python爬虫把url链接编码成gbk2312格式过程解析
1. 问题 抓取某个网站,发现请求参数是乱码格式,
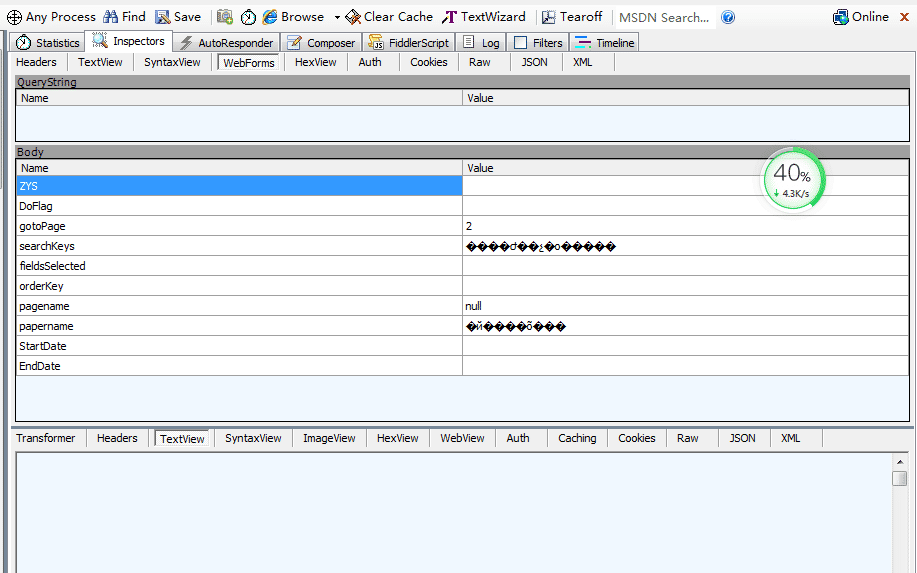
这是点击 TextView,发现请求参数如下图所示
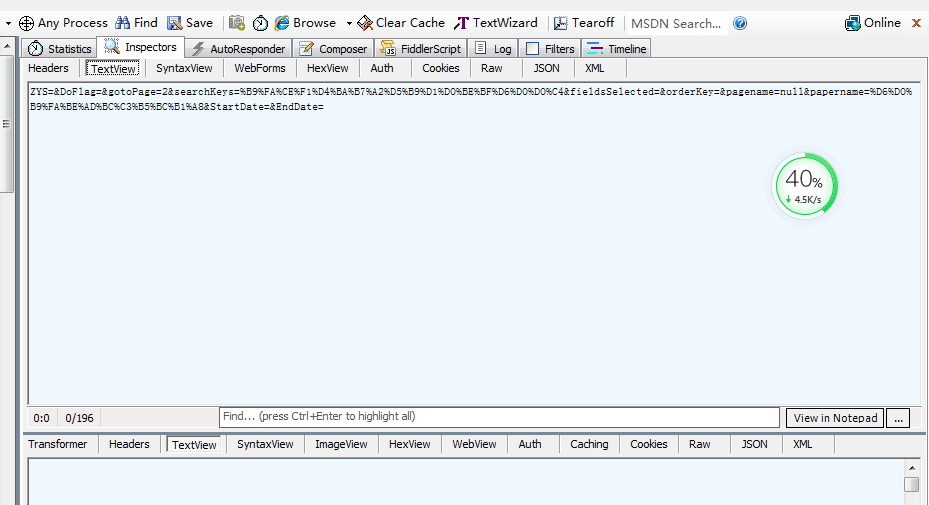
3. 那么=%B9%FA%CE%F1%D4%BA%B7%A2%D5%B9%D1%D0%BE%BF%D6%D0%D0%C4是什么东西啊
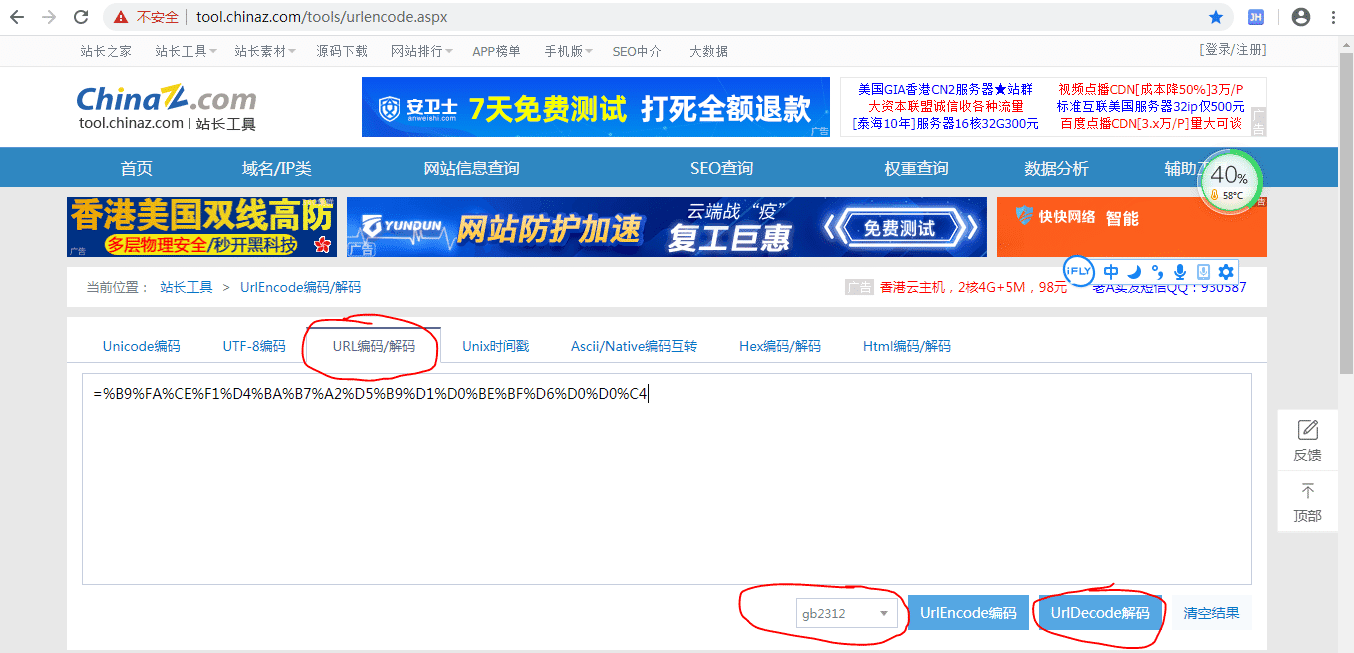
解码后是 =国务院发展研究中心
代码实现:
content = "我爱中国"
import urllib
res = urllib.quote(content.encode('gb2312'))
print res
print "11111111", type(res)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
为什么说python适合写爬虫
抓取网页本身的接口 相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API.(当然ruby也是很好的选择) 此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的.这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆.模拟session/cookie的存储和设置.在python里都有非常优秀的第三方包帮你搞
-
python爬虫容易学吗
随着大数据时代的到来,数据将如同煤电气油一样,成为我们最重要的能源之一,然而这种能源是可以源源不断产生.可再生的.而Python爬虫作为获取数据的关键一环,在大数据时代有着极为重要的作用.于是许多同学就前来咨询:Python爬虫好学吗? 什么是爬虫? 网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本. 数据从何而来? 要想学Python首先请问:我们所爬的数据,是从哪里来的呢? 企业产生的用户数据:百度指数.阿里指数.TBI腾讯浏览指数.新浪微博指
-
Python selenium爬虫实现定时任务过程解析
现在需要启动一个selenium的爬虫,使用火狐驱动+多线程,大家都明白的,现在电脑管家显示CPU占用率20%,启动selenium后不停的开启浏览器+多线程, 好,没过5分钟,CPU占用率直接拉到90%+,电脑卡到飞起,定时程序虽然还在运行,但是已经类似于待机状态, 是不是突然感觉到面对电脑卡死,第一反应:卧槽,这个lj电脑,这么程序都跑不起来,我还写这么多代码,*****!! 是吧,接下来上代码,具体功能,请自信查阅相关资料深造: from datetime import datetime
-
Python while true实现爬虫定时任务
记得以前的windows 任务定时是可以的正常使用的,今天试了下,发现不能正常使用了,任务计划总是挂起. 接下来记录下python 爬虫定时任务的几种解决方法. 今天是第一篇,后面会陆续更新. 首先最容易的是while true死循环挂起,上代码 import osimport timeimport sysfrom datetime import datetime, timedelta def One_Plan(): # 设置启动周期 Second_update_time = 24 * 60 *
-
python爬虫可以爬什么
Python爬虫可以爬取的东西有很多,Python爬虫怎么学?简单的分析下: 如果你仔细观察,就不难发现,懂爬虫.学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单.容易上手. 利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如: 知乎:爬取优质答案,为你筛选出各话题下最优质的内容. 淘宝.京东:抓取商品.评论及销量数据,对各种商品及用户的消费场景进行分析. 安居客.链家:抓取房产买卖
-
Python使用Chrome插件实现爬虫过程图解
做电商时,消费者对商品的评论是很重要的,但是不会写代码怎么办?这里有个Chrome插件可以做到简单的数据爬取,一句代码都不用写.下面给大家展示部分抓取后的数据: 可以看到,抓取的地址,评论人,评论内容,时间,产品颜色都已经抓取下来了.那么,爬取这些数据需要哪些工具呢?就两个: 1. Chrome浏览器: 2. 插件:Web Scraper 插件下载地址:https://chromecj.com/productivity/2018-05/942.html 最后,如果你想自己动手抓取一下,这里是这次
-
python爬虫把url链接编码成gbk2312格式过程解析
1. 问题 抓取某个网站,发现请求参数是乱码格式, 这是点击 TextView,发现请求参数如下图所示 3. 那么=%B9%FA%CE%F1%D4%BA%B7%A2%D5%B9%D1%D0%BE%BF%D6%D0%D0%C4是什么东西啊 解码后是 =国务院发展研究中心 代码实现: content = "我爱中国" import urllib res = urllib.quote(content.encode('gb2312')) print res print "111111
-
python爬虫模块URL管理器模块用法解析
这篇文章主要介绍了python爬虫模块URL管理器模块用法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 URL管理器模块 一般是用来维护爬取的url和未爬取的url已经新添加的url的,如果队列中已经存在了当前爬取的url了就不需要再重复爬取了,另外防止造成一个死循环.举个例子 我爬www.baidu.com 其中我抓取的列表中有music.baidu.om,然后我再继续抓取该页面的所有链接,但是其中含有www.baidu.com,可以想
-

python爬虫中url管理器去重操作实例
当我们需要有一批货物需要存放时,最好的方法就是有一个仓库进行保管.我们可以把URL管理器看成一个收集了数据的大仓库,而下载器就是这个仓库货物的搬运者.关于下载器的问题,我们暂且不谈.本篇主要讨论的是在url管理器中,我们遇到重复的数据应该如何识别出来,避免像仓库一样过多的囤积相同的货物.听起来是不是很有意思,下面我们一起进入今天的学习. URL管理器到底应该具有哪些功能? URL下载器应该包含两个仓库,分别存放没有爬取过的链接和已经爬取过的链接. 应该有一些函数负责往上述两个仓库里添加链接 应该
-
python打包成so文件过程解析
这篇文章主要介绍了python打包成so文件过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 wget https://bootstrap.pypa.io/get-pip.py python get-pip.py pip install cython 编写setput.py文件: setup.py文件内容如下: from distutils.core import setup from distutils.extension import
-
python pcm音频添加头转成Wav格式文件的方法
如下所示: ''''' add Head Infomation for pcm file ''' import sys import struct import os __author__ = 'bob_hu, hewitt924@gmail.com' __date__ = 'Dec 19,2011' __update__ = 'Dec 19,2011' def geneHeadInfo(sampleRate,bits,sampleNum): ''''' 生成头信息,需要采样率,每个采样的位数,
-
Python操作Sonqube API获取检测结果并打印过程解析
这篇文章主要介绍了Python操作Sonqube API获取检测结果并打印过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.需求:每次Sonqube检查完毕后,需要登陆才能看到结果无法通过Jenkins发布后直接看到bug 及漏洞数量. 2.demo:发布后,可以将该项目的检测结果简单打印出来显示,后面还可以集成钉钉发送到群里. # -*- coding: UTF-8 -*- import sys reload(sys) sys.se
-
python爬虫爬取笔趣网小说网站过程图解
首先:文章用到的解析库介绍 BeautifulSoup: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能. 它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序. Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码. 你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了.然后,你仅仅
-
Python爬虫图片懒加载技术 selenium和PhantomJS解析
一.什么是图片懒加载? - 案例分析:抓取站长素材http://sc.chinaz.com/中的图片数据 #!/usr/bin/env python # -*- coding:utf-8 -*- import requests from lxml import etree if __name__ == "__main__": url = 'http://sc.chinaz.com/tupian/gudianmeinvtupian.html' headers = { 'User-Agen
-
python heic后缀图片文件转换成jpg格式的操作
我就废话不多说了,直接上代码 heic_to_jpg.py import subprocess import os import io import whatimage import pyheif import traceback from PIL import Image def decodeImage(bytesIo): try: fmt = whatimage.identify_image(bytesIo) # print('fmt = ', fmt) if fmt in ['heic']
-
asp.net下URL网址重写成.html格式、RSS、OPML的知识总结
一.URL网址重写1.在MSDN中下载一个文件,将ActionlessForm.dll和URLRewriter.dll放到bin目录下.这是MSDN中关于URL重写的一篇文章里的地址.在 ASP.NET 中执行 URL 重写2.将web.config文件中添加下面的代码 <!-- 自定义配置节 --> <configSections> <section name="RewriterConfig" type="URLRewriter.Conf