427@qq.com # @Filename : gevnt_sockserver.py # @Last modified : 2017-11-24 16:31 # @Description : impo
-
python中multiprosessing模块的Pool类中的apply函数和apply_async函数的区别
目录 1.二者的区别 2.apply() 3.apply_async() 1.二者的区别 apply(): 非异步(子进程不是同时执行的),堵塞主进程. 它的非异步体现在:一个一个按顺序执行子进程, 子进程不是同时执行的. 它的堵塞体现在:等到全部子进程都执行完毕后,继续执行apply()后面主进程的代码. apply_async(): 异步的,不堵塞主进程. 它的异步体现在:子进程之间是同时执行的.子进程被分配到不同的cpu上被执行. 它的非堵塞体现在:他不会等待子进程完全执行完毕, 主进程
-
python使用xlrd模块读取xlsx文件中的ip方法
程序中经常需要使用excel文件,批量读取文件中的数据 python读取excel文件可以使用xlrd模块 pip install xlrd安装模块 示例: #coding=utf8 import xlrd from os import path import sys filename='ip.xlsx' if not path.isfile(filename): print "err: not exists or not file ip.xlsx " sys.exit() getfi
-
Python如何获取模块中类以及类的属性方法信息
目录 一.sys.modules模块 二.inspect模块 三.python获取模块中所有类的实例 总结 一.sys.modules模块 sys.modules是一个全局字典,python启动后就将该字典加载在内存中,每当导入新的模块时sys.modules都将记录这些导入模块.字典sys.modules对于加载模块起到了缓冲的作用. sys.modules拥有字典所拥有的一切方法.如: import sys print(sys.modules[__name__]) print(sys.mod
-
Python使用urllib模块对URL网址中的中文编码与解码实例详解
URL网址链接中的中文编码说明 中文的gbk(GB2312)编码: 一个汉字对应两组%xx,即%xx%xx 中文的UTF-8编码: 一个汉字对应三组%xx,即%xx%xx%xx 可以利用百度进行URL编码解码 默认gbk https://www.baidu.com/s?wd=%E4%B8%AD%E5%9B%BD python3编码解码示例 # -*- coding: utf-8 -*- # @File : urldecode_demo.py # @Date : 2018-05-11 from u
-
介绍Ruby中的模块与混合类型的相关知识
模块是组合在一起的方法,类和常量.模块两个主要好处: 模块提供了一个命名空间,并避免名称冲突. 模块实现混合工厂. 模块定义了一个命名空间,一个沙箱中方法和常量可以自由使用,而不必担心踩到其他的方法和常数. 语法: module Identifier statement1 statement2 ........... end 就像被命名为类常量模块中的常量,首字母大写.定义的方法看起来很相似,模块定义方法就像类的方法. 调用一个模块方法和类方法一样,通过模块的名称它名字前,引用一个常数使用该模块
-
Python中time模块与datetime模块在使用中的不同之处
Python 中提供了对时间日期的多种多样的处理方式,主要是在 time 和 datetime 这两个模块里.今天稍微梳理一下这两个模块在使用上的一些区别和联系. time 在 Python 文档里,time是归类在Generic Operating System Services中,换句话说, 它提供的功能是更加接近于操作系统层面的.通读文档可知,time 模块是围绕着 Unix Timestamp 进行的. 该模块主要包括一个类 struct_time,另外其他几个函数及相关常量. 需要注意
-
Python多进程multiprocessing.Pool类详解
multiprocessing模块 multiprocessing包是Python中的多进程管理包.它与 threading.Thread类似,可以利用multiprocessing.Process对象来创建一个进程.该进程可以允许放在Python程序内部编写的函数中.该Process对象与Thread对象的用法相同,拥有is_alive().join([timeout]).run().start().terminate()等方法.属性有:authkey.daemon(要通过start()设置)
-
Node.js中的模块机制学习笔记
Javascript自诞生以来,曾经没有人拿它当做一门编程语言.在Web 1.0时代,这种脚本语言主要被用来做表单验证和网页特效.直到Web 2.0时代,前端工程师利用它大大提升了网页上的用户体验,JS才被广泛重视起来.在JS逐渐流行的过程中,它大致经历了工具类库.组件库.前端框架.前端应用的变迁.Javascript先天就缺乏一项功能:模块,而CommonJS规范的出现则弥补了这一缺陷.本文将介绍CommonJS规范及Node的模块机制. 在其他高级语言中,Java有类文件,Python有im
-
C++ static详解,类中的static用法说明
目录 C++static详解,类中static用法 static特点:用来控制存储方式和可见性 类中的static关键字 什么时候用static? 为什么要引入static? c++中static总结 1. 概念 2. 面向过程的static 3. 面向对象中的static 4. 小结 C++static详解,类中static用法 static特点:用来控制存储方式和可见性 ① 存储空间:静态存储区(控制变量的存储方式) 静态变量存储在静态存储区(存储在静态存储区的变量,如果不显式地对其进行初始
-
结合.net框架在C#派生类中触发基类事件及实现接口事件
在派生类中引发基类事件 以下简单示例演示了在基类中声明可从派生类引发的事件的标准方法.此模式广泛应用于 .NET Framework 类库中的 Windows 窗体类. 在创建可用作其他类的基类的类时,应考虑如下事实:事件是特殊类型的委托,只可以从声明它们的类中调用.派生类无法直接调用基类中声明的事件.尽管有时需要事件仅由基类引发,但在大多数情形下,应该允许派生类调用基类事件.为此,您可以在包含该事件的基类中创建一个受保护的调用方法.通过调用或重写此调用方法,派生类便可以间接调用该事件. 注意: