Python实现读取并写入Excel文件过程解析
需求是有两个Excel文件:1.xlsx,2.xlsx,比较2.xlsx中的A,B列和1.xlsx中的A,B列;查找1.xlsx中存在,2.xlsx中不存在的行数据,输出到result.xlsx文件中
1.xlsx内容如下
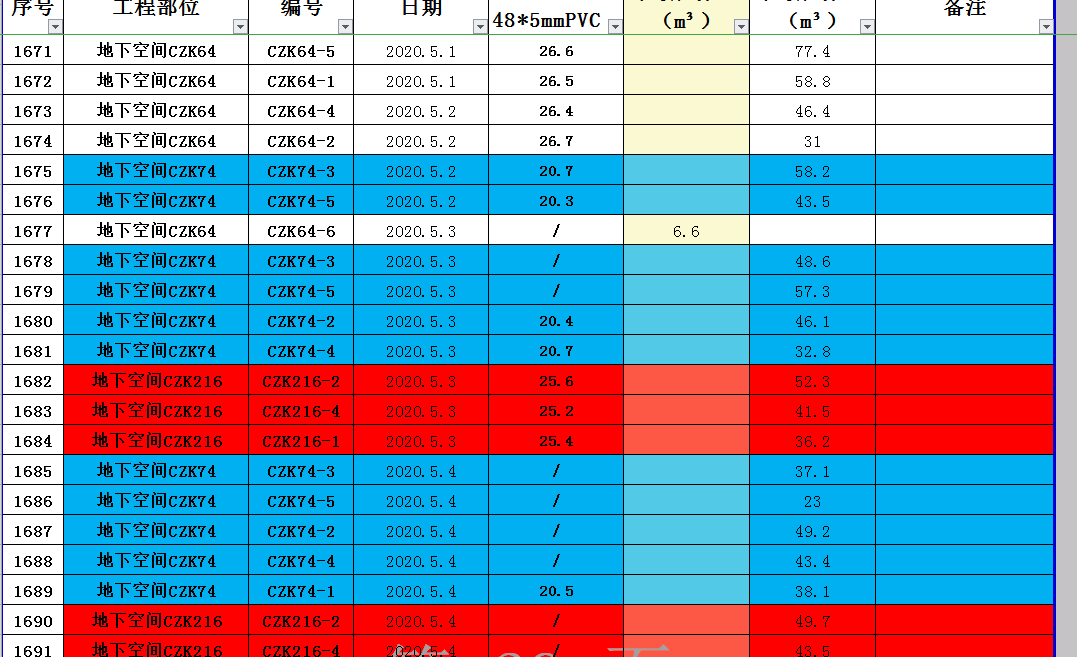
2.xlsx内容如下

上代码
# coding=utf-8
import xlrd
import xlwt
# 打开文件
#data = xlrd.open_workbook('./附件7:溶洞钻孔、埋管、注浆.xlsx')
# 查看工作表
#data.sheet_names()
#print("sheets:" + str(data.sheet_names()))
# 通过文件名获得工作表,获取工作表1
#table = data.sheet_by_name('20200404')
# 打印data.sheet_names()可发现,返回的值为一个列表,通过对列表索引操作获得工作表1
# table = data.sheet_by_index(0)
# 获取行数和列数
# 行数:table.nrows
# 列数:table.ncols
#print("总行数:" + str(table.nrows))
#print("总列数:" + str(table.ncols))
# 获取整行的值 和整列的值,返回的结果为数组
# 整行值:table.row_values(start,end)
# 整列值:table.col_values(start,end)
# 参数 start 为从第几个开始打印,
# end为打印到那个位置结束,默认为none
#print("整行值:" + str(table.row_values(0)))
#print("整列值:" + str(table.col_values(1)))
# 获取某个单元格的值,例如获取B3单元格值
#cel_B3 = table.cell(3,2).value
#print("第三行第二列的值:" + cel_B3)
def read_xlrd(excelFile,tablename):
data = xlrd.open_workbook(excelFile)
#table = data.sheet_by_index(0)
table = data.sheet_by_name(tablename)
print("总行数:" + str(table.nrows))
print("总列数:" + str(table.ncols))
dataFile = []
for rowNum in range(table.nrows):
# if 去掉表头
if rowNum > 0:
dataFile.append(table.row_values(rowNum))
return dataFile
workbook = xlwt.Workbook(encoding = 'ascii')
worksheet = workbook.add_sheet('sheet1')
def writeLine(row ,line):
col=0
while col <len(line):
worksheet.write(row,col, line[col])
col+=1
filename1='./附件7:溶洞钻孔、埋管、注浆.xlsx'
data1=read_xlrd(filename1,'20200404')
filename2='./设计之都溶洞注浆台账.xlsx'
data2=read_xlrd(filename2,'Sheet1')
data=[]
for row in data1[4:]:
#print(row[0],row[1])
data.append([row[0],row[1]])
#print(data)
result=[]
i=0
for row in data2[1:]:
buf=[row[1],row[2]]
if buf not in data:
print(row,'不存在')
writeLine(i, row)
i+=1
workbook.save('result.xlsx')
之后生成结果result.xlsx文件

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python保留格式汇总各部门excel内容的实现思路
使用pthon汇总各部门的excel内容,主要思路: 1.使用pandas读入汇总表(b3df)和其中一个部门的表格内容(dedf) 2.填充pandas空值,使'项目名称','主管部门'列没有空值 3.使用xlwings打开汇总表(b3ws)和部门表(dews) 4.用b3df.dedf对比两个表中项目的行数是否一样,不一样则在汇总表(b3ws)插入行,使汇总表和部门表格(dews)一致 5.复制部门表格(dews)内容到汇总表(b3ws) 6.保存退出 汇总表格如下: 汇总A.B.C.D部门
-
python使用openpyxl操作excel的方法步骤
一 前言 知识追寻者又要放大招了,学完这篇openpyxl第三方库,读者将会懂得如何灵活的读取excel数据,如何创建excel工作表:更新工作表,删除工作表:是不是感觉很强大,留下赞赞吧!! 二 openpyxl常用属性函数 常用函数或者属性 说明 openpyxl.load_workbook() 加载excel工作本 Workbook.active 获得默认sheet Workbook.create_sheet() 创建sheet Workbook.get_sheet_names() 已过时
-
如何用python处理excel表格
openpyxl是一个第三方库,可以处理xlsx格式的Excel文件.pip install openpyxl安装. 读取Excel文件 需要导入相关函数 from openpyxl import load_workbook # 默认可读写,若有需要可以指定write_only和read_only为True wb = load_workbook('pythontab.xlsx') 默认打开的文件为可读写,若有需要可以指定参数read_only为True. 获取工作表--Sheet # 获得所有s
-
python不到50行代码完成了多张excel合并的实现示例
一 前言 公司同事最近在做excel相关的工作:今天来求助知识追寻者合并多个excel为一个一个工作本,原本是java操作poi太蛋疼了,笨重不堪,内存消耗严重,知识追寻者使用python不到40行代码完成了60多张excel工作本合并为一张:python真香 牛皮吹完了,如果看过知识追寻者系列文章的读者肯定知道之前知识追寻者发过一篇 python专题使用openpyxl操作excel:本篇使用的不是openpyx库,使用的使是xlrd,xlwt库,虽然这两库功能没法根openpyx相比,但可以
-
Python3读取和写入excel表格数据的示例代码
python操作excel主要用到 xlrd 和 xlwt 这两个库,xlrd读取excel表格数据, 支持 xlsx和xls格式的excel表格 :xlwt写入excel表格数据: 一.python读取excel表格数据 1.读取excel表格数据常用操作 import xlrd # 打开excel表格 data_excel=xlrd.open_workbook('data/dataset.xlsx') # 获取所有sheet名称 names=data_excel.sheet_names()
-
Python导入数值型Excel数据并生成矩阵操作
riginal_Data 因为程序是为了实现对纯数值型Excel文档进行导入并生成矩阵,因此有必要对第五列文本值进行删除处理. Import_Data import numpy as np import xlrd def import_excel_matrix(path): table = xlrd.open_workbook(path).sheets()[0] # 获取第一个sheet表 row = table.nrows # 行数 col = table.ncols # 列数 datamat
-
Python实现读取并写入Excel文件过程解析
需求是有两个Excel文件:1.xlsx,2.xlsx,比较2.xlsx中的A,B列和1.xlsx中的A,B列:查找1.xlsx中存在,2.xlsx中不存在的行数据,输出到result.xlsx文件中 1.xlsx内容如下 2.xlsx内容如下 上代码 # coding=utf-8 import xlrd import xlwt # 打开文件 #data = xlrd.open_workbook('./附件7:溶洞钻孔.埋管.注浆.xlsx') # 查看工作表 #data.sheet_names
-

python 字典有序并写入json文件过程解析
大致流程: 导包---import collections 新建一个有序字典---collections.OrderedDict() 写入json文件 代码: import collections real_result = collections.OrderedDict() real_result["target"] = "total_result" real_result["key1"] = "value1" real_r
-
Python实现读取及写入csv文件的方法示例
本文实例讲述了Python实现读取及写入csv文件的方法.分享给大家供大家参考,具体如下: 新建csvData.csv文件,数据如下: 具体代码如下: # coding:utf-8 import csv # 读取csv文件方式1 csvFile = open("csvData.csv", "r") reader = csv.reader(csvFile) # 返回的是迭代类型 data = [] for item in reader: print(item) dat
-
通过openpyxl读取excel文件过程解析
这篇文章主要介绍了通过openpyxl读取excel文件过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.环境准备 python3环境.安装openpyxl模块 2.excel文件数据准备 3.为方便直接调用,本代码直接封装成类 from openpyxl import load_workbook class DoExcel: def __init__(self,filename): ''' :param filename: exce
-
在python中读取和写入CSV文件详情
目录 前言 1.导入CSV库 2.对CSV文件进行读写 2.1 用列表形式写入CSV文件 2.2 用列表形式读取CSV文件 2.3 用字典形式写入csv文件 2.4 用字典形式读取csv文件 结语 前言 CSV(Comma-Separated Values)即逗号分隔值,一种以逗号分隔按行存储的文本文件,所有的值都表现为字符串类型(注意:数字为字符串类型).如果CSV中有中文,应以utf-8编码读写. 1.导入CSV库 python中对csv文件有自带的库可以使用,当我们要对csv文件进行读写的
-
PYTHON如何读取和写入EXCEL里面的数据
好久没写了,今天来说说python读取excel的常见方法.首先需要用到xlrd模块,pip install xlrd 安装模块. 首先打开excel文件: xl = xlrd.open_workbook(r'D:\file\data.xlsx') 传文件路径 通过索引获取要操作的工作表 table = xl.sheets()[0] 有些人不知道啥是工作表,下图这个: 获取第一行的内容,索引从0开始 row = table.row_values(0) 获取第一列的整列的内容 col = tabl
-
JAVA使用POI(XSSFWORKBOOK)读取EXCEL文件过程解析
经过一番搜索发现,java操纵excel文件常用的有jxl和poi两种方式,孰好孰坏看自己需求而定. 其中最主要的区别在于jxl不支持.xlsx,而poi支持.xlsx 这里介绍的使用poi方式(XSSFWorkbook),实际上poi提供了HSSFWorkbook和XSSFWorkbook两个实现类.区别在于HSSFWorkbook是针对.xls文件,XSSFWorkbook是针对.xslx文件. 首先明确一下基本概念: 先创建一个工作簿,一个工作簿可以有多个工作表,一个工作表可以有多个行,一
-
Python openpyxl读取单元格字体颜色过程解析
问题 我试图打印some_cell.font.color.rgb并得到各种结果. 对于一些人,我得到了我想要的东西(比如" FF000000"),但对于其他人,它给了我Value must be type 'basetring'.我假设后者是因为我实际上没有为这些单元格定义字体颜色. 我正在使用openpyxl 2.2.2 解决方案 我认为这是openpyxl中的一个错误,我认为你应该在这里报告. 调试以下代码(当然使用trepan3k): from openpyxl import W
-
基于python requests selenium爬取excel vba过程解析
目的:基于办公与互联网隔离,自带的office软件没有带本地帮助工具,因此在写vba程序时比较不方便(后来发现07有自带,心中吐血,瞎折腾些什么).所以想到通过爬虫在官方摘录下来作为参考. 目标网站:https://docs.microsoft.com/zh-cn/office/vba/api/overview/ 所使工具: python3.7,requests.selenium库 前端方面:使用了jquery.jstree(用于方便的制作无限层级菜单 设计思路: 1.分析目标页面,可分出两部分
-
Python使用jupyter notebook查看ipynb文件过程解析
首先确保已安装jupyter notebook,而且添加到了环境变量 再找到保存ipynb文件的文件夹,在路径处直接输入cmd,然后回车 进入命令行窗口后,输入jupyter lab 然后浏览器就会打开 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们.